Update acemd3 app
Message boards :
News :
Update acemd3 app
Message board moderation
Previous · 1 · 2 · 3 · 4 · 5 · 6 · 7 . . . 9 · Next
| Author | Message |
|---|---|
|
Send message Joined: 12 Jul 17 Posts: 404 Credit: 17,412,649,587 RAC: 4,966 Level Scientific publications |
Yea, snagged a WU and it's running. My guesstimate is 19:44:13 on my 3080 dialed down to 230 Watts. Record breaking long heat wave here and summer peak Time-of-Use electric rates (8.5x higher) have started. Summer is not BOINC season in The Great Basin. Rxn time, now that makes sense. Thx. Linux Mint repository offers 465.31 and 460.84. Is it actually worth reverting to 460.84??? I wouldn't do it until after this WU completes anyway. |
|
Send message Joined: 21 Feb 20 Posts: 1117 Credit: 40,876,970,595 RAC: 1 Level Scientific publications |
Linux Mint repository offers 465.31 and 460.84. Is it actually worth reverting to 460.84??? I wouldn't do it until after this WU completes anyway. probably wont matter if the driver you have is working. i don't expect any performance difference between the two. I was just saying that I would use a more recent non-beta driver if i was updating, unless you need some feature in 465 branch specifically. 
|
|
Send message Joined: 21 Feb 20 Posts: 1117 Credit: 40,876,970,595 RAC: 1 Level Scientific publications |
|
|
Send message Joined: 6 Jan 15 Posts: 76 Credit: 25,499,534,331 RAC: 0 Level Scientific publications |
peak 28,9°C here today so suspend during daytime after 2 task done. I run evening and night these days if temp i high. Ambient temp was above 35 inside and fan gone up to 80% on gpu i checked. So i manage to go to 460.84 after a few remove and --purge nvidia*. Apparently there was a libnvidia-compute left and hold it back. Got name correct but detect vram wrong (4095MB). Lets see if it would work. |
 ServicEnginIC ServicEnginICSend message Joined: 24 Sep 10 Posts: 595 Credit: 13,083,686,510 RAC: 1,647,142 Level Scientific publications |
Just take in mind that any change in Nvidia driver version while a GPUgrid task is in progress, will cause it to fail when computing is restarted. Commented in message #56909 |
|
Send message Joined: 21 Feb 20 Posts: 1117 Credit: 40,876,970,595 RAC: 1 Level Scientific publications |
peak 28,9°C here today so suspend during daytime after 2 task done. The VRAM reported wrong is not because of the driver. It’s a problem with BOINC. BOINC uses a detection technique that is only 32-bit (4GB). This can only be fixed by fixing the code in BOINC.
|
|
Send message Joined: 6 Jan 15 Posts: 76 Credit: 25,499,534,331 RAC: 0 Level Scientific publications |
I went back to my host and driver crashed. smi unable to open and task failed on another project. Restarted it and back on track. Few minutes later it fetch new task from GPUGrid. Let's hope it does not crash again. https://www.gpugrid.net/result.php?resultid=32634065 # Speed: average 225.91 ns/day, current 226.09 ns/day That is more like. this much better then my 3070 and 3060Ti got. |
|
Send message Joined: 21 Feb 20 Posts: 1117 Credit: 40,876,970,595 RAC: 1 Level Scientific publications |
GPU detection is handled by BOINC, not any individual projects. Driver updates always require a reboot to take effect.
|
|
ServicEnginIC Send message Joined: 24 Sep 10 Posts: 595 Credit: 13,083,686,510 RAC: 1,647,142 Level Scientific publications |
Finally, my first result of a new version 2.12 task came out in my fastest card: e4s126_e3s248p0f238-ADRIA_New_KIXcMyb_HIP_AdaptiveBandit-0-2-RND6347_7 It took 141948 seconds of total processing time. That is: 1 day 15 hours 25 minutes and 48 seconds Predicted time in table shown at message #57091 was 142074 seconds after 61,439% done. There is a slight difference of 126 seconds between estimated and true execution time. 0,09% deviation. For me, it is approximate enough, and validates Ian&Steve C. theory of progress for these tasks being quite linear along their execution. |
