Ampere 10496 & 8704 & 5888 fp32 cores!
Message boards :
Graphics cards (GPUs) :
Ampere 10496 & 8704 & 5888 fp32 cores!
Message board moderation
Previous · 1 · 2 · 3 · 4 · 5 . . . 6 · Next
| Author | Message |
|---|---|
|
Send message Joined: 13 Dec 17 Posts: 1424 Credit: 9,189,946,190 RAC: 0 Level Scientific publications |
Plain sailing from here? No, not at all. No compatible apps yet. |
|
Send message Joined: 4 Aug 14 Posts: 266 Credit: 2,219,935,054 RAC: 0 Level Scientific publications |
Plain sailing from here? Based on past Architectural changes and app upgrades to match have taken 6 months or more for the new app. First Pascal GPU released May 2016, Gpugrid Pascal compatible app released November 2016. First Turing GPU released September 2018, Gpugrid Turing compatible app released October 2019. (Working from memory here, so please correct if the timeline is not right.) However, the change to Wrapper introduced on the Turing app upgrade, may shorten the app development cycle. |
|
Send message Joined: 9 Dec 08 Posts: 1006 Credit: 5,068,599 RAC: 0 Level Scientific publications |
We don't have access to any card yet. |
|
Send message Joined: 22 May 20 Posts: 110 Credit: 115,525,136 RAC: 0 Level Scientific publications |
Don't know if this has a lot of relevance for those of you currently considering to purchase or already having bought a RTX 30xx series card, but over at F@H they have recently been rolling out CUDA support on their GPU cores and were able to drastically increase the average speed of NVIDIA cards. They ran an analysis on the efficiency gain of the cards produced by the CUDA support and included in one of their analysis an RTX 3080. https://foldingathome.org/2020/09/28/foldingathome-gets-cuda-support/ I can't post pictures here, so just take a look at the third graph posted on this site. From what I can tell, the RTX 3080 achieves an improvement of 10-15% over a RTX 2080 Ti in this one particular GPU task they benchmarked the cards to. This might be interesting for benchmarking the performance here as well. Thought this might be of interest to some of you. |
|
Send message Joined: 21 Feb 20 Posts: 1117 Credit: 40,876,970,595 RAC: 0 Level Scientific publications |
We don't have access to any card yet. don't think you really need a physical card to make the new app. just download the latest CUDA toolkit, and recompile the app with CUDA 11.1 instead of 10. when I was compiling some apps for SETI, I did the compiling on a virtual machine that didn't even have a GPU. as long as you set the environment variables and point to the right CUDA libraries, you shouldn't have any trouble. you really can do it on whatever system you used before. just make sure you add the gencode variables sm_80 and sm_86 to your makefile so that the new cards will work. so like this: -gencode=arch=compute_80,code=sm_80 -gencode=arch=compute_80,code=compute_80 -gencode=arch=compute_86,code=sm_86 -gencode=arch=compute_86,code=compute_86 also give a look through the documentation for the CUDA 11.1 toolkit. https://docs.nvidia.com/cuda/index.html https://docs.nvidia.com/cuda/ampere-tuning-guide/index.html take note this quote: 1.4.1.6. Improved FP32 throughput just make it a beta release, so those with an Ampere card can test it for you. 
|
|
Send message Joined: 21 Feb 20 Posts: 1117 Credit: 40,876,970,595 RAC: 0 Level Scientific publications |
Don't know if this has a lot of relevance for those of you currently considering to purchase or already having bought a RTX 30xx series card, but over at F@H they have recently been rolling out CUDA support on their GPU cores and were able to drastically increase the average speed of NVIDIA cards. i think we might see a bigger uplift in performance actually. it seems those tests might be seeing speedups from increased memory capacity and bandwidth, combined with the core speed. I think the 3080 is *only* 10-15% ahead of the 2080ti because of memory config being limited to only 10GB of memory one thing that stands out to me, is that their benchmarks show the Tesla V100 16GB as being significantly faster than a 2080ti, but comparing empirical data from users with that GPU show it to actually be slower than the 2080ti at GPUGRID. this leaves me to theorize that GPUGRID doesnt utilize the memory system as much, and instead relies mostly on core power. this is further supported by my own testing where not only is GPU VRAM minimally used (less than 1GB), but increasing the memory speed makes almost no change to crunching times. if we can get a new app compiled for 11.1 to support the CC 8.6 cards, we may very well see a large improvement to the processing times since comparing the core power alone, the 3080 should be much stronger.
