ATM
Message boards :
News :
ATM
Message board moderation
Previous · 1 . . . 16 · 17 · 18 · 19 · 20 · 21 · 22 . . . 35 · Next
| Author | Message |
|---|---|
|
Send message Joined: 21 Feb 20 Posts: 1117 Credit: 40,876,970,595 RAC: 0 Level Scientific publications |
If it hurts when you <do that> then the most obvious solution is to not <do that>. This applies to most things in life. It’s well known that these tasks do not like to be interrupted. If your power grid is that unstable then it’s probably best for you to crunch something else, or invest in a battery backup to keep the computer running during power outages. These are still classified as Beta after all and that comes with the implication that things will not always work, and you need to accept whatever compromises that comes with it. If you don’t then your other solution could be to just disable Beta processing from your profile and wait for ACEMD3 work. 
|
|
Send message Joined: 28 Feb 23 Posts: 35 Credit: 0 RAC: 0 Level Scientific publications |
Ok, back from holidays. I've saw that in the last batch of jobs many Energy NaN errors were happening, which it was completely unexpected. I am testing some different settings internally to see if it overcomes this issue. In case it is successfull, new jobs would be send by tomorrow/Friday. This might be more time consuming and I would not like to split them in even more chunks (might have a suspicion that this gives wonky results at some point) but if people see that they take too long time/space please let me know. |
|
Send message Joined: 28 Feb 23 Posts: 35 Credit: 0 RAC: 0 Level Scientific publications |
It does not make any difference to Quico. The task will be completed on one or another computer and his science is done. It is our very expensive energy that is wasted but as Quico himself said, the science gets done who cares about wasted energy? I'm pretty sure I never said that about wasted energy. What I might have mentioned is that completed jobs come back to me and since I don't check what happens to every WU manually then these crashes might go under my radar. As Ian&Steve C. these app is in "beta"/not ideal conditions. Sadly I don't have the knowledge to fix it, otherwise I would. Errors on my end can be one I forget to upload some files (happened) or I sent jobs without equilibrated systems (also happened). By trial and error I ended up with a workflow that should avoid these issues 99% of the time. Any other kind of errors I can pass them to the devs but I can't promise much more apart from it. I'm here testing the science. |
 ServicEnginIC ServicEnginICSend message Joined: 24 Sep 10 Posts: 595 Credit: 13,083,686,510 RAC: 10,553 Level Scientific publications |
This might be more time consuming and I would not like to split them in even more chunks (might have a suspicion that this gives wonky results at some point) but if people see that they take too long time/space please let me know. I think that the most harmful risk is that excessively heavy tasks generate result files bigger than 512 MB in size. GPUGRID server can't handle them, and they won't upload... |
|
Send message Joined: 13 Dec 17 Posts: 1424 Credit: 9,189,946,190 RAC: 0 Level Scientific publications |
Absolutely, this is the biggest risk. Shame that you can't get Gianni or Toni to reconfigure the website html upload size limit to 1GB. |
|
Send message Joined: 13 Apr 15 Posts: 11 Credit: 3,003,712,606 RAC: 0 Level Scientific publications |
Can you at least fix the "daily quota" limit or whatever it is that prevents a machine from getting more WUs? 8/17/2023 10:25:12 AM | GPUGRID | This computer has finished a daily quota of 14 tasks After all, it is your WUs that are Erroring out by the hundreds and causing this "daily quota" to kick in. Seems this batch is even worse than before. |
|
Send message Joined: 11 Jul 09 Posts: 1639 Credit: 10,159,968,649 RAC: 0 Level Scientific publications |
The tasks I received this morning are running fine, and have reached 92%. Any problems will be the result of the combination of their tasks and your computer. The quota is there to protect their science from your computer. Trying to increase the quota without sorting out the cause of the underlying problem would be counter-productive. |
|
Send message Joined: 21 Feb 20 Posts: 1117 Credit: 40,876,970,595 RAC: 0 Level Scientific publications |
It seems windows hosts in general seem to have a lot more problems than Linux hosts.
