Experimental Python tasks (beta) - task description
Message boards :
News :
Experimental Python tasks (beta) - task description
Message board moderation
Previous · 1 · 2 · 3 · 4 · 5 · 6 · 7 · 8 . . . 50 · Next
| Author | Message |
|---|---|
|
Send message Joined: 11 Jul 09 Posts: 1639 Credit: 10,159,968,649 RAC: 0 Level Scientific publications |
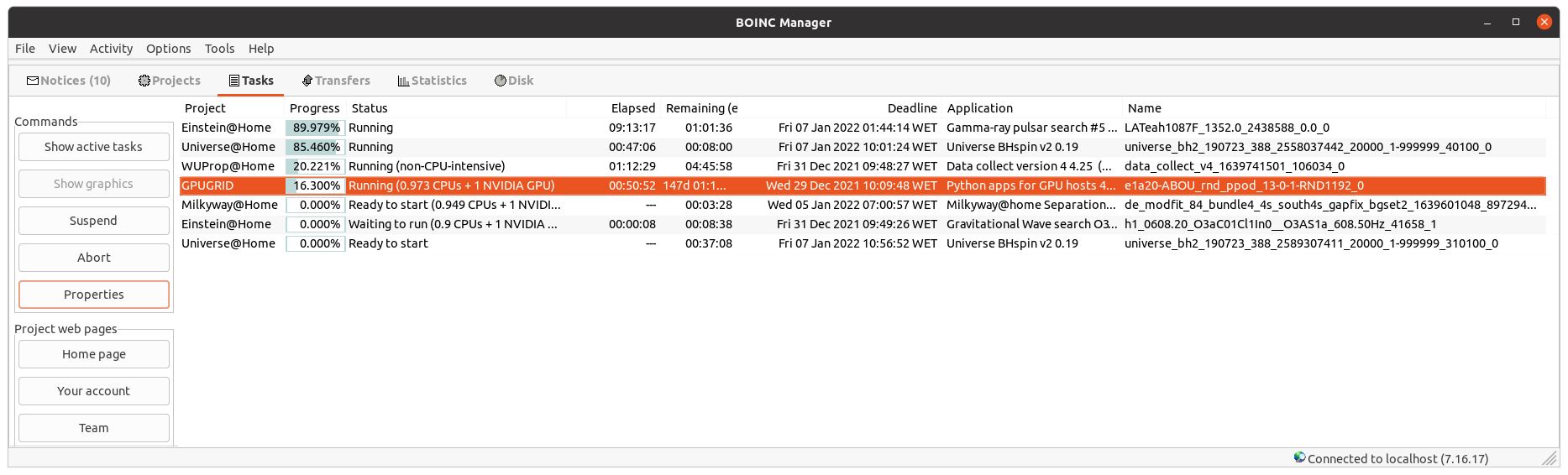
Because this project still uses DCF, the 'exceeded time limit' problem should go away as soon as you can get a single task to complete. Both my machines with finished tasks are now showing realistic estimates, but with DCFs of 5+ and 10+ - I agree, the FLOPs estimate should be increased by that sort of multiplier to keep estimates balanced against other researchers' work for the project. The screen shot also shows how the 'remaining time' estimate gets screwed up when the running value reaches something like 10 hours at 10%. Roll on intermediate progress reports and checkpoints. |
|
Send message Joined: 21 Feb 20 Posts: 1117 Credit: 40,876,970,595 RAC: 0 Level Scientific publications |
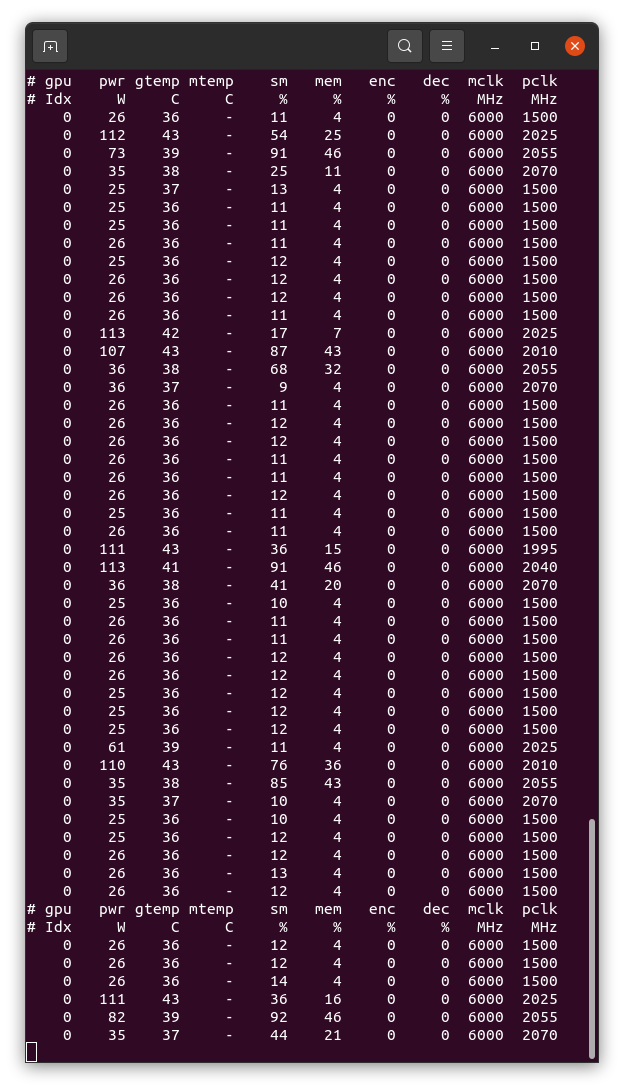
my system that completed a few tasks had a DCF of 36+ checkpointing also still isn't working. I had some tasks running for ~3hrs. restarted boinc and they restarted at 5mins. 
|
|
Send message Joined: 11 Jul 09 Posts: 1639 Credit: 10,159,968,649 RAC: 0 Level Scientific publications |
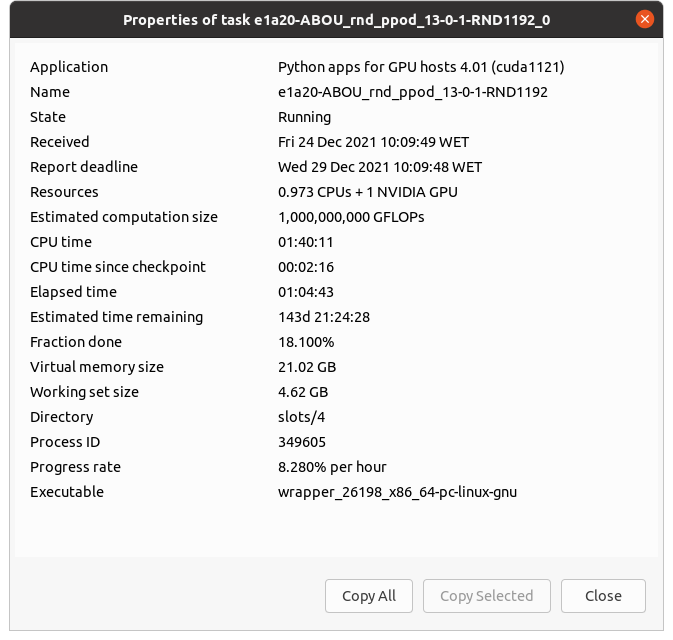
checkpointing also still isn't working. See my screenshot. "CPU time since checkpoint: 16:24:44" |
|
Send message Joined: 11 Jul 09 Posts: 1639 Credit: 10,159,968,649 RAC: 0 Level Scientific publications |
I've checked a sched_request when reporting. <result>
<name>e1a26-ABOU_rnd_ppod_11-0-1-RND6936_0</name>
<final_cpu_time>55983.300000</final_cpu_time>
<final_elapsed_time>36202.136027</final_elapsed_time>That's task 32731632. So it's the server applying the 'sanity(?) check' "elapsed time not less than CPU time". That's right for a single core GPU task, but not right for a task with multithreaded CPU elements. |
|
Send message Joined: 31 May 21 Posts: 200 Credit: 0 RAC: 0 Level Scientific publications |