|
 Retvari Zoltan Retvari ZoltanSend message Joined: 20 Jan 09 Posts: 2380 Credit: 16,897,957,044 RAC: 0 Level Scientific publications |
Don't know if this has a lot of relevance for those of you currently considering to purchase or already having bought a RTX 30xx series card, but over at F@H they have recently been rolling out CUDA support on their GPU cores and were able to drastically increase the average speed of NVIDIA cards.That's great news! They ran an analysis on the efficiency gain of the cards produced by the CUDA support and included in one of their analysis an RTX 3080.That's the down to earth data of their real world performance I've been waiting for. I can't post pictures here, so just take a look at the third graph posted on this site.I can, but it's a bit large: (sorry for that, I've linked the original picture, at least the important parts are on the left) 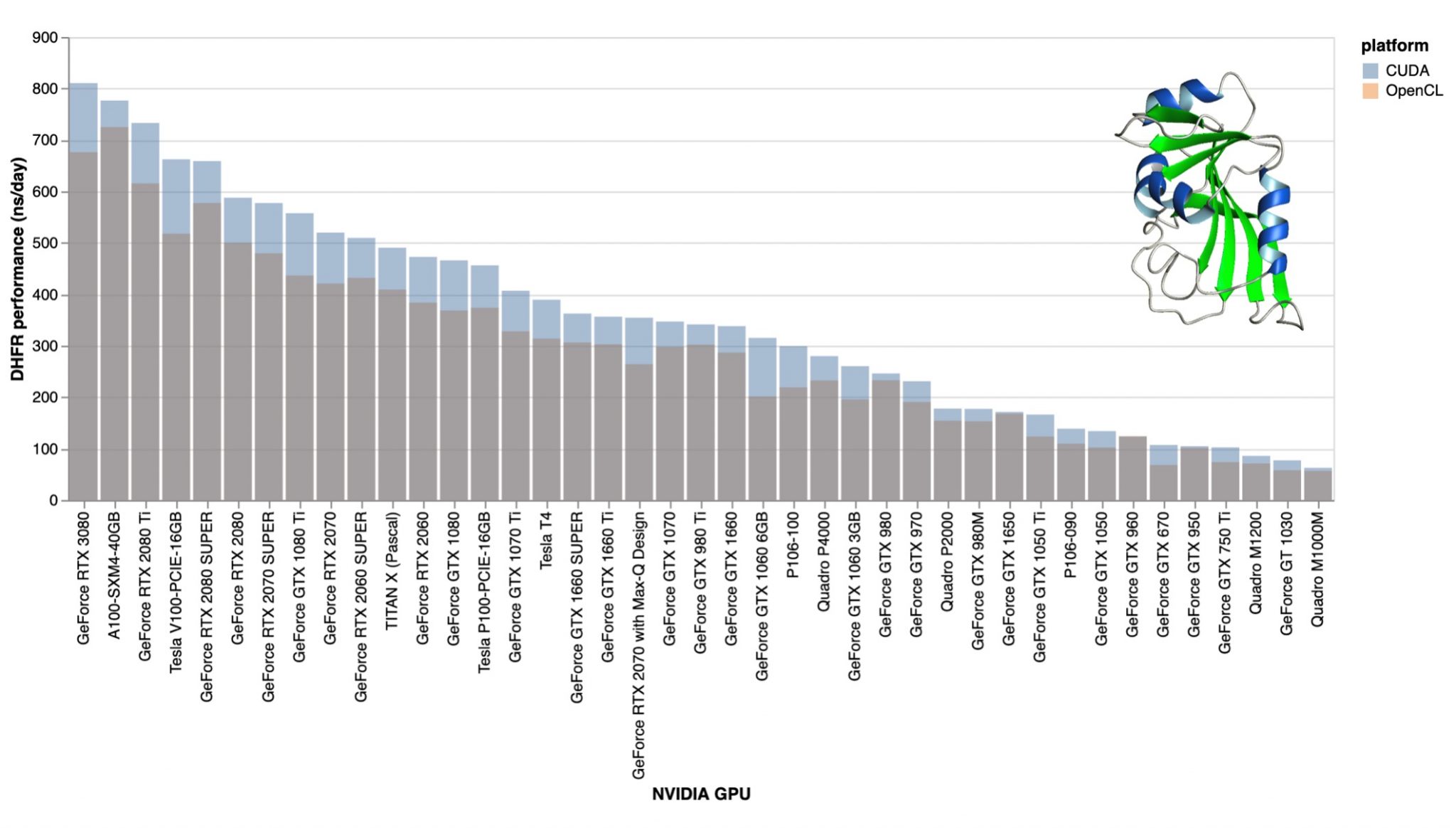 From what I can tell, the RTX 3080 achieves an improvement of 10-15% over a RTX 2080 Ti in this one particular GPU task they benchmarked the cards to. This might be interesting for benchmarking the performance here as well. Thought this might be of interest to some of you.That's the performance improvement I've expected. This 10-15% performance improvement (3080 vs 2080Ti) confirms my expectations about the 1:2 ratio of the usable vs advertised number of CUDA cores of the Ampere architecture. This is actually a misunderstanding, as the number of the CUDA cores are: RTX 3090 5248 RTX 3080 4352 RTX 3070 2944but every CUDA core has two FP32 units in the Ampere architecture. Actually the INT32 part (existing in previous generations too) of the CUDA cores has been extended to be able to handle FP32 calculations. It seems that these "extra" FP32 units can't be utilized by the scientific applications I'm interested in. |
|
Send message Joined: 21 Feb 20 Posts: 1117 Credit: 40,876,970,595 RAC: 0 Level Scientific publications |
but every CUDA core has two FP32 units in the Ampere architecture. Actually the INT32 part (existing in previous generations too) of the CUDA cores has been extended to be able to handle FP32 calculations. It seems that these "extra" FP32 units can't be utilized by the scientific applications I'm interested in. this is something we can't know until GPUGRID recompiles the app for sm_86 with CUDA 11.1. it will also depend on what kinds of operations GPUGRID is doing. if they are mostly INT, then maybe not much improvement, but if they are FP32 heavy, we can expect to see a big improvement. it's just something that we need to wait for the app for. as I mentioned in my previous posts, you can't rely on that benchmark very strongly. there are performance inconsistencies already between what it shows and what you can see here at GPUGRID (specifically as it relates to the performance between the V100 and the 2080ti)
|
|
Send message Joined: 22 May 20 Posts: 110 Credit: 115,525,136 RAC: 0 Level Scientific publications |
