Experimental Python tasks (beta) - task description
Message boards :
News :
Experimental Python tasks (beta) - task description
Message board moderation
Previous · 1 . . . 4 · 5 · 6 · 7 · 8 · 9 · 10 . . . 50 · Next
| Author | Message |
|---|---|
|
Send message Joined: 11 Jul 09 Posts: 1639 Credit: 10,159,968,649 RAC: 0 Level Scientific publications |
You need to look at the creation time of the master WU, not of the individual tasks (which will vary, even within a WU, let alone a batch of WUs). |
|
Send message Joined: 31 May 21 Posts: 200 Credit: 0 RAC: 0 Level Scientific publications |
I have seen this error a few times. concurrent.futures.process.BrokenProcessPool: A process in the process pool was terminated abruptly while the future was running or pending. Do you think it could be due to a lack of resources? I think Linux starts killing processes if you are over capacity. |
|
Send message Joined: 13 Dec 17 Posts: 1424 Credit: 9,189,946,190 RAC: 0 Level Scientific publications |
Might be the OOM-Killer kicking in. You would need to grep -i kill /var/log/messages* to check if processes were killed by the OOM-Killer. If that is the case you would have to configure /etc/sysctl.conf to let the system be less sensitive to brief out of memory conditions. |
|
Send message Joined: 11 Jul 09 Posts: 1639 Credit: 10,159,968,649 RAC: 0 Level Scientific publications |
I Googled the error message, and came up with this stackoverflow thread. The problem seems to be specific to Python, and arises when running concurrent modules. There's a quote from the Python manual: "The main module must be importable by worker subprocesses. This means that ProcessPoolExecutor will not work in the interactive interpreter. Calling Executor or Future methods from a callable submitted to a ProcessPoolExecutor will result in deadlock." Other search results may provide further clues. |
|
Send message Joined: 31 May 21 Posts: 200 Credit: 0 RAC: 0 Level Scientific publications |
Thanks! out of the possible explanations that could cause the error listed in the thread, I suspect it could be OS killing the threads do to a lack of resources. Could be not enough RAM, or maybe python raises this error if the ratio cores / processes is high? (I have seen some machines with 4 CPUs, and the tasks spawns 32 reinforcement learning environments). All tasks run the same code and in the majority of GPUGrid machines this error does no occur. Also, I have reviewed the failed jobs and this errors always occurs in the same hosts. So it is something specific to those machines. I will check if I find a common patterns in all hosts that get this error. |
|
Send message Joined: 13 Dec 17 Posts: 1424 Credit: 9,189,946,190 RAC: 0 Level Scientific publications |
What version of Python are the hosts that have the errors running? Mine for example is: python3 --version Python 3.8.10 What kernel and OS? Linux 5.11.0-46-generic x86_64 Ubuntu 20.04.3 LTS I've had the errors on hosts with 32GB and 128GB. I would assume the hosts with 128GB to be in the clear with no memory pressures. |
 ServicEnginIC ServicEnginICSend message Joined: 24 Sep 10 Posts: 595 Credit: 13,083,686,510 RAC: 10,553 Level Scientific publications |
What version of Python are the hosts that have the errors running? Same Python version as current mine. In case of doubt about conflicting Python versions, I published the solution that I applied to my hosts at Message #57833 It worked for my Ubuntu 20.04.3 LTS Linux distribution, but user mmonnin replied that this didn't work for him. mmonnin kindly published an alternative way at his Message #57840 |
|
Send message Joined: 2 Jul 16 Posts: 339 Credit: 8,281,341,558 RAC: 2,803 Level Scientific publications |
I saw the prior post and was about to mention the same thing. Not sure which one works as the PC has been able to run tasks. The recent tasks are taking a really long time 2d13h 62,2% 1070 and 1080 GPU system 2d15h 60.4% 1070 and 1080 GPU system 2x concurrently on 3080Ti 2d12h 61.3% 2d14h 60.4% |
|
Send message Joined: 31 May 21 Posts: 200 Credit: 0 RAC: 0 Level Scientific publications |
All jobs should use the same python version (3.8.10), I define it in the requirements.txt file of the conda environment. Here are the specs from 3 hosts that failed with the BrokenProcessPool error: OS: Linux Debian Debian GNU/Linux 11 (bullseye) [5.10.0-10-amd64|libc 2.31 (Debian GLIBC 2.31-13+deb11u2)] Linux Ubuntu Ubuntu 20.04.3 LTS [5.4.0-94-generic|libc 2.31 (Ubuntu GLIBC 2.31-0ubuntu9.3)] Linux Linuxmint Linux Mint 20.2 [5.4.0-91-generic|libc 2.31 (Ubuntu GLIBC 2.31-0ubuntu9.2)] Memory: 32081.92 MB 32092.04 MB 9954.41 MB |
|
Send message Joined: 13 Dec 17 Posts: 1424 Credit: 9,189,946,190 RAC: 0 Level Scientific publications |
I have a failed task today involving pickle. magic_number = pickle_module.load(f, **pickle_load_args) EOFError: Ran out of input When I was investigating the brokenprocesspool error I saw posts that involved the word pickle and the fixes for that error. https://www.gpugrid.net/result.php?resultid=32733573 |
|
Send message Joined: 3 Sep 21 Posts: 3 Credit: 146,609,125 RAC: 0 Level Scientific publications |
The tasks run on my Tesla K20 for a while, but then fail when they need to use PyTorch, which requires higher CUDA Capability. Oh well. Guess I'll stick to the ACEMED tasks. The error output doesn't list the requirements properly, but from a little Googling, it was updated to require 3.7 within the past couple years. The only Kepler card that has 3.7 is the Tesla K80. From this task:
[W NNPACK.cpp:79] Could not initialize NNPACK! Reason: Unsupported hardware.