As mentioned by Ian&Steve C., GPU speed influences only partially task completion time. During the task, the agent first interacts with the environments for a while, then uses the GPU to process the collected data and learn from it, then interacts again with the environments, and so on. In the last batch, I reduced the total amount of agent-environment interactions gathered and processed before ending the task with respect to the previous batch, which should have reduced the completion time. |
|
Send message Joined: 31 May 21 Posts: 200 Credit: 0 RAC: 0 Level Scientific publications |
I will look into the reported issues before sending the next batch, to see if I can find a solution for both the problem of jobs being killed due to “exceeded time limit” and the progress and checkpointing problems. From what Ian&Steve C. mentioned, I understand that increasing the "Estimated Computation Size", however BOINC calculates that, could solve the problem of jobs being killed? Thanks you very much for your feedback. Happy holidays to everyone! |
|
Send message Joined: 11 Jul 09 Posts: 1639 Credit: 10,159,968,649 RAC: 0 Level Scientific publications |
From what Ian&Steve C. mentioned, I understand that increasing the "Estimated Computation Size", however BOINC calculates that, could solve the problem of jobs being killed? The jobs reach us with a workunit description: <workunit>
<name>e1a24-ABOU_rnd_ppod_11-0-1-RND1891</name>
<app_name>PythonGPU</app_name>
<version_num>401</version_num>
<rsc_fpops_est>5000000000000000.000000</rsc_fpops_est>
<rsc_fpops_bound>250000000000000000.000000</rsc_fpops_bound>
<rsc_memory_bound>4000000000.000000</rsc_memory_bound>
<rsc_disk_bound>10000000000.000000</rsc_disk_bound>
<file_ref>
<file_name>e1a24-ABOU_rnd_ppod_11-0-run</file_name>
<open_name>run.py</open_name>
<copy_file/>
</file_ref>
<file_ref>
<file_name>e1a24-ABOU_rnd_ppod_11-0-data</file_name>
<open_name>input.zip</open_name>
<copy_file/>
</file_ref>
<file_ref>
<file_name>e1a24-ABOU_rnd_ppod_11-0-requirements</file_name>
<open_name>requirements.txt</open_name>
<copy_file/>
</file_ref>
<file_ref>
<file_name>e1a24-ABOU_rnd_ppod_11-0-input_enc</file_name>
<open_name>input</open_name>
<copy_file/>
</file_ref>