|
|
Send message Joined: 11 Jul 09 Posts: 1639 Credit: 10,159,968,649 RAC: 0 Level Scientific publications |
It seems windows hosts in general seem to have a lot more problems than Linux hosts. Depends what the error is. I looked at host 553738: Coprocessors [4] NVIDIA NVIDIA GeForce RTX 2080 Ti (11263MB) driver: 528.2 and tasks with openmm.OpenMMException: Illegal value for DeviceIndex: 1 BOINC has a well-known design flaw: it reports a number of identical GPUs, even if in reality they're different. And this project's apps are very picky about being told exactly what sort of GPU they've been told to run on. So, if Device_0 is a RTX 2080 Ti, and Device_1 isn't, you'll get an error like that. The machine has completed other tasks today, presumably on Device 0, although the project doesn't report that for a successful task. |
|
Send message Joined: 21 Feb 20 Posts: 1117 Credit: 40,876,970,595 RAC: 0 Level Scientific publications |
Just anecdotally, most issues reported seem to be coming from windows users with ATMbeta.
|
|
Send message Joined: 11 May 10 Posts: 68 Credit: 13,357,003,875 RAC: 9,425 Level Scientific publications |
Most of the errors so far have occurred on the otherwise reliable Linux machine. Since the app version is still 1.09, I had little hope that the 4080 would work on Windows this time - and rightly so. When an OS-hardware combination works flawlessly on all other BOINC projects, it is not very far-fetched to suspect that the app is buggy when there are errors on GPUGrid. I hope that the developers can look deeply into it again. |
|
Send message Joined: 18 Mar 10 Posts: 28 Credit: 43,098,337,419 RAC: 9,190 Level Scientific publications |
I have 11 valid and 3 error so far for this batch of tasks. I am getting the "raise ValueError('Energy is NaN." error. This is for Ubuntu 22.04 and single GPU or 2 identical GPU systems. What really hurts is the tasks are running a long time and then the error comes. |
|
Send message Joined: 2 Jul 16 Posts: 339 Credit: 8,281,341,558 RAC: 2,803 Level Scientific publications |
I completed my first of these longer tasks in Win10. Sometimes this PC completes tasks failed by others and the opposite also happens. This one failed 3x by the same person on different PCs, then a 4th fail by someone. All 4 PCs with over 100 fails in 1-2 min. Seems these users are getting plenty past 14 per day. https://www.gpugrid.net/workunit.php?wuid=27541862 |
|
Send message Joined: 11 Jul 09 Posts: 1639 Credit: 10,159,968,649 RAC: 0 Level Scientific publications |
This is a new one on me: task 33579127 openmm.OpenMMException: Called setPositions() on a Context with the wrong number of positions |
|
Send message Joined: 1 Jan 15 Posts: 1171 Credit: 12,662,148,501 RAC: 3,588 Level Scientific publications |
one strange thing I noticed when I re-started downloading and crunching tasks on 2 PCs yesterday evening: one of the two PCs got a new 6-digit number in the GPUGRID system. It's now 610779, before it was 600874. No big deal, but I am wondering how come. Does anyone have a logical explanation? |