Just meant this as a pointer. Don't know what data they included in their analysis in the sense of how many GPUs were flowing in this data aggregation. Honestly, I am in way over my head with all this technical talk about GPU application porting, wrappers, code recompiling, CUDA libraries etc., even though I am trying to read up on it online as much as I can to get more proficient with those terms. However, as F@H is currently arguably the largest GPU platform/colection of (at least consumer-grade) GPU cards, I would reckon that the numbers shown here are as representative as they can get due to those values being averaged out over a bunch of various card makes for each gen. So I'd argue that this value is a solid benchmark. At least for 1) now, 2) without further optimisation for the Ampere infrastructure and 3) for this specific task at F@H. I'd suggest to ask in their forums about the data that was used to derive those values and what those task requirements have been to induce valuable information for a possible RTX 30xx series performance on GPUGRID. Sigh.... I wish I had the problem of figuring out how much performance is set to be gained of a 3080 over a 2080 Ti. For the moment I am stuck with the 750 Ti (fourth last)... And thanks for including this graph here Zoltán! Good luck with your endeavour! |
|
Retvari Zoltan Send message Joined: 20 Jan 09 Posts: 2380 Credit: 16,897,957,044 RAC: 0 Level Scientific publications |
this is something we can't know until GPUGRID recompiles the app for sm_86 with CUDA 11.1.That's why I started that sentence by "It seems..." it will also depend on what kinds of operations GPUGRID is doing. if they are mostly INT, then maybe not much improvement, but if they are FP32 heavy, we can expect to see a big improvement.It's the latter (FP32 heavy). However it's not the type of the data processed that decides if it can be processed simultaneously by two FP32 units within the same CUDA core, but the relation of the input-output data of that process. This relation is more complex than what I can comprehend (as of yet). it's just something that we need to wait for the app for. as I mentioned in my previous posts, you can't rely on that benchmark very strongly.The Folding@home app and the GPUGrid app are very similar regarding the data they process and the way they process it. Therefore I think this benchmark is the most accurate estimation we can have for now regarding the performance of the next GPUGrid app on Ampere cards. In other words: it would be a miracle if these science apps could be optimized to utilize all of the extra FP32 units. there are performance inconsistencies already between what it shows and what you can see here at GPUGRID (specifically as it relates to the performance between the V100 and the 2080ti)The largest "inconsistency" is that the RTX 3080 should have ~1500ns/day performance if the 8704 FP32 units could be utilized by the present FAH core22 v0.0.13 app. I assume that the RTX 3080 cards run nearly at their power limit already. Processing data on the extra FP32 units would take extra energy; however the data flow would be closer to optimal in this case, so it would lower the energy consumption at the same time. The ratio of these decide the actual performance gain of an optimized app, but -- based on my previous experience -- an FP32 operation is more energy hungry, than loading/storing the result. So, as being optimistic on that topic I expect another 10-15% performance boost at best from an Ampere-optimized app. |
|
Send message Joined: 21 Feb 20 Posts: 1117 Credit: 40,876,970,595 RAC: 0 Level Scientific publications |
was the F@h app compiled with SM_86? I couldn't find that info. as referenced in my previous comment from the nvidia documentation, that might be needed to get the full benefit from the double FP32 throughput. which is why I hope the app update includes the SM_86 gencode.