</workunit>It's the fourth line, '<rsc_fpops_est>', which causes the problem. The job size is given as the estimated number of floating point operations to be calculated, in total. BOINC uses this, along with the estimated speed of the device it's running on, to estimate how long the task will take. For a GPU app, it's usually the speed of the GPU that counts, but in this case - although it's described as a GPU app - the dominant factor might be the speed of the CPU. BOINC doesn't take any direct notice of that. The jobs are killed when they reach the duration calculated from the next line, '<rsc_fpops_bound>'. A quick and dirty fix while testing might be to increase that value even above the current 50x the original estimate, but that removes a valuable safeguard during normal running. |
|
Send message Joined: 31 May 21 Posts: 200 Credit: 0 RAC: 0 Level Scientific publications |
I see, thank you very much for the info. I asked Toni to help me adjusting the "rsc_fpops_est" parameter. Hopefully the next jobs won't be aborted by the server. Also, I checked the progress and the checkpointing problems. They were caused by format errors. The python scripts were logging the progress into a "progress.txt" file but apparently BOINC wants just a file "progress" without extension. Similarly, checkpoints were being generated, but were not identified correctly since they were not called "restart.chk". I will work on fixing these issues before the next batch of tasks. |
|
Send message Joined: 13 Dec 17 Posts: 1424 Credit: 9,189,946,190 RAC: 0 Level Scientific publications |
Thanks @abouh for working with us in debugging your application and work units. Nice to have a attentive and easy to work with researcher. Looking forward to the next batch. |
 ServicEnginIC ServicEnginICSend message Joined: 24 Sep 10 Posts: 595 Credit: 13,083,686,510 RAC: 12,864 Level Scientific publications |
Thank you for your kind support. During the task, the agent first interacts with the environments for a while, then uses the GPU to process the collected data and learn from it, then interacts again with the environments, and so on. This behavior can be seen at some tests described at my Managing non-high-end hosts thread. |
|
Send message Joined: 31 May 21 Posts: 200 Credit: 0 RAC: 0 Level Scientific publications |
I just sent another batch of tasks. I tested locally and the progress and the restart.chk files are correctly generated and updated. rsc_fpops_est job parameter should be higher too now. Please let us know if you think the success rate of tasks can be improved in any other way. Thanks a lot for your help. |
