Experimental Python tasks (beta) - task description
Message boards :
News :
Experimental Python tasks (beta) - task description
Message board moderation
Previous · 1 . . . 3 · 4 · 5 · 6 · 7 · 8 · 9 . . . 50 · Next
| Author | Message |
|---|---|
|
Send message Joined: 11 Jul 09 Posts: 1639 Credit: 10,159,968,649 RAC: 0 Level Scientific publications |
Some new (to me) errors in https://www.gpugrid.net/result.php?resultid=32732017 "During handling of the above exception, another exception occurred:" "ValueError: probabilities are not non-negative" |
|
Send message Joined: 21 Feb 20 Posts: 1117 Credit: 40,876,970,595 RAC: 0 Level Scientific publications |
it seems checkpointing still isnt working correctly. despite BOINC "claiming" that it's checkpointing X number of seconds ago, stopping BOINC and re-starting shows that it's not restarting from the checkpoint. The task I currently have in progress was ~20% completed. stopped BOINC, and restarted and it retained the time (elapsed and CPU time) but progress reset to 10%. 
|
|
Send message Joined: 13 Dec 17 Posts: 1424 Credit: 9,189,946,190 RAC: 0 Level Scientific publications |
I saw the same issue on my last task which was checkpointed past 20% yet reset to 10% upon restart. |
 ServicEnginIC ServicEnginICSend message Joined: 24 Sep 10 Posts: 595 Credit: 13,083,686,510 RAC: 10,553 Level Scientific publications |
- GPU dedicated RAM usage seems to have been reduced, but I don't know if enough for running at 4 GB RAM GPUs (?) Two of my hosts with 4 GB dedicated RAM GPUs have succeeded their latest Python GPU tasks so far. If it is planned to be kept GPU RAM requirements this way, it widens the app to a quite greater number of hosts. Also I happened to catch two simultaneous Python tasks at my triple GTX 1650 GPU host. I then urgently suspended requesting for Gpugrid tasks at BOINC Manager... Why? This host system RAM size is 32 GB. When the second Python task started, free system RAM decreased to 1% (!). I grossly estimate that environment for each Python task takes about 16 GB system RAM. I guess that an eventual third concurrent task might have crashed itself, or even crashed the whole three Python tasks due to lack of system RAM. I was watching to Psensor readings when the first of the two Python tasks finished, and then the free system memory drastically increased again from 1% to 38%. I also took a nvidia-smi screenshot, where can be seen that each Python task was respectively running at GPU 0 and GPU 1, while GPU 2 was processing a PrimeGrid CUDA GPU task. 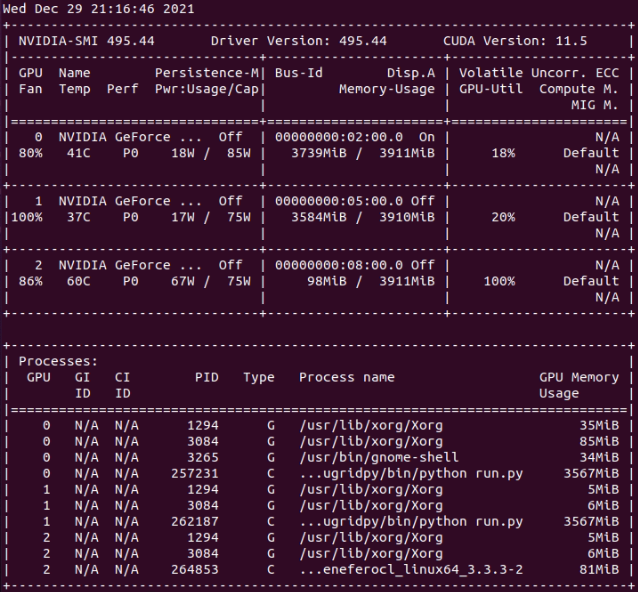 |
|
Send message Joined: 21 Feb 20 Posts: 1117 Credit: 40,876,970,595 RAC: 0 Level Scientific publications |
now that I've upgraded my single 3080Ti host from a 5950X w/16GB ram to a 7402P/128GB ram, I want to see if I can even run 2x GPUGRID tasks on the same GPU. I see about 5GB VRAM use on the tasks I've processed so far. so with so much extra system ram and 12GB VRAM, it might work lol.