|
|
Send message Joined: 17 Aug 08 Posts: 2705 Credit: 1,311,122,549 RAC: 0 Level Scientific publications |
Toni, what about that suggestion of a "blind compile" for a beta app? Maybe the gambling pays off and it works right away or after minimal debugging? Very good point about the recompile. If the compiler does not try to use the extra FP32 units, then it's clear they won't be used. From the data they have it looks like the current F@H app was not compiled for Ampere, even though their scaling with GPU power seems way weaker than here at GPU-Grid. Maybe they have more sequential code. Generally I'm not as pessimistic as Zoltan about using those extra FP32 units. In no review have I read anything about restrictions on when they can be used (apart from the compiler). It's nothing like the superscalar units in Kepler and smaller Fermis, which were really hard to use due to being limited to thread level parallelism. However, there's an obvious catch: any other operation that the previous Turing SM could issue along FP32 (Int32, load, store, whatever) is also still going to be needed. And if these execute, the SM is already at maximum throughput and nothing can be gained by the additional FP32 units. Just from this a speedup in the range of 30 - 60% may be expected, but certainly not 100%. Just taking those numbers out of my stomach and random pieces of information I have seen here and there. MrS Scanning for our furry friends since Jan 2002 |
|
Send message Joined: 13 Dec 17 Posts: 1424 Credit: 9,189,946,190 RAC: 0 Level Scientific publications |
I think the existing app source code can just be recompiled with the new genarch parameters to get the app working like it already does with previous generations. To get the app working and use the extra FP32 pipeline, I think the app will need to be rewritten to add the PTX ISA JIT compiler that is in the new 11.1 CUDA toolkit. That seems to be the key component to parallelize the code to get the extra FP32 register working on compute. But just with the single FP32 register in play, we should see some pretty good enhancement just from the architecture changes. |
|
Send message Joined: 13 Dec 17 Posts: 1424 Credit: 9,189,946,190 RAC: 0 Level Scientific publications |
was the F@h app compiled with SM_86? I couldn't find that info. as referenced in my previous comment from the nvidia documentation, that might be needed to get the full benefit from the double FP32 throughput. What I can see of the finished PPSieve work done by the 3080, the app is still the same one introduced in 2019. So well before the release of CUDA 11.1 or the Ampere architecture. I have no idea why it can run with the older application. |
|
Send message Joined: 17 Aug 08 Posts: 2705 Credit: 1,311,122,549 RAC: 0 Level Scientific publications |
I have no idea why it can run with the older application. If the app is coded "high level enough" I could see this work out. If nothing hardware or generation specific is targeted, all you do is to tell the GPU "Go forth and multiply (this and that data)!". MrS Scanning for our furry friends since Jan 2002 |
|
Send message Joined: 13 Dec 17 Posts: 1424 Credit: 9,189,946,190 RAC: 0 Level Scientific publications |
I guess so. They must not have encoded a minimum or maximum level that can be used. Not looking for some specific bounds like the app here does and is currently finding the Ampere cards out of range. |
|
Send message Joined: 12 Jul 17 Posts: 404 Credit: 17,412,649,587 RAC: 39 Level Scientific publications |
At 320 Watts the PCIe cables and connectors will melt. I make my own PSU cables with a thicker gauge wire but those chintzy plastic PCIe connectors can't handle the heat. If you smell burnt electrical insulation or plastic that's the first place to check. |
|
Send message Joined: 13 Dec 17 Posts: 1424 Credit: 9,189,946,190 RAC: 0 Level Scientific publications |
A standard 8 pin PCIE cable can provide 150W. All the cards have either two or three 8 pin connectors which provide 300 or 450 watts PLUS the 75 watts from the PCIE slot. The founders edition cards have that new 12 pin connector which is just a duplicate capacity of two 8 pin connectors. Only six wires have 12V on them, the rest are grounds. The plastic connector housing has nothing to do with current capability. It is the wires and pins the provide that. |
|
ServicEnginIC Send message Joined: 24 Sep 10 Posts: 595 Credit: 13,083,686,510 RAC: 12,864 Level Scientific publications |
Pulling the blanket from the link in this eXaPower post... I arrived to this other interesting article about the new Nvidia 12 pin power connector. As Keith Myers remarks, it isn't a mere evolution of 6/8 pin current connectors, but a complete new specification. This new specification includes connector's shape, constructive materials, wires and pins gauges, and electrical ratings. On the paper, it might handle as much as 600 Watts... To general public: Please, don't test it with a bent paperclip! ;-) |
|
Send message Joined: 17 Aug 08 Posts: 2705 Credit: 1,311,122,549 RAC: 0 Level Scientific publications |
At 320 Watts the PCIe cables and connectors will melt. Have you checked the launch reviews and for that? And asked Google about forum posts from affected users? Tip: don't spend too much time searching. MrS Scanning for our furry friends since Jan 2002 |

©2026 Universitat Pompeu Fabra