/var/lib/boinc-client/slots/2/gpugridpy/lib/python3.8/site-packages/torch/cuda/__init__.py:120: UserWarning:
Found GPU%d %s which is of cuda capability %d.%d.
PyTorch no longer supports this GPU because it is too old.
The minimum cuda capability supported by this library is %d.%d.
While I'm here, is there any way to force the project to update my hardware configuration? It thinks my host has two Quadro K620s instead of one of those and the Tesla. |
|
Send message Joined: 21 Feb 20 Posts: 1117 Credit: 40,876,970,595 RAC: 0 Level Scientific publications |
While I'm here, is there any way to force the project to update my hardware configuration? It thinks my host has two Quadro K620s instead of one of those and the Tesla. this is a problem (feature?) of BOINC, not the project. the project only knows what hardware you have based on what BOINC communicates to the project. with cards from the same vendor (nvidia/AMD/Intel) BOINC only lists the "best" card and then appends a number that's associated with how many total devices you have from that vendor. it will only list different models if they are from different vendors. within the nvidia vendor group, BOINC figures out the "best" device by checking the compute capability first, then memory capacity, then some third metric that i cant remember right now. BOINC deems the K620 to be "best" because it has a higher compute capability (5.0) than the Tesla K20 (3.5) even though the K20 is arguably the better card with more/faster memory and more cores. all in all, this has nothing to do with the project, and everything to do with BOINC's GPU ranking code. 
|
|
Send message Joined: 2 Jul 16 Posts: 339 Credit: 8,281,341,558 RAC: 2,803 Level Scientific publications |
While I'm here, is there any way to force the project to update my hardware configuration? It thinks my host has two Quadro K620s instead of one of those and the Tesla. Its often said as the "Best" card but its just the 1st https://www.gpugrid.net/show_host_detail.php?hostid=475308 This host has a 1070 and 1080 but just shows 2x 1070s as the 1070 is in the 1st slot. Any way to check for a "best" would come up with the 1080. Or the 1070Ti that used to be there with the 1070. |
|
Send message Joined: 21 Feb 20 Posts: 1117 Credit: 40,876,970,595 RAC: 0 Level Scientific publications |
In your case, the metrics that BOINC is looking at are identical between the two cards (actually all three of the 1070, 1070Ti, and 1080 have identical specs as far as BOINC ranking is concerned). All have the same amount of VRAM and have the same compute capability. So the tie goes to device number I guess. If you were to swap the 1080 for even a weaker card with a better CC (like a GTX 1650) then that would get picked up instead, even when not in the first slot.
|
|
Send message Joined: 3 Sep 21 Posts: 3 Credit: 146,609,125 RAC: 0 Level Scientific publications |