|
|
Send message Joined: 31 May 21 Posts: 200 Credit: 0 RAC: 0 Level Scientific publications |
Regarding the checkpointing problem, the approach I follow is to check the progress file (if exists) at the beginning of the python script and then continue the job from there. I have tested locally to stop the task and execute again the python script and it continues from the same point where it stopped. So the script seems correct. However, I think that right after setting up the conda environment, the progress is set automatically to 10% before running my script, so I am guessing this is what is causing the problem. I have modified my code not to rely only on the progress file, since it might be overwritten after every conda setup to be at 10%. |
|
Send message Joined: 2 Jul 16 Posts: 339 Credit: 8,281,341,558 RAC: 2,803 Level Scientific publications |
now that I've upgraded my single 3080Ti host from a 5950X w/16GB ram to a 7402P/128GB ram, I want to see if I can even run 2x GPUGRID tasks on the same GPU. I see about 5GB VRAM use on the tasks I've processed so far. so with so much extra system ram and 12GB VRAM, it might work lol. The last two tasks on my system with a 3080Ti ran concurrently and completed successfully. https://www.gpugrid.net/results.php?hostid=477247 |
|
Send message Joined: 11 Jul 09 Posts: 1639 Credit: 10,159,968,649 RAC: 0 Level Scientific publications |
Errors in e6a12-ABOU_rnd_ppod_15-0-1-RND6167_2 (created today): "wandb: Waiting for W&B process to finish, PID 334655... (failed 1). Press ctrl-c to abort syncing." "ValueError: demo dir contains more than ´total_buffer_demo_capacity´" |
|
Send message Joined: 31 May 21 Posts: 200 Credit: 0 RAC: 0 Level Scientific publications |
One user mentioned that could not solve the error INTERNAL ERROR: cannot create temporary directory! This is the configuration he is using: ### Editing /etc/systemd/system/boinc-client.service.d/override.conf I was just wondering if there is any possible reason why it should not work |
|
Send message Joined: 11 Jul 09 Posts: 1639 Credit: 10,159,968,649 RAC: 0 Level Scientific publications |
I am using a systemd file generated from a PPA maintained by Gianfranco Costamagna. It's automatically generated from Debian sources, and kept up-to-date with new releases automatically. It's currently supplying a BOINC suite labelled v7.16.17 The full, unmodified, contents of the file are [Unit] Description=Berkeley Open Infrastructure Network Computing Client Documentation=man:boinc(1) After=network-online.target [Service] Type=simple ProtectHome=true PrivateTmp=true ProtectSystem=strict ProtectControlGroups=true ReadWritePaths=-/var/lib/boinc -/etc/boinc-client Nice=10 User=boinc WorkingDirectory=/var/lib/boinc ExecStart=/usr/bin/boinc ExecStop=/usr/bin/boinccmd --quit ExecReload=/usr/bin/boinccmd --read_cc_config ExecStopPost=/bin/rm -f lockfile IOSchedulingClass=idle # The following options prevent setuid root as they imply NoNewPrivileges=true # Since Atlas requires setuid root, they break Atlas # In order to improve security, if you're not using Atlas, # Add these options to the [Service] section of an override file using # sudo systemctl edit boinc-client.service #NoNewPrivileges=true #ProtectKernelModules=true #ProtectKernelTunables=true #RestrictRealtime=true #RestrictAddressFamilies=AF_INET AF_INET6 AF_UNIX #RestrictNamespaces=true #PrivateUsers=true #CapabilityBoundingSet= #MemoryDenyWriteExecute=true [Install] WantedBy=multi-user.target That has the 'PrivateTmp=true' line in the [Service] section of the file, rather than isolated at the top as in your example. I don't know Linux well enough to know how critical the positioning is. We had long discussions in the BOINC development community a couple of years ago, when it was discovered that the 'PrivateTmp=true' setting blocked access to BOINC's X-server based idle detection. The default setting was reversed for a while, until it was discovered that the reverse 'PrivateTmp=false' setting caused the problem creating temporary directories that we observe here. I think that the default setting was reverted to true, but the discussion moved into the darker reaches of the Linux package maintenance managers, and the BOINC development cycle became somewhat disjointed. I'm no longer fully up-to-date with the state of play. |
|
Send message Joined: 11 Jul 09 Posts: 1639 Credit: 10,159,968,649 RAC: 0 Level Scientific publications |
A simpler answer might be ### Lines below this comment will be discarded so the file as posted won't do anything at all - in particular, it won't run BOINC! |