|
ServicEnginIC Send message Joined: 24 Sep 10 Posts: 595 Credit: 13,083,686,510 RAC: 12,864 Level Scientific publications |
I just sent another batch of tasks. Thank you very much for this kind of Christmas present! Merry Christmas to everyone crunchers worldwide 🎄✨ |
|
Send message Joined: 11 Jul 09 Posts: 1639 Credit: 10,159,968,649 RAC: 0 Level Scientific publications |
1,000,000,000 GFLOPs - initial estimate 1690d 21:37:58. That should be enough! I'll watch this one through, but after that I'll be away for a few days - happy holidays, and we'll pick up again on the other side. Edit: Progress %age jumps to 10% after the initial unpacking phase, then increments every 0.9%. That'll do. |
|
ServicEnginIC Send message Joined: 24 Sep 10 Posts: 595 Credit: 13,083,686,510 RAC: 12,864 Level Scientific publications |
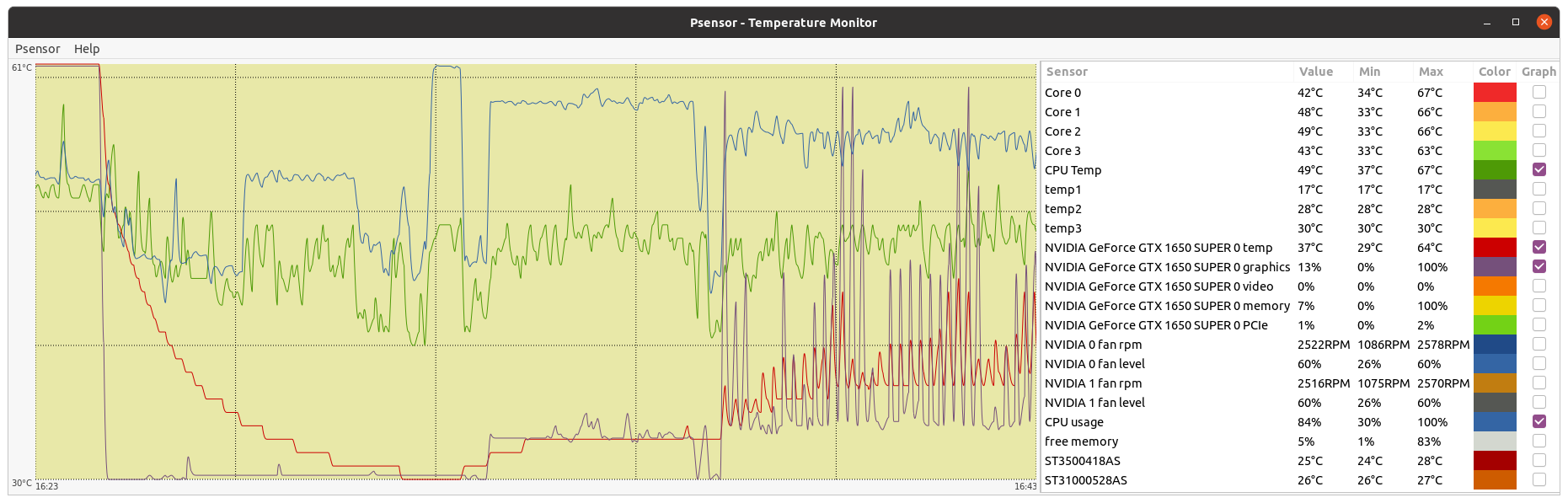
I tested locally and the progress and the restart.chk files are correctly generated and updated. In a preliminary sight of one new Python GPU task received today: - Progress estimation is now working properly, updating by 0,9% increments. - Estimated computation size has raised to 1,000,000,000 GFLOPs, as also confirmed by Richard Haselgrove - Checkpointing seems to be working also, and is being stored at about every two minutes. - Learning cycle period has reduced to 11 seconds from 21 seconds observed at previous task. sudo nvidia-smi dmon - GPU dedicated RAM usage seems to have been reduced, but I don't know if enough for running at 4 GB RAM GPUs (?) - Currrent progress for task e1a20-ABOU_rnd_ppod_13-0-1-RND1192_0 is 28,9% after 2 hours and 13 minutes running. This leads to a total true execution time of about 7 hours and 41 minutes at my Host #569442 Well done! |
|
Send message Joined: 13 Dec 17 Posts: 1424 Credit: 9,189,946,190 RAC: 0 Level Scientific publications |
Same observed behavior. Gpu memory halved, progress indicator normal and GFLOPS in line with actual usage. Well done. |
|
ServicEnginIC Send message Joined: 24 Sep 10 Posts: 595 Credit: 13,083,686,510 RAC: 12,864 Level Scientific publications |