Ah, I get it. I thought it was just stuck, because it did have two K620s before. I didn't realize BOINC was just incapable of acknowledging different cards from the same vendor. Does this affect project statistics? The Milkyway@home folks are gonna have real inflated opinions of the K620 next time they check the numbers haha |
|
Send message Joined: 31 May 21 Posts: 200 Credit: 0 RAC: 0 Level Scientific publications |
Interesting I had seen this error once before locally, and I assumed it was due to a corrupted input file. I have reviewed the task and it was solved by another hosts, but only after multiple failed attempts with this pickle error. Thank you for bringing it up! I will review the code to see if I can find any bug related to that. |
|
Send message Joined: 13 Dec 17 Posts: 1424 Credit: 9,189,946,190 RAC: 0 Level Scientific publications |
This is the document I had found about fixing the BrokenProcessPool error. https://stackoverflow.com/questions/57031253/how-to-fix-brokenprocesspool-error-for-concurrent-futures-processpoolexecutor I was reading it and stumbled upon the word "pickle" and verb "picklable" and thought it funny and I never had heard that word associated with computing before. When the latest failed task mentioned pickle in the output, it tied it right back to all the previous BrokenProcessPool errors. |
|
Send message Joined: 23 Dec 09 Posts: 189 Credit: 4,813,881,008 RAC: 149 Level Scientific publications |
@abouh: Thank you for PM me twice! The Experimental Python tasks (beta) succeed miraculously on my two Linux computers (which produced only errors) after several restarts of GPUGRID.net project and the latest distro update this week. |
|
ServicEnginIC Send message Joined: 24 Sep 10 Posts: 595 Credit: 13,083,686,510 RAC: 10,553 Level Scientific publications |
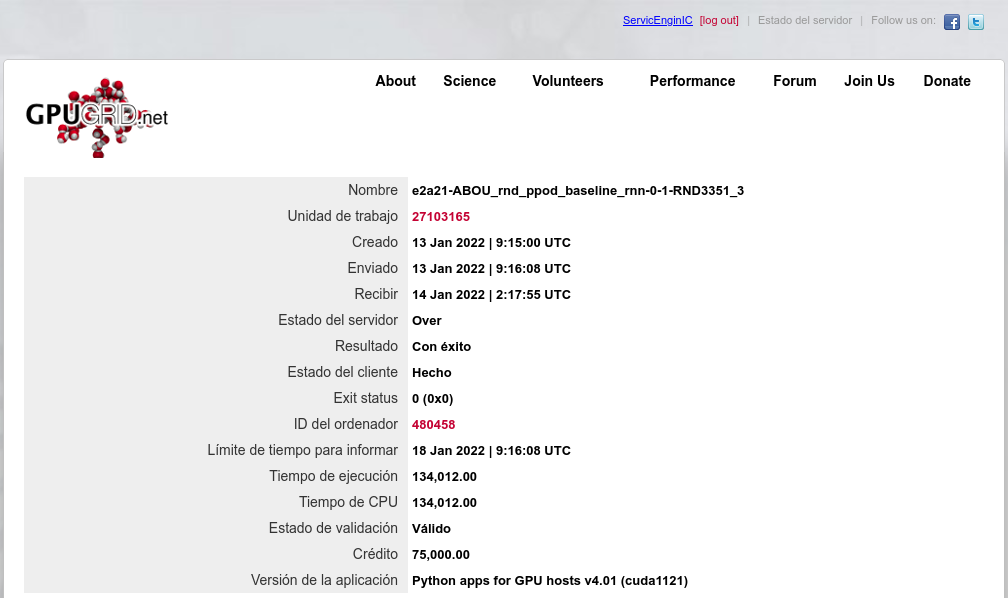
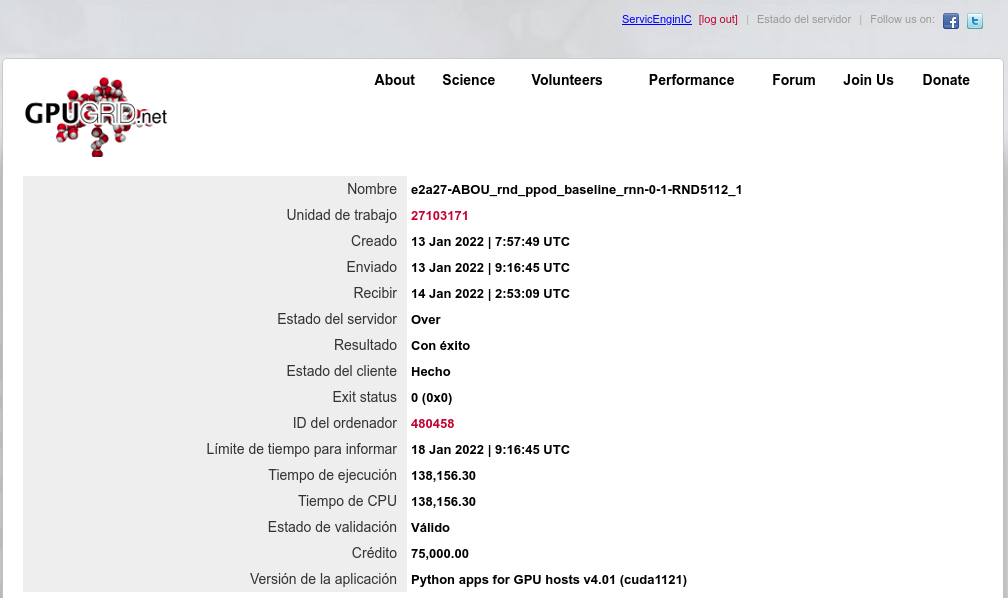
Also I happened to catch two simultaneous Python tasks at my triple GTX 1650 GPU host. After upgrading system RAM from 32 GB to 64 GB at above mentioned host, it has successfully processed three concurrent ABOU Python GPU tasks: e2a43-ABOU_rnd_ppod_baseline_rnn-0-1-RND6933_3 - Link: https://www.gpugrid.net/result.php?resultid=32733458 e2a21-ABOU_rnd_ppod_baseline_rnn-0-1-RND3351_3 - Link: https://www.gpugrid.net/result.php?resultid=32733477 e2a27-ABOU_rnd_ppod_baseline_rnn-0-1-RND5112_1 - Link: https://www.gpugrid.net/result.php?resultid=32733441 More details at regarding Message #58287 |
|
Send message Joined: 31 May 21 Posts: 200 Credit: 0 RAC: 0 Level Scientific publications |
Hello everyone, I have seen a new error in some jobs: Traceback (most recent call last): It seems like the task is not allowed to create a new dirs inside its working directory. Just wondering if it could be some kind of configuration problem, just like the "INTERNAL ERROR: cannot create temporary directory!" for which a solution was already shared. |
{kind=link}
{kind=link}
{kind=link}

©2026 Universitat Pompeu Fabra