|
Send message Joined: 31 May 21 Posts: 200 Credit: 0 RAC: 0 Level Scientific publications |
Thank you! I reviewed the code and detected the source of the error. I am currently working to solve it. I will do local tests and then send a small batch of short tasks to GPUGrid to test the fixed version of the scripts before sending the next big batch. |
|
Send message Joined: 11 Jul 09 Posts: 1639 Credit: 10,159,968,649 RAC: 0 Level Scientific publications |
Everybody seems to be getting the same error in today's tasks: "AttributeError: 'PPODBuffer' object has no attribute 'num_loaded_agent_demos'" |
|
Send message Joined: 13 Dec 17 Posts: 1424 Credit: 9,189,946,190 RAC: 0 Level Scientific publications |
I believe I got one of the test, fixed tasks this morning based on the short crunch time and valid report. No sign of the previous error. https://www.gpugrid.net/result.php?resultid=32732671 |
|
Send message Joined: 11 Jul 09 Posts: 1639 Credit: 10,159,968,649 RAC: 0 Level Scientific publications |
Yes, your workunit was "created 7 Jan 2022 | 17:50:07 UTC" - that's a couple of hours after the ones I saw. |
|
Send message Joined: 31 May 21 Posts: 200 Credit: 0 RAC: 0 Level Scientific publications |
I just sent a batch that seems to fail with File "/var/lib/boinc-client/slots/30/python_dependencies/ppod_buffer_v2.py", line 325, in before_gradients For some reason it did not crash locally. "Fortunately" it will crash after only a few minutes, and it is easy to solve. I am very sorry for the inconvenience... I will send also a corrected batch with tasks of normal duration. I have tried to reduce the GPU memory requirements a bit in the new tasks. |
|
Send message Joined: 11 Jul 09 Posts: 1639 Credit: 10,159,968,649 RAC: 0 Level Scientific publications |
Got one of those - failed as you describe. Also has the error message "AttributeError: 'GWorker' object has no attribute 'batches'". Edit - had a couple more of the broken ones, but one created at 10:40:34 UTC seems to be running OK. We'll know later! |
|
Send message Joined: 7 Apr 15 Posts: 17 Credit: 3,095,057,945 RAC: 661 Level Scientific publications |
I got 20 bad WU's today on this host: https://www.gpugrid.net/results.php?hostid=520456
Stderr Ausgabe
<core_client_version>7.16.6</core_client_version>
<![CDATA[
<message>
process exited with code 195 (0xc3, -61)</message>
<stderr_txt>
13:25:53 (6392): wrapper (7.7.26016): starting
13:25:53 (6392): wrapper (7.7.26016): starting
13:25:53 (6392): wrapper: running /usr/bin/flock (/var/lib/boinc-client/projects/www.gpugrid.net/miniconda.lock -c "/bin/bash ./miniconda-installer.sh -b -u -p /var/lib/boinc-client/projects/www.gpugrid.net/miniconda &&
/var/lib/boinc-client/projects/www.gpugrid.net/miniconda/bin/conda install -m -y -p gpugridpy --file requirements.txt ")
0%| | 0/45 [00:00<?, ?it/s]
concurrent.futures.process._RemoteTraceback:
'''
Traceback (most recent call last):
File "concurrent/futures/process.py", line 368, in _queue_management_worker
File "multiprocessing/connection.py", line 251, in recv
TypeError: __init__() missing 1 required positional argument: 'msg'
'''
The above exception was the direct cause of the following exception:
Traceback (most recent call last):
File "entry_point.py", line 69, in <module>
File "concurrent/futures/process.py", line 484, in _chain_from_iterable_of_lists
File "concurrent/futures/_base.py", line 611, in result_iterator
File "concurrent/futures/_base.py", line 439, in result
File "concurrent/futures/_base.py", line 388, in __get_result
concurrent.futures.process.BrokenProcessPool: A process in the process pool was terminated abruptly while the future was running or pending.
[6689] Failed to execute script entry_point
13:25:58 (6392): /usr/bin/flock exited; CPU time 3.906269
13:25:58 (6392): app exit status: 0x1
13:25:58 (6392): called boinc_finish(195)
</stderr_txt>
]]>
|
|
Send message Joined: 13 Dec 17 Posts: 1424 Credit: 9,189,946,190 RAC: 0 Level Scientific publications |
I errored out 12 tasks created from 10:09:55 to 10:40:06. Those all have the batch error. But have 3 tasks created from 10:41:01 to 11:01:56 still running normally |
|
Send message Joined: 13 Dec 17 Posts: 1424 Credit: 9,189,946,190 RAC: 0 Level Scientific publications |
And two of those were the batch error resends that now have failed. Only 1 still processing that I assume is of the fixed variety. 8 hours elapsed currently. https://www.gpugrid.net/result.php?resultid=32732855 |
{kind=link}

©2026 Universitat Pompeu Fabra