- GPU dedicated RAM usage seems to have been reduced, but I don't know if enough for running at 4 GB RAM GPUs (?) I'm answering to myself: I enabled Python GPU tasks requesting in my GTX 1650 SUPER 4 GB system, and I happened to catch this previously failed task e1a21-ABOU_rnd_ppod_13-0-1-RND2308_1 This task has passed the initial processing steps, and has reached the learning cycle phase. At this point, memory usage is just at the limit of the 4 GB GPU available RAM. Waiting to see whether this task will be succeeding or not. System RAM usage keeps being very high. 99% of the 16 GB available RAM at this system is currently in use. |
|
Send message Joined: 11 Jul 09 Posts: 1639 Credit: 10,159,968,649 RAC: 0 Level Scientific publications |
- Currrent progress for task e1a20-ABOU_rnd_ppod_13-0-1-RND1192_0 is 28,9% after 2 hours and 13 minutes running. This leads to a total true execution time of about 7 hours and 41 minutes at my Host #569442 That's roughly the figure I got in the early stages of today's tasks. But task 32731884 has just finished with <result>
<name>e1a17-ABOU_rnd_ppod_13-0-1-RND0389_3</name>
<final_cpu_time>59637.190000</final_cpu_time>
<final_elapsed_time>39080.805144</final_elapsed_time>That's very similar (and on the same machine) as the one I reported in message 58193. So I don't think the task duration has changed much: maybe the progress %age isn't quite linear (but not enough to worry about). |
|
Send message Joined: 31 May 21 Posts: 200 Credit: 0 RAC: 0 Level Scientific publications |
Hello, reviewing which jobs failed in the last batches I have seen several times this error: 21:28:07 (152316): wrapper (7.7.26016): starting I have found an issue from Richard Haselgrove talking about this error: https://github.com/BOINC/boinc/issues/4125 It seems like the users getting this error could simply solve it by setting PrivateTmp=true. Is that correct? What is the appropriate way to modify that? |
|
ServicEnginIC Send message Joined: 24 Sep 10 Posts: 595 Credit: 13,083,686,510 RAC: 12,864 Level Scientific publications |
It seems like the users getting this error could simply solve it by setting PrivateTmp=true. Is that correct? What is the appropriate way to modify that? Right. I gave a step-by-step solution based on Richard Haselgrove finding at my Message #55986 It worked fine for all my hosts. |
|
Send message Joined: 31 May 21 Posts: 200 Credit: 0 RAC: 0 Level Scientific publications |
Thank you! |
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}

©2026 Universitat Pompeu Fabra