|
Send message Joined: 6 Jan 15 Posts: 76 Credit: 25,499,534,331 RAC: 0 Level Scientific publications |
Compare old and new app on 2070S old 52,930.87 New version of ACEMD v2.11 (cuda100) WU 27069210 e130s1888_e70s25p0f44-ADRIA_D3RBandit_batch_nmax5000-0-1-RND2852_1 new 80,484.11 New version of ACEMD v2.12 (cuda1121) WU: 27077230 e5s177_e4s56p0f117-ADRIA_New_KIXcMyb_HIP_AdaptiveBandit-1-2-RND4081_4 Not sure if size of units grown that much to be able compare them. |
|
Send message Joined: 12 Jul 17 Posts: 404 Credit: 17,412,649,587 RAC: 4,966 Level Scientific publications |
My guesstimate is 19:44:13 on my 3080 dialed down to 230 Watts. 16:06:54 https://www.gpugrid.net/workunit.php?wuid=27077289 |
|
ServicEnginIC Send message Joined: 24 Sep 10 Posts: 595 Credit: 13,083,686,510 RAC: 1,647,142 Level Scientific publications |
At this moment, every of my 7 currently working GPUs have any new version 2.12 task in process. Two tasks received today completed the quota. Task e4s120_e3s763p0f798-ADRIA_New_KIXcMyb_HIP_AdaptiveBandit-1-2-RND9850_3, hanging from WU #27076712 Task e5s90_e4s138p0f962-ADRIA_New_KIXcMyb_HIP_AdaptiveBandit-1-2-RND6130_4, hanging from WU #27077322 Something to remark: These two tasks are repetitive resends of previously failed tasks with the following known problem: acemd3: error while loading shared libraries: libboost_filesystem.so.1.74.0: cannot open shared object file: No such file or directory Chance to remember that there is a remedy for this problem, commented at message #57064 in this same thread. One last update for estimated times to completion on my GPUs: 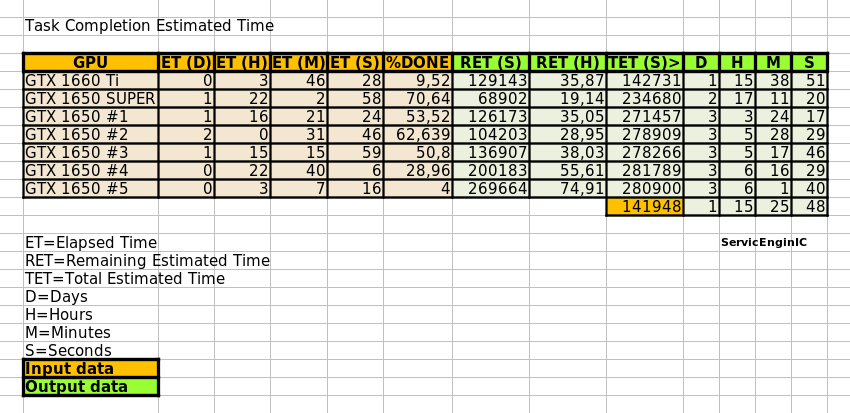 An editable version of the spreadsheet used can be downloaded from this link Changes since previous version: - Lines for two more GPUs are added. - A new cell is added for seconds to D:H:M:S conversion |
|
Send message Joined: 12 Jul 17 Posts: 404 Credit: 17,412,649,587 RAC: 4,966 Level Scientific publications |
So the number of the usable CUDA cores in the 30xx series are half of the advertised number (just as I expected), as 10240/2=5120, 5120/4352=1.1765 (so the 3080Ti has 17.65% more CUDA cores than the 2080Ti has), the CUDA cores of the 3080Ti are 1.4% faster than of the 2080Ti. Does using half of CUDA cores have implications for BOINCing? GG+OPNG at <cpu_usage>1.0</cpu_usage> & <gpu_usage>0.5</gpu_usage> works fine. GG+DaggerHashimoto crashes GG instantly. I hope to try 2xGG today. |
|
Retvari Zoltan Send message Joined: 20 Jan 09 Posts: 2380 Credit: 16,897,957,044 RAC: 0 Level Scientific publications |
Does using half of CUDA cores have implications for BOINCing?You can't utilize the "extra" CUDA cores by running a second task (regardless of the project). The 30xx series improved gaming experience much more, than the crunching performance. |
|
Send message Joined: 21 Feb 20 Posts: 1117 Credit: 40,876,970,595 RAC: 1 Level Scientific publications |
So the number of the usable CUDA cores in the 30xx series are half of the advertised number (just as I expected), as 10240/2=5120, 5120/4352=1.1765 (so the 3080Ti has 17.65% more CUDA cores than the 2080Ti has), the CUDA cores of the 3080Ti are 1.4% faster than of the 2080Ti. I think you misunderstand what's happening. running 2x GPUGRID tasks concurrently wont make it "use more". it'll just slow both down, probably slower than half speed due to the constant resource fighting. if GPUGRID isn't seeing the effective 2x benefit of Turing vs Ampere, that tells me one of two things (or maybe some combination of both): 1. that app isn't as FP32 heavy as some have implied, and maybe has a decent amount of INT32 instructions. the INT32 setup of Ampere is the same as Turing 2. there is some additional optimization that needs to be applied to the ACEMD3 app to better take advantage of the extra FP32 cores on Ampere.