|
Send message Joined: 13 Dec 17 Posts: 1424 Credit: 9,189,946,190 RAC: 0 Level Scientific publications |
BOINC thought it was a new host. Could be many reasons. Scheduler database issues, corruption of or missing client_state.xml file, change in hardware or OS etc. etc. All it takes is the server to lose track of how many times the host has contacted the project and the server will reissue a new host ID. |
|
ServicEnginIC Send message Joined: 24 Sep 10 Posts: 595 Credit: 13,083,686,510 RAC: 10,553 Level Scientific publications |
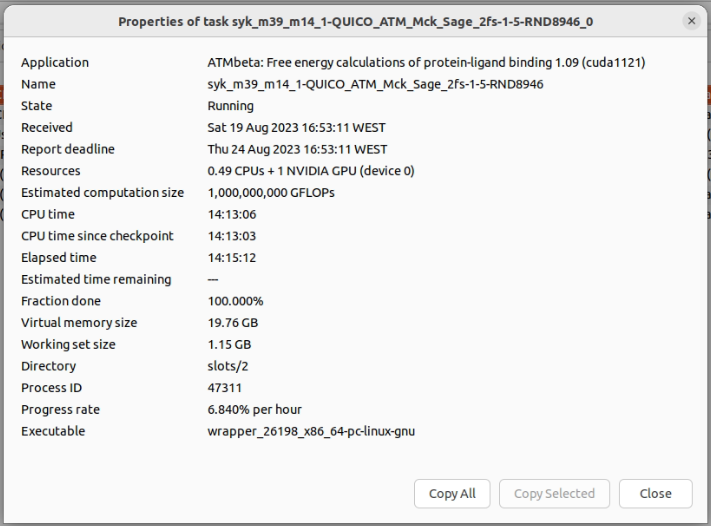
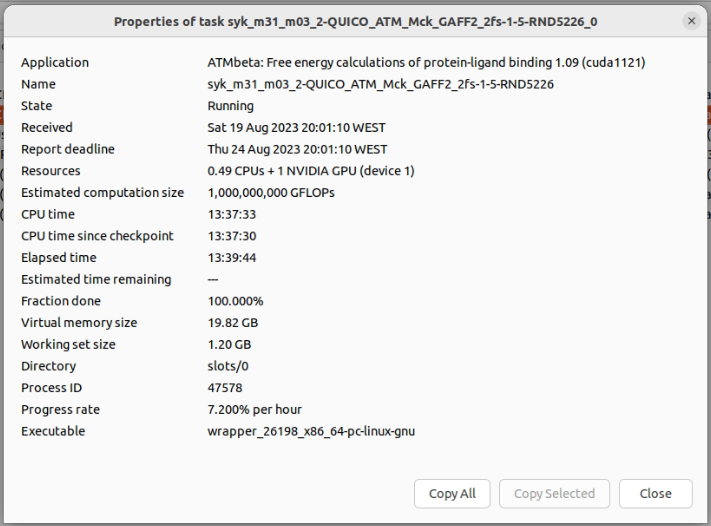
I think that the most harmful risk is that excessively heavy tasks generate result files bigger than 512 MB in size. I see that one of the issues that Quico seems to have addressed is just this one. At this two GTX1650 GPU host, I was processing these two tasks: syk_m39_m14_1-QUICO_ATM_Mck_Sage_2fs-1-5-RND8946_0, with this characteristics: syk_m31_m03_2-QUICO_ATM_Mck_GAFF2_2fs-1-5-RND5226_0, with this characteristics To test the sizes of the generated result files, I suspended network activity at BOINC Manager. And now there are two only result files per task, both being much lighter than previous batches. Excessively heavy result files problem solved, and by the way, less stress for server storage. |
|
Send message Joined: 11 Jul 09 Posts: 1639 Credit: 10,159,968,649 RAC: 0 Level Scientific publications |
Yes, I saw that and it looks like good news. But, I would say, unproven as yet. This new batch have varying run times, according to what gene or protein is being worked on - the first part of the name, anyway. The longest ones seem to be shp2_, but even those finish in under 12 hours on my cards. I think the really massive 500MB+ tasks ran over 24 hours on the same cards, so we haven't really tested the limits yet. |
|
Send message Joined: 9 Jun 10 Posts: 19 Credit: 2,233,932,323 RAC: 0 Level Scientific publications |
I am a bit curious what's going on with this 1660 super host. I occasionally check the error out units to make sure it's not just always failing on my hosts and I noticed more than once some host would finish it super fast. It happened to some of my own valid WUs too. While this sometimes happens, what I haven't seen until now is a host that either errors out, or finishes super fast: https://www.gpugrid.net/results.php?hostid=610334 What makes a WU finish super fast when other computers error out? Are these fast completion actually valid results? 
|
|
Send message Joined: 13 Apr 15 Posts: 11 Credit: 3,003,712,606 RAC: 0 Level Scientific publications |
What's with the new error/issue... 8/22/2023 12:49:47 PM | GPUGRID | Output file syk_m12_m14_3-QUICO_ATM_Mck_Sage_v3-1-5-RND3920_0_0 for task syk_m12_m14_3-QUICO_ATM_Mck_Sage_v3-1-5-RND3920_0 absent Of course, may not ne new...I just saw it in my log after having a string of errors. |
{kind=link}
{kind=link}
{kind=link}
{kind=link}

©2026 Universitat Pompeu Fabra