Message boards : Number crunching : Managing non-high-end hosts
| Author | Message |
|---|---|
 ServicEnginIC ServicEnginICSend message Joined: 24 Sep 10 Posts: 581 Credit: 9,994,706,652 RAC: 19,061,528 Level Scientific publications | |
|
Managing non-high-end (slow) hosts | |
| ID: 57627 | Rating: 0 | rate:
| |
|
ServicEnginIC Send message Joined: 24 Sep 10 Posts: 581 Credit: 9,994,706,652 RAC: 19,061,528 Level Scientific publications | |
|
When you are commanding a fleet of assorted slow GPUs (in my case currently 8), it is difficult to hold in mind how long will it take for every of them to finish their tasks. | |
| ID: 57628 | Rating: 0 | rate:
| |
|
jjch Send message Joined: 10 Nov 13 Posts: 101 Credit: 15,635,779,580 RAC: 4,687,825 Level Scientific publications | |
|
The slowest GPU's that I am using for GPUgrid are GTX 1070's. These average about 36hrs to process on Windows hosts. | |
| ID: 57631 | Rating: 0 | rate:
| |
|
ServicEnginIC Send message Joined: 24 Sep 10 Posts: 581 Credit: 9,994,706,652 RAC: 19,061,528 Level Scientific publications | |
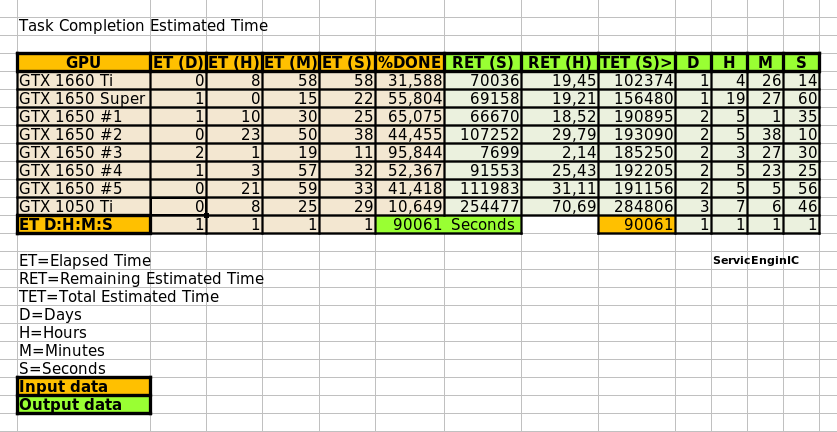
There comes a time when the technology outpaces the physical hardware we have available but I am a firm believer of using what we have as long as possible. Yeah, Watching an old table of my working GPUs on 2019: 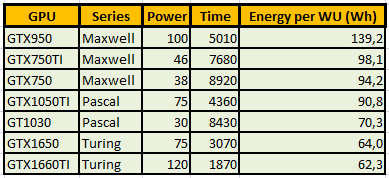 I published this table at Message # 52974, in "Low power GPUs performance comparative" thread. Since then, I've retired from production at Gpugrid all my Maxwell GPUs. GTX 750 and GTX 750 Ti for not being able to process the current ADRIA tasks inside the 5 days deadline. I estimate that GTX 950 could process them in about 3 days and 20 hours, but it doesn't worth it due to its low energetic efficiency. And Pascal GT 1030, I estimate that it would take about 6 days and 10 hours... Remember, I'm the guy with the "Ragtag fugitive fleet" of old HP/HPE servers and workstations that I have saved from the scrap pile. Unforgettable, since today you are at the top of Gpugrid Users ranking by RAC ;-) | |
| ID: 57632 | Rating: 0 | rate:
| |
|
I've been running these tasks on a 1060 6gb, they take 161,000 - 163,000 seconds to complete. I will keep running tasks on this card until it can no longer meet the deadlines, I've been trying to hit the billion point milestone which would take another year or so if I could reliably get work units. Lets hope I can still run this card for that long! | |
| ID: 57648 | Rating: 0 | rate:
| |
|
ServicEnginIC Send message Joined: 24 Sep 10 Posts: 581 Credit: 9,994,706,652 RAC: 19,061,528 Level Scientific publications | |
|
Some considerations about Gpugrid tasks deadlines: | |
| ID: 57701 | Rating: 0 | rate:
| |
|
jjch Send message Joined: 10 Nov 13 Posts: 101 Credit: 15,635,779,580 RAC: 4,687,825 Level Scientific publications | |
|
Well said ServicEnginIC | |
| ID: 57702 | Rating: 0 | rate:
| |
|
Erich56 Send message Joined: 1 Jan 15 Posts: 1132 Credit: 10,511,497,676 RAC: 26,098,279 Level Scientific publications | |
well, the point here is, that in many cases it's not just a matter of removing the "old" graphic card and putting in a new one. often enough (like with some of my rigs, too), new generation cards are not well compatible with the remaining old PC hardware. So, in many cases, in order to be up to date GPU-wise, it would mean to buy a new PC :-( | |
| ID: 57704 | Rating: 0 | rate:
| |
|
ServicEnginIC Send message Joined: 24 Sep 10 Posts: 581 Credit: 9,994,706,652 RAC: 19,061,528 Level Scientific publications | |
|
I fully agree, jjch. But anyway, I would not recommend buying the GT710 or GT730 anymore unless you need their very low consumption. | |
| ID: 57705 | Rating: 0 | rate:
| |
|
ServicEnginIC Send message Joined: 24 Sep 10 Posts: 581 Credit: 9,994,706,652 RAC: 19,061,528 Level Scientific publications | |
So, in many cases, in order to be up to date GPU-wise, it would mean to buy a new PC :-( Right. And I find it particularly annoying when trying to upgrade Windows hosts... As a hardware enthusiast, I've self-upgraded four of my Linux rigs from old socket LGA 775 Core 2 Quad processors and DDR3 RAM motherboards to new i3-i5-i7 processors and DDR4 RAM ones. I find Linux OS to be very resilient to this kind of changes, with usually no need to care more than upgrading the hardware. But one of them is a Linux/Windows 10 dual boot system. While Linux assumed the changes smoothly, I had to buy a new Windows 10 License to renew the previously existing... I related it in detail at my Message #55054, in "The hardware enthusiast's corner" thread. | |
| ID: 57707 | Rating: 0 | rate:
| |
|
ServicEnginIC Send message Joined: 24 Sep 10 Posts: 581 Credit: 9,994,706,652 RAC: 19,061,528 Level Scientific publications | |
|
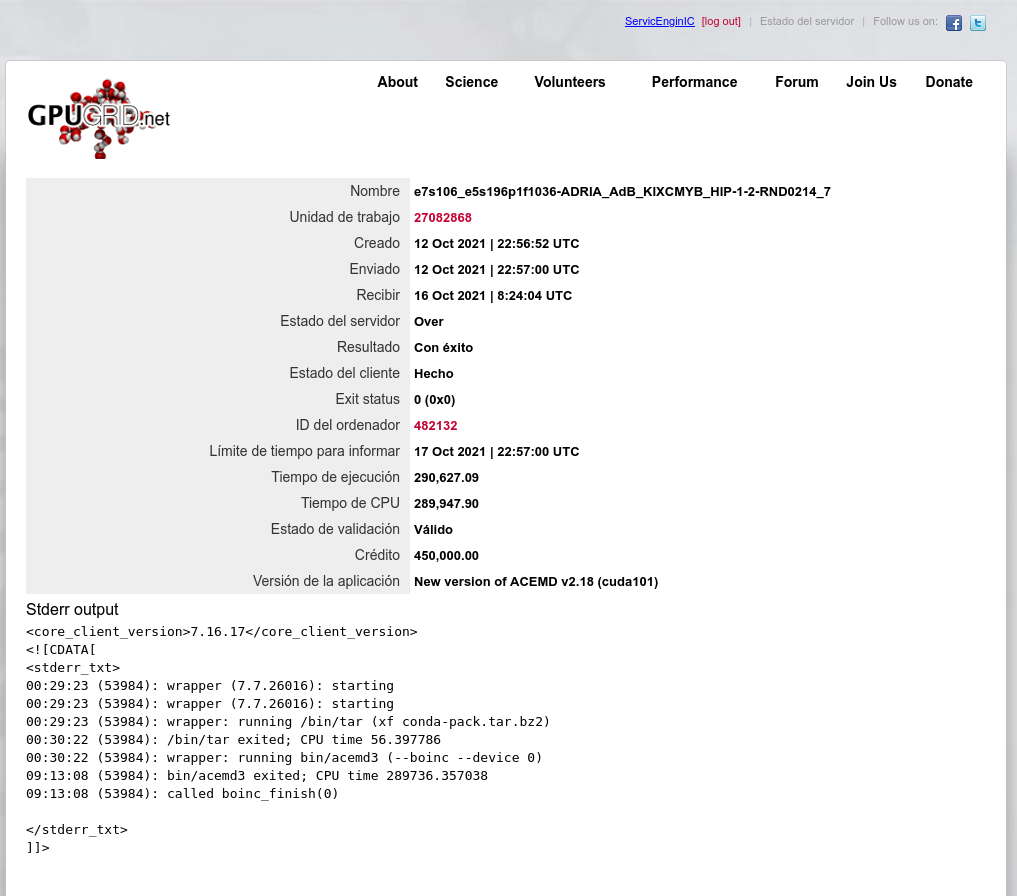
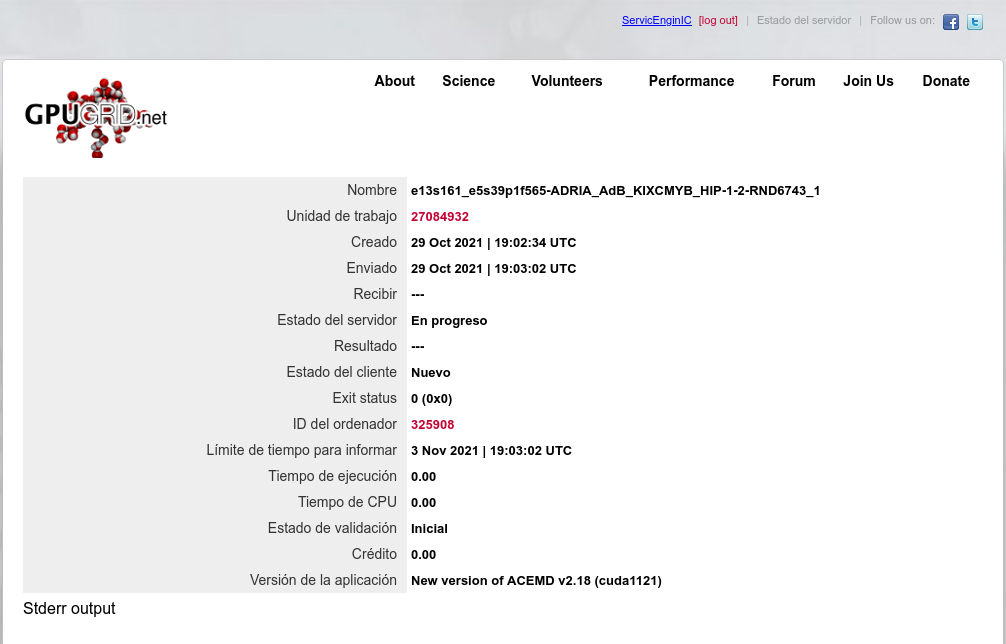
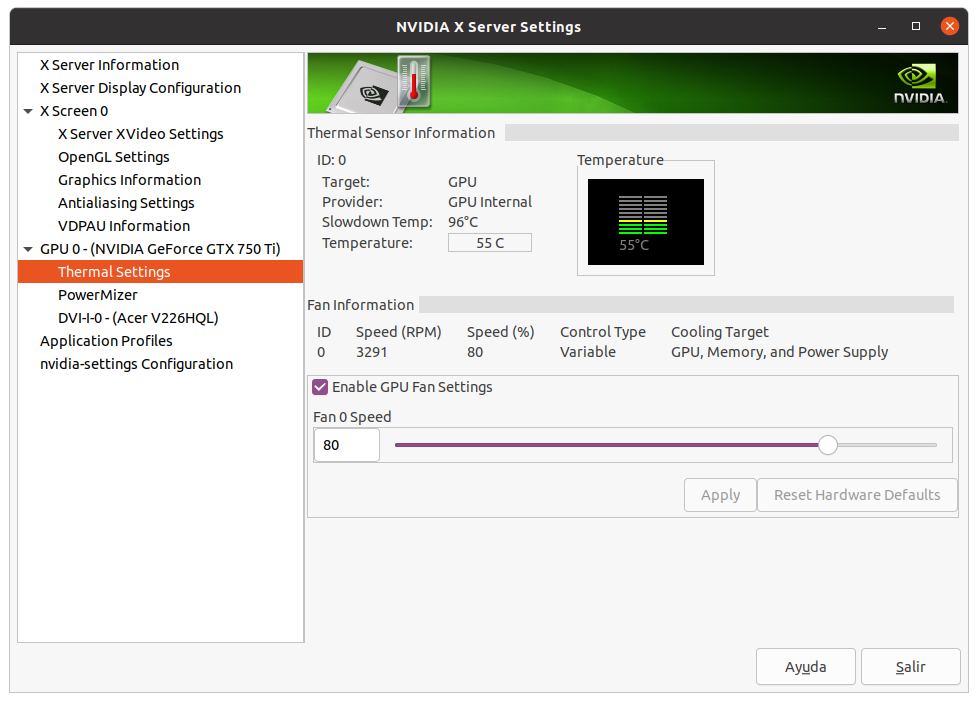
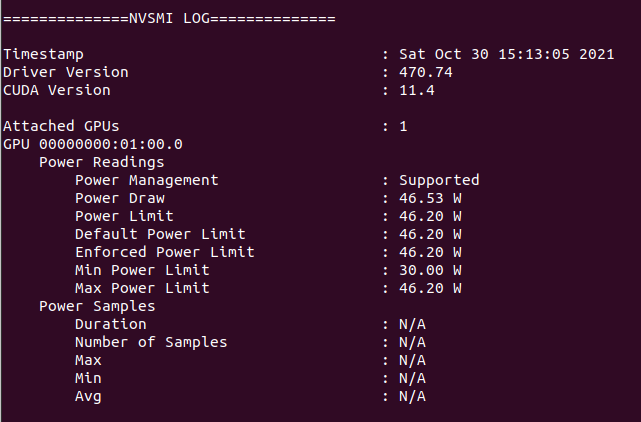
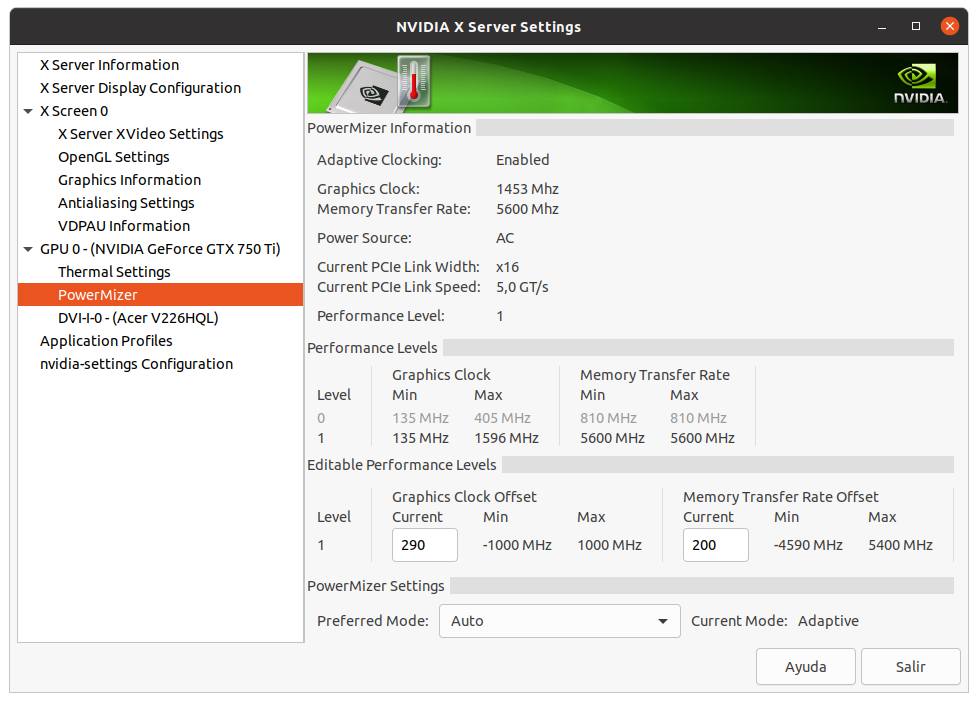
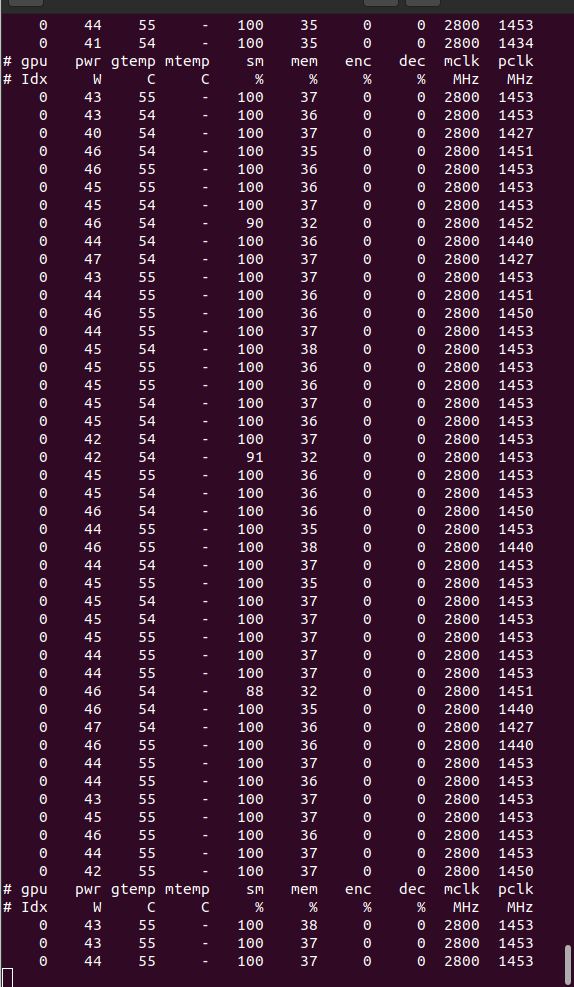
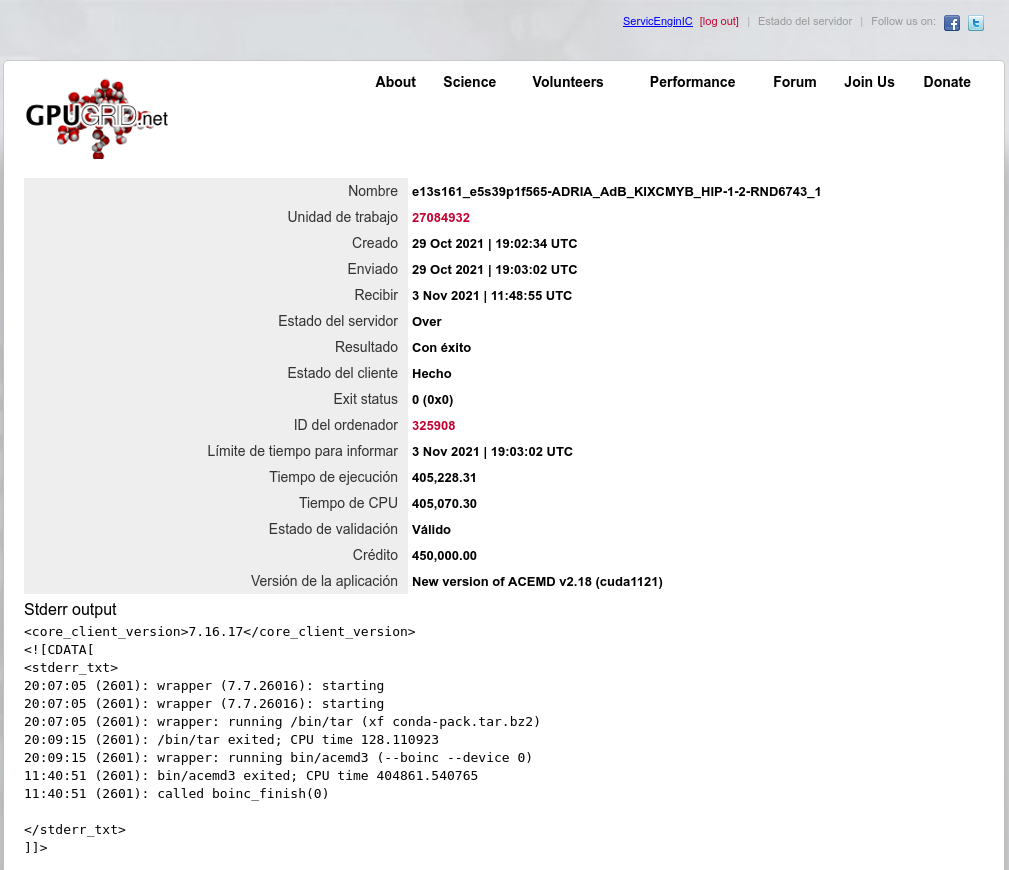
Overclocking to wacky (?) limits Conversely, if I'm successful, I'll publish the measures taken. I strongly doubt it, since I have to trim more than 13 hours in processing time 🎬⏱️ Well, we already have a verdict: Task e13s161_e5s39p1f565-ADRIA_AdB_KIXCMYB_HIP-1-2-RND6743_1 was sent to the mentioned Linux Host #325908 on 29 Oct 2021 at 19:03:02 UTC. This same host took 473615 seconds to process a previous task, and I did set myself the challenge of trimming more than 13 hours in processing time for fitting a new task into deadline. For achieving this, I've had to carefully study several strategies to apply, and I'll try to share with you everything I've learnt in the way. We're talking about a GV-N75TOC-2GI graphics card I've found this Gigabyte 46 Watts power consuming card being very tolerant to heavy overclocking, probably due to a good design and to its extra 6-pin power connector. Other manufacturers decide to take all the power from PCIe slot for cards consuming 75 Watts or less... This graphics card isn't its original shape. I had to refurbish its cooling system, as I related in my Message #55132 at "The hardware enthusiast's corner" thread. It is currently installed on an ASUS P5E3 PRO motherboard, also refurbished (Message #56488). Measures taken: The mentioned motherboard has two PCIe x16 V2.0 slots, Slot #0 occupied by the GTX 750 Ti graphics card, and Slot #1 remaining unused. For gaining the maximum bandwidth available for the GPU, I entered BIOS setup and disabled integrated PATA (IDE) interface, Sound, Ethernet, and RS232 ports. Communications are managed by a WiFi NIC, installed in one PCIe x1 slot, and storage is carried out by a SATA SSD. I also settled eXtreme Memory Profile (X.M.P) to ON, and Ai Clock Twister parameter to STRONG (highest performance available) Overclocking options had been previously enabled at this Ubuntu Linux host by means of the following Terminal command: sudo nvidia-xconfig --thermal-configuration-check --cool-bits=28 --enable-all-gpus It is a persistent command, and it is enough with executing it once. After that, entering Nvidia X Server Settings, options for adjusting fan curve and GPU and Memory frequency offsets will be available. First of all, I'm adjusting GPU Fan setting to 80%, thus enhancing refrigeration comparing to default fan curve. Then, I'll apply a +200 MHz offset to Memory clock, increasing from original 5400 MHz to a higher 5600 MHZ (GDDR 2800 MHz x 2). And finally, I'm gradually increasing GPU clock until power limit for the GPU is reached while working at full load. For determining the power limit, it is useful the following command: sudo nvidia-smi -q -d power For this particular graphics card, Power Limit is factory set at 46.20 W, and it coincides with the maximum allowed for this GTX 750 Ti kind of GPU. And final clock settings look this way. With this setup, let's look to an interesting redundancy check, by means of the following nvidia-smi GPU monitoring command: sudo nvidia-smi dmon As can be seen at previous link, GPU is consistently reaching a maximum frequency of 1453 MHz, and power consumptions of more than 40 Watts, frequently reaching 46 and even 47 Watts. Temperatures are maintaining a comfortable level of 54 to 55 ºC, and GPU usage is on 100% most of the time. That's good... as long as the processing maintains reliable... Will it? ⏳️🤔️ This new task e13s161_e5s39p1f565-ADRIA_AdB_KIXCMYB_HIP-1-2-RND6743_1 was processed by this heavily overclocked GTX 750 Ti GPU in 405229 seconds, and a valid result was returned on 03 Nov 2021 at 11:48:55 UTC Ok, I finally was able to trim the processing time in 68386 seconds. That is: 18 hours, 59 minutes and 46 seconds less than the previous task. It fit into deadline with an excess margin of 7 hours, 14 minutes and 7 seconds... (Transition from summer to winter time gave an extra hour this Sunday !-) Challenge completed! 🤗️ | |
| ID: 57736 | Rating: 0 | rate:
| |
|
ServicEnginIC Send message Joined: 24 Sep 10 Posts: 581 Credit: 9,994,706,652 RAC: 19,061,528 Level Scientific publications | |
|
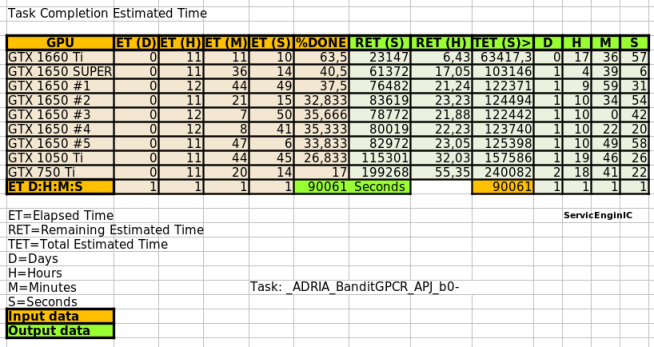
Yesterday, a new batch of tasks "_ADRIA_BanditGPCR_APJ_b0-" came out. | |
| ID: 57886 | Rating: 0 | rate:
| |
|
Erich56 Send message Joined: 1 Jan 15 Posts: 1132 Credit: 10,511,497,676 RAC: 26,098,279 Level Scientific publications | |
|
could it be that a GTX1650 is not able to crunch the current series of tasks? | |
| ID: 58021 | Rating: 0 | rate:
| |
|
Retvari Zoltan Send message Joined: 20 Jan 09 Posts: 2350 Credit: 16,296,378,479 RAC: 4,007,300 Level Scientific publications | |
could it be that a GTX1650 is not able to crunch the current series of tasks?I don't think so. Today, for the first time I tried GPUGRID on my host with a GTX1650 inside, and the task failed after some 4 hoursI can suggest only the ususal: check your GPU temperatures, lower the GPU frequency by 50MHz. | |
| ID: 58022 | Rating: 0 | rate:
| |
|
ServicEnginIC Send message Joined: 24 Sep 10 Posts: 581 Credit: 9,994,706,652 RAC: 19,061,528 Level Scientific publications | |
|
could it be that a GTX1650 is not able to crunch the current series of tasks? I'm processing current ADRIA tasks on five GTX 1650 graphics cards of varied brands and models. They're behaving rock stable, and getting mid bonus (valid result returned before 48 hours) when working 24/7. Perhaps a noticeable difference with yours is that all of them are working under Linux, where some variables as antivirus and other interfering software can be discarded... As always, Retvari Zoltan's wise advices are to be taken in mind. | |
| ID: 58023 | Rating: 0 | rate:
| |
|
Erich56 Send message Joined: 1 Jan 15 Posts: 1132 Credit: 10,511,497,676 RAC: 26,098,279 Level Scientific publications | |
|
well, the GPU temperature was at 60/61°C - so not too high, I would guess. | |
| ID: 58024 | Rating: 0 | rate:
| |
|
ServicEnginIC Send message Joined: 24 Sep 10 Posts: 581 Credit: 9,994,706,652 RAC: 19,061,528 Level Scientific publications | |
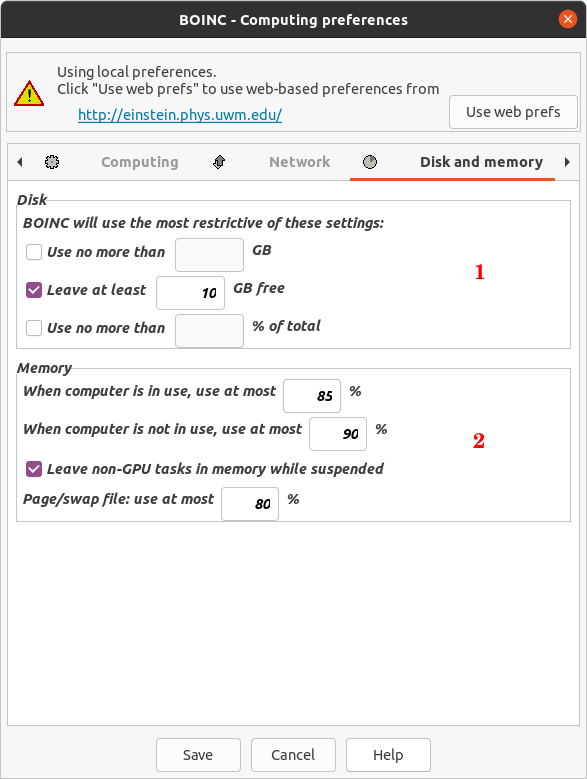
However, meanwhile my suspicion is that the old processor Surely you're right. For a two-core CPU, I'd recommend to set at BOINC Manager Computing preferences "Use at most 50 % of the CPUs". This will cause that one CPU core to remain free for feeding the GPU. | |
| ID: 58025 | Rating: 0 | rate:
| |
|
Erich56 Send message Joined: 1 Jan 15 Posts: 1132 Credit: 10,511,497,676 RAC: 26,098,279 Level Scientific publications | |
However, meanwhile my suspicion is that the old processor the question then though is: how long would it take a task to get finished? Probably 4-5 days :-( | |
| ID: 58026 | Rating: 0 | rate:
| |
|
ServicEnginIC Send message Joined: 24 Sep 10 Posts: 581 Credit: 9,994,706,652 RAC: 19,061,528 Level Scientific publications | |
|
Every of my five GTX 1650 graphics cards are currently taking less than 48 hours, in time for getting mid bonus (+25%). | |
| ID: 58028 | Rating: 0 | rate:
| |
|
Erich56 Send message Joined: 1 Jan 15 Posts: 1132 Credit: 10,511,497,676 RAC: 26,098,279 Level Scientific publications | |
Every of my five GTX 1650 graphics cards are currently taking less than 48 hours, in time for getting mid bonus (+25%). I just looked up your CPUs: they are generations newer than my old Intel Core 2 Duo CPU E7400 @ 2.80GHz I am afraid that these new series of GPUGRID tasks are demanding the old CPU too much :-( But, as said, I'll give it another try once new tasks become available. | |
| ID: 58029 | Rating: 0 | rate:
| |
|
Erich56 Send message Joined: 1 Jan 15 Posts: 1132 Credit: 10,511,497,676 RAC: 26,098,279 Level Scientific publications | |
But, as said, I'll give it another try once new tasks become available. As recommended, I set at BOINC Manager Computing preferences "Use at most 50 % of the CPUs", and I lowered the GPU frequency by 50 MHz. Now new tasks were downloaded, but they failed after less than a minute. What I noticed is that in the stderr it says: ACEMD failed: Particle coordinate is nan https://www.gpugrid.net/result.php?resultid=32722445 https://www.gpugrid.net/result.php?resultid=32722418 So the question now is: did my changes in the settings cause the tasks to fail that quickly after start, or are they misconfigured? BTW, at the same time another machine (with a CPU Intel Core i7-4930K and GTX980ti inside) got a new task, and this is working well. This could indicate that the tasks are NOT misconfigured, but that rather the changes in the settings are the reason for failure. No idea. | |
| ID: 58030 | Rating: 0 | rate:
| |
|
Ian&Steve C. Send message Joined: 21 Feb 20 Posts: 1074 Credit: 40,231,533,983 RAC: 161 Level Scientific publications | |
|
Firstly, I don't think your issue that you experienced is related to overclock or GPU temps at all, usually if temps or OC are the culprit you'll get a particle coordinate is nan error (but the nan error can also be a bad WU and not your fault, more on that later). Your error was a CUDA timeout. likely the driver crashed and the app couldn't hook back in. I'm on the fence if your CPU is the ultimate reason for this or not. certainly it's a very old platform to be running on Windows 10, so it's possible there are some issues. If your comfortable trying Linux, particularly a lightweight version with less system overhead, you might try that to see if you have a better experience with such an old system. | |
| ID: 58031 | Rating: 0 | rate:
| |
|
Erich56 Send message Joined: 1 Jan 15 Posts: 1132 Credit: 10,511,497,676 RAC: 26,098,279 Level Scientific publications | |
|
Ian&Steve C., thanks for the thorough explanations. | |
| ID: 58032 | Rating: 0 | rate:
| |
|
Ian&Steve C. Send message Joined: 21 Feb 20 Posts: 1074 Credit: 40,231,533,983 RAC: 161 Level Scientific publications | |
|
The very first thing I would recommend you try is to totally wipe out your existing nvidia drivers with DDU: https://www.guru3d.com/files-details/display-driver-uninstaller-download.html | |
| ID: 58033 | Rating: 0 | rate:
| |
|
Keith Myers  Send message Joined: 13 Dec 17 Posts: 1352 Credit: 7,771,422,334 RAC: 10,333,081 Level Scientific publications | |
|
Big slug of bad work went out with NaN errors. | |
| ID: 58035 | Rating: 0 | rate:
| |
|
Both my GTX 1060 on a Windows 10 host and GTX 1650 on a Windows 11 host have completed and validated their tasks. | |
| ID: 58039 | Rating: 0 | rate:
| |
|
Retvari Zoltan Send message Joined: 20 Jan 09 Posts: 2350 Credit: 16,296,378,479 RAC: 4,007,300 Level Scientific publications | |
However, meanwhile my suspicion is that the old processorI've reanimated (that was quite an adventure on its own) one ancient DQ45CB motherboard with a Core2Duo E8500 CPU in it, and I've put a GTX 1080Ti in it to test with GPUGrid, but there's no work available at the moment. You can follow the unfolding of this adventure here. EDIT: I've managed to receive one task... EDIT2: It failed because I've forget to install the Visual C++ runtime :( | |
| ID: 58049 | Rating: 0 | rate:
| |
|
Retvari Zoltan Send message Joined: 20 Jan 09 Posts: 2350 Credit: 16,296,378,479 RAC: 4,007,300 Level Scientific publications | |
|
I was lucky again, the host received another workunit and it's running just fine for 90 minutes. (it needs another 12 hours to complete). | |
| ID: 58055 | Rating: 0 | rate:
| |
|
Erich56 Send message Joined: 1 Jan 15 Posts: 1132 Credit: 10,511,497,676 RAC: 26,098,279 Level Scientific publications | |
However, meanwhile my suspicion is that the old processorI've reanimated (that was quite an adventure on its own) one ancient DQ45CB motherboard with a Core2Duo E8500 CPU in it, and I've put a GTX 1080Ti in it to test with GPUGrid, but there's no work available at the moment. You can follow the unfolding of this adventure here. hm, I could try to run a GPUGRID task on my still existing box with a CPU Intel Core2Duo E8400 inside, motherboard is an Abit IP35Pro, GPU is a GTX970. Currently, this box crunches FAH and/or WCG (GPU tasks), without problems. However, the GTX970 gets very warm (although I dedusted it recently), so for FAH I have to underclock to about 700MHz which is far below the default clock of 1152MHz. I am afraid same would be true for GPUGRID, and a task would run, if at all, forever. | |
| ID: 58063 | Rating: 0 | rate:
| |
|
Retvari Zoltan Send message Joined: 20 Jan 09 Posts: 2350 Credit: 16,296,378,479 RAC: 4,007,300 Level Scientific publications | |
|
The task is finihed successfully in 12h 35m 23s. | |
| ID: 58065 | Rating: 0 | rate:
| |
|
Erich56 Send message Joined: 1 Jan 15 Posts: 1132 Credit: 10,511,497,676 RAC: 26,098,279 Level Scientific publications | |
I've noticed that the present acemd3 app does not use a full CPU core (thread) on Windows while it does on Linux. There's a discrepancy between the run time and the CPU time, also the CPU usage is lower on Windows. hm, I acutally cannot confirm, see here: e7s141_e3s56p0f226-ADRIA_BanditGPCR_APJ_b1-0-1-RND0691_0 27100764 588817 10 Dec 2021 | 12:29:46 UTC 11 Dec 2021 | 5:50:18 UTC Fertig und Bestätigt 31,250.27 31,228.75 420,000.00 New version of ACEMD v2.19 (cuda1121) | |
| ID: 58068 | Rating: 0 | rate:
| |
|
Retvari Zoltan Send message Joined: 20 Jan 09 Posts: 2350 Credit: 16,296,378,479 RAC: 4,007,300 Level Scientific publications | |
The discrepancy is smaller in some cases, perhaps it depends on more factors than the OS. Newer CPUs show less discrepancy. I'll test it with my E8500. Now I'm using Windows 11 on it, but I couldn't get a new workunit yet. My next attempt will be with Linux.I've noticed that the present acemd3 app does not use a full CPU core (thread) on Windows while it does on Linux. There's a discrepancy between the run time and the CPU time, also the CPU usage is lower on Windows. | |
| ID: 58070 | Rating: 0 | rate:
| |
|
ServicEnginIC Send message Joined: 24 Sep 10 Posts: 581 Credit: 9,994,706,652 RAC: 19,061,528 Level Scientific publications | |
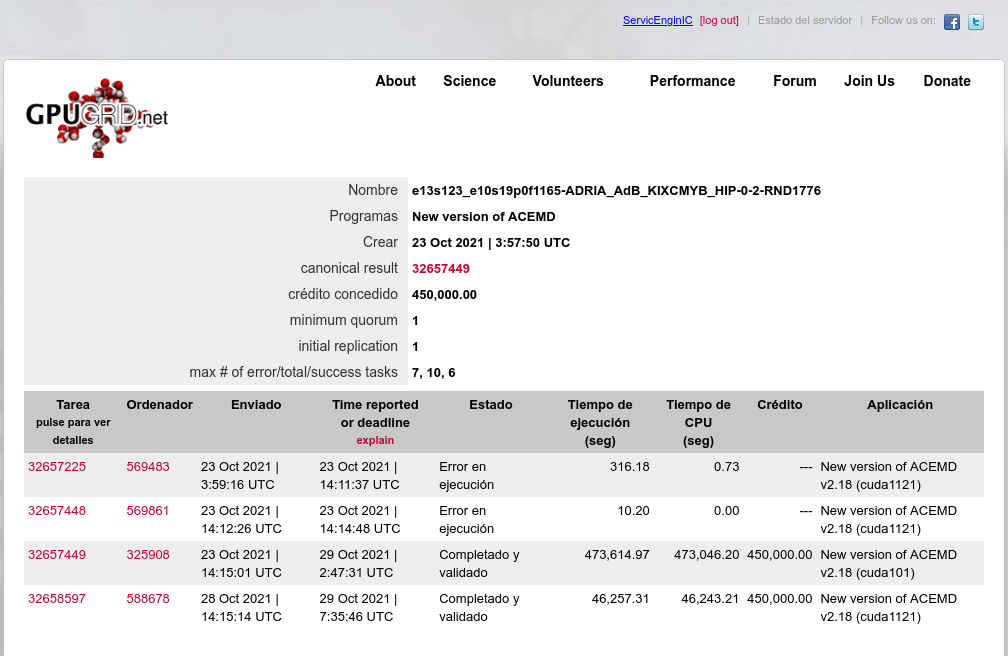
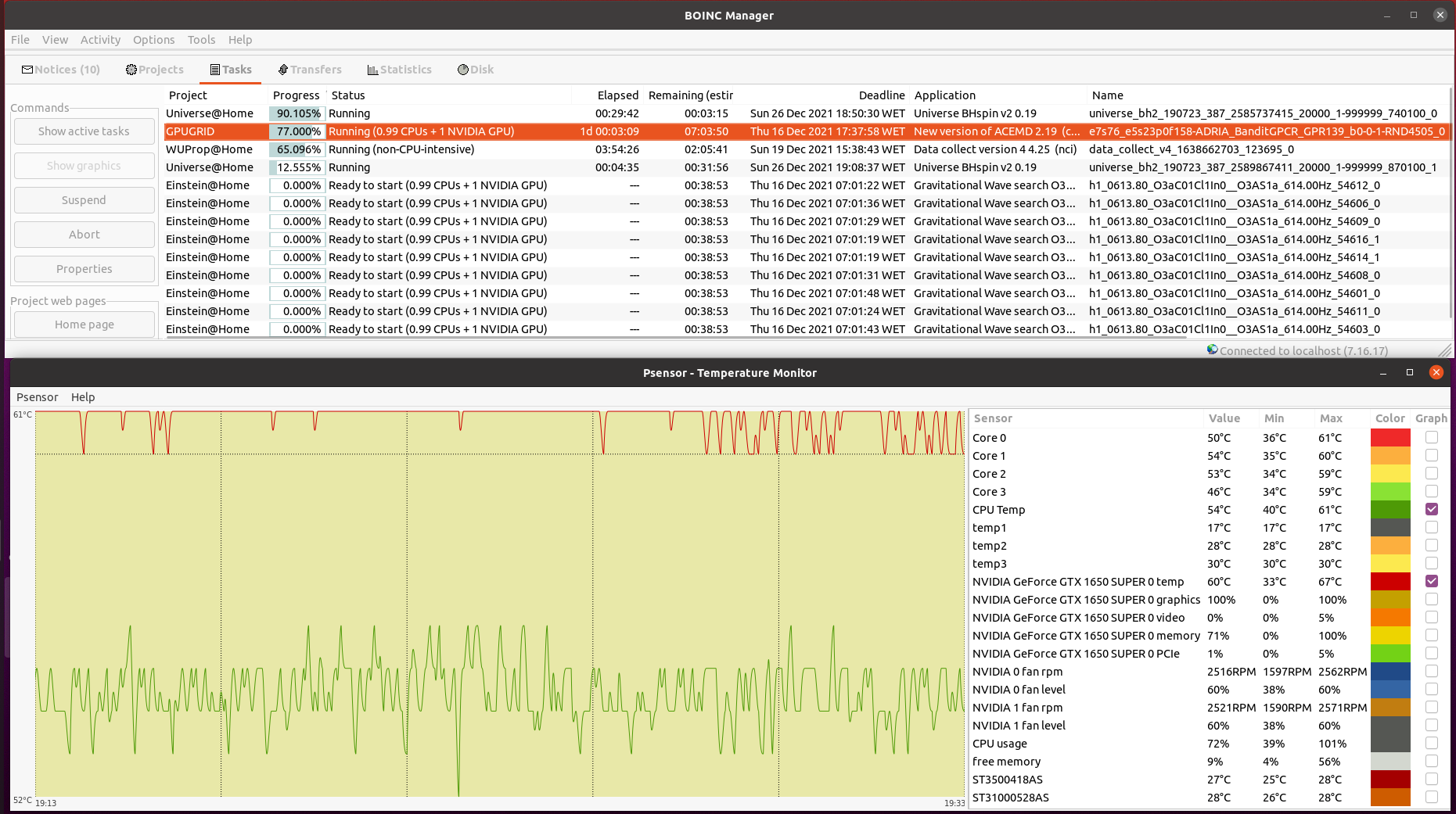
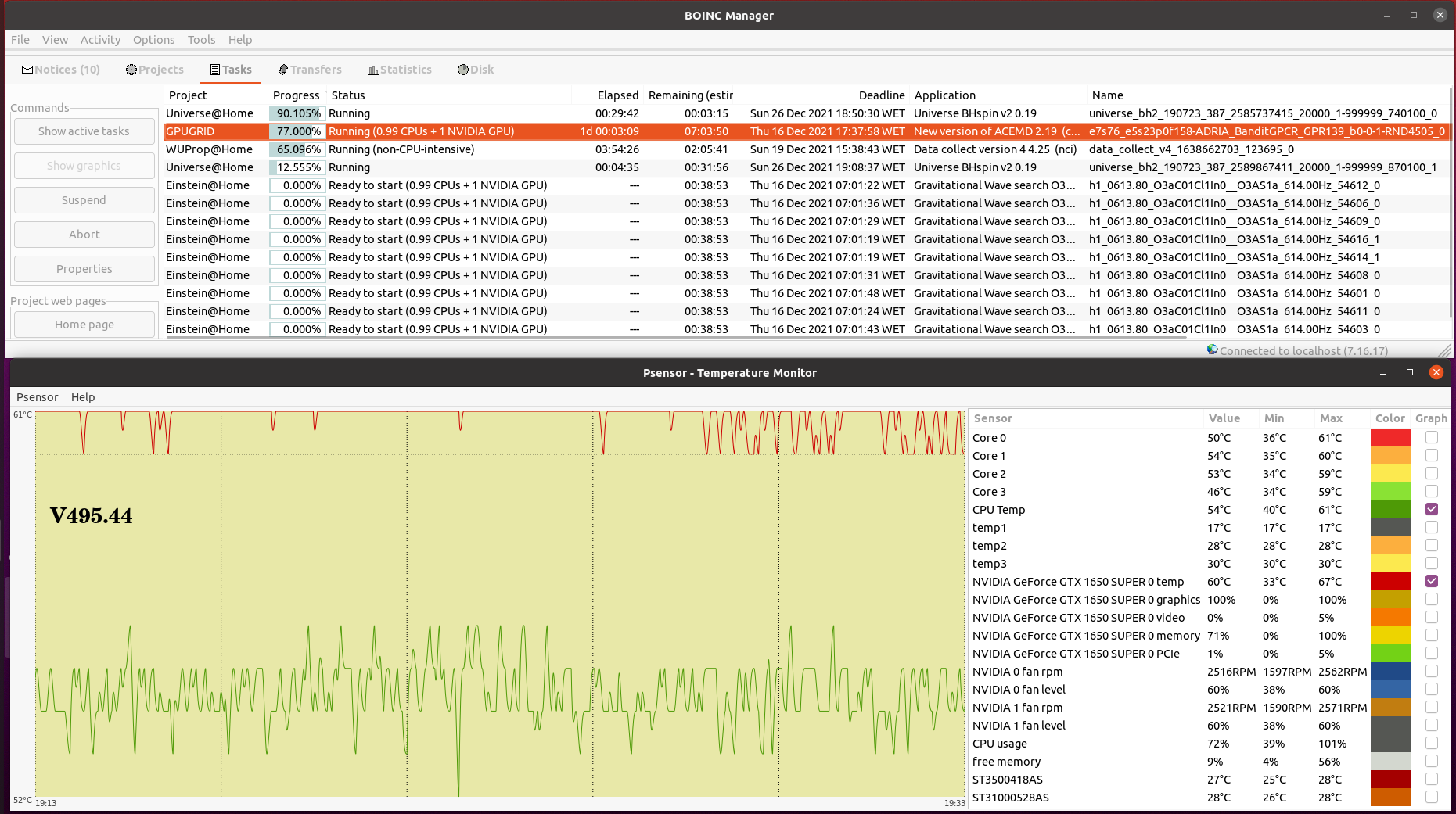
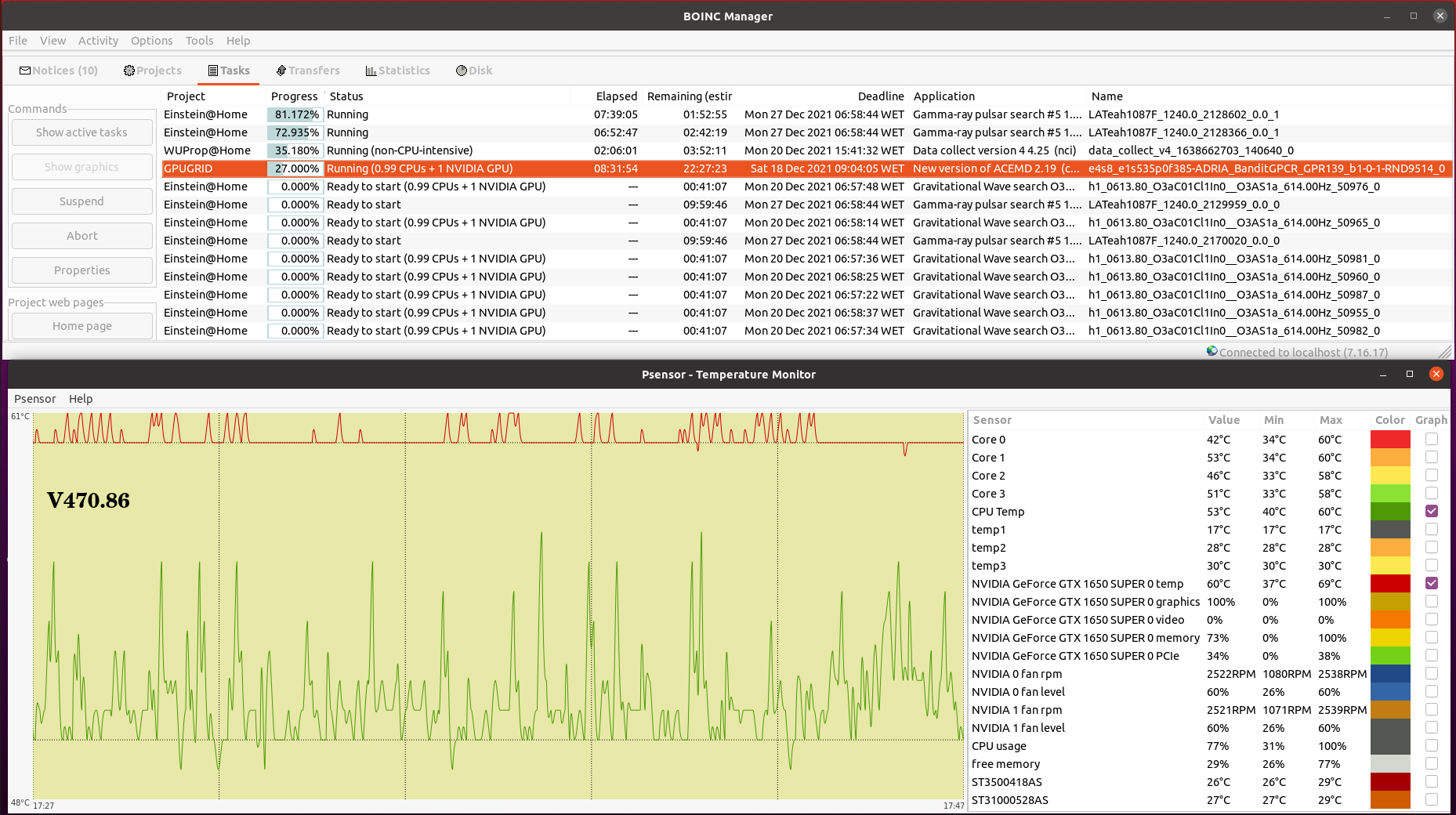
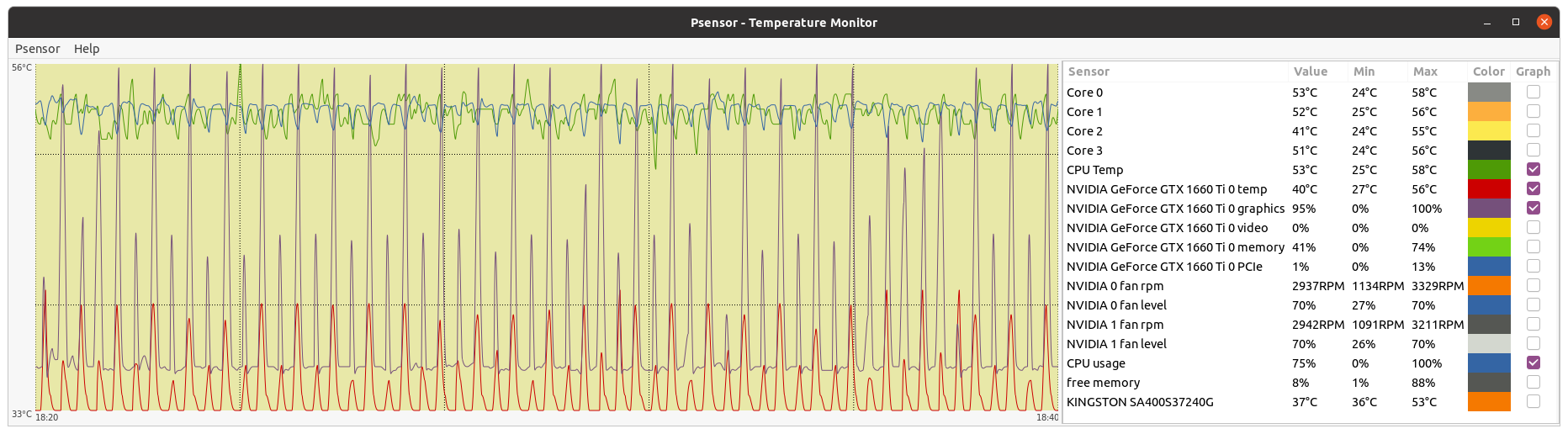