|
|
Send message Joined: 21 May 21 Posts: 1 Credit: 12,242,500 RAC: 0 Level Scientific publications |
if GPUGRID isn't seeing the effective 2x benefit of Turing vs Ampere, that tells me one of two things (or maybe some combination of both): The way Ampere works is that half the cores are FP32, and the other half are either FP32 or INT32 depending on need. On Turing (and older), the INT32 half was always INT32. So you're probably right - either GPUGRID has some INT32 load that is using the cores instead, or some kind of application change is required to get it to use the other half. |
|
Send message Joined: 21 Feb 20 Posts: 1117 Credit: 40,876,970,595 RAC: 1 Level Scientific publications |
I'm not convinced that the extra cores "aren't being used" at all, ie, the cores are sitting idle 100% of the time as a direct result of the architecture or something like that. I think both the application and the hardware are fully aware of the available cores/SMs. just that the application is coded in such a way that it can't take advantage of the extra resources, either in optimization or in the number of INT instructions required. nvidia's press notes do seem to show a 1.5x improvement in molecular modeling load for A100 vs V100, so maybe the amount of INT calls is inherent to this kind of load anyway. (granted the A100 is based on the GA100 core, which is a different architecture without the shared FP/INT cores for the doubling of FP cores like on GA102) but in the case of GPUGRID, i think it's just their application. on folding Ampere performs much closer to the claims. a 3070 being only a bit slower than a 2080ti, which is what I would expect.
|
|
Send message Joined: 12 Jul 17 Posts: 404 Credit: 17,412,649,587 RAC: 4,966 Level Scientific publications |
The 30xx series improved gaming experience much more, than the crunching performance. I'm thoroughly unimpressed by my 3080. Its performance does not scale with price making it much more expensive for doing calculations. I'll probably test it for a few more days and then sell it. I like to use some metric that's proportional to calculations and optimize calcs/Watt. In the past my experience has been reducing max power improves performance. But since Nvidia eliminated the nvidia-settings options -a [gpu:0]/GPUGraphicsClockOffset & -a [gpu:0]/GPUMemoryTransferRateOffset that I used I haven't found a good way to do it using Linux. nvidia-settings -q all It seems Nvidia chooses a performance level but I can't see how to force it to a desired level: sudo DISPLAY=:0 XAUTHORITY=/var/run/lightdm/root/:0 nvidia-settings -q '[gpu:0]/GPUPerfModes' 3080: 0, 1, 2, 3 & 4 Attribute 'GPUPerfModes' (Rig-05:0[gpu:0]): perf=0, nvclock=210, nvclockmin=210, nvclockmax=420, nvclockeditable=1, memclock=405, memclockmin=405, memclockmax=405, memclockeditable=1, memTransferRate=810, memTransferRatemin=810, memTransferRatemax=810, memTransferRateeditable=1 ; perf=1, nvclock=210, nvclockmin=210, nvclockmax=2100, nvclockeditable=1, memclock=810, memclockmin=810, memclockmax=810, memclockeditable=1, memTransferRate=1620, memTransferRatemin=1620, memTransferRatemax=1620, memTransferRateeditable=1 ; perf=2, nvclock=240, nvclockmin=240, nvclockmax=2130, nvclockeditable=1, memclock=5001, memclockmin=5001, memclockmax=5001, memclockeditable=1, memTransferRate=10002, memTransferRatemin=10002, memTransferRatemax=10002, memTransferRateeditable=1 ; perf=3, nvclock=240, nvclockmin=240, nvclockmax=2130, nvclockeditable=1, memclock=9251, memclockmin=9251, memclockmax=9251, memclockeditable=1, memTransferRate=18502, memTransferRatemin=18502, memTransferRatemax=18502, memTransferRateeditable=1 ; perf=4, nvclock=240, nvclockmin=240, nvclockmax=2130, nvclockeditable=1, memclock=9501, memclockmin=9501, memclockmax=9501, memclockeditable=1, memTransferRate=19002, memTransferRatemin=19002, memTransferRatemax=19002, memTransferRateeditable=1 Nvidia has said, "The -a and -g arguments are now deprecated in favor of -q and -i, respectively. However, the old arguments still work for this release." Sounds like they're planning to reduce or eliminate customers ability to control the products they buy. Nvidia also eliminated GPULogoBrightness so the baby-blinkie lights never turn off. |
|
Send message Joined: 12 Jul 17 Posts: 404 Credit: 17,412,649,587 RAC: 4,966 Level Scientific publications |
running 2x GPUGRID tasks concurrently wont make it "use more". it'll just slow both down, probably slower than half speed due to the constant resource fighting. At less than 5% complete with two WUs running simultaneously and having started within minutes of each other: WU1: 4840 sec at 4.7% implies 102978 sec total WU2: 5409 sec at 4.6% implies 117587 sec total From yesterday's singleton: 2 x 58014 sec = 116028 sec total if independent. |
|
Send message Joined: 21 Feb 20 Posts: 1117 Credit: 40,876,970,595 RAC: 1 Level Scientific publications |
running 2x GPUGRID tasks concurrently wont make it "use more". it'll just slow both down, probably slower than half speed due to the constant resource fighting. my point exactly. showing roughly half speed, with no real benefit to running multiples. pushing your completion time to 32hours will only reduce your credit reward since you'll be bumped out of the +50% bonus for returning in 24hrs.
|

©2026 Universitat Pompeu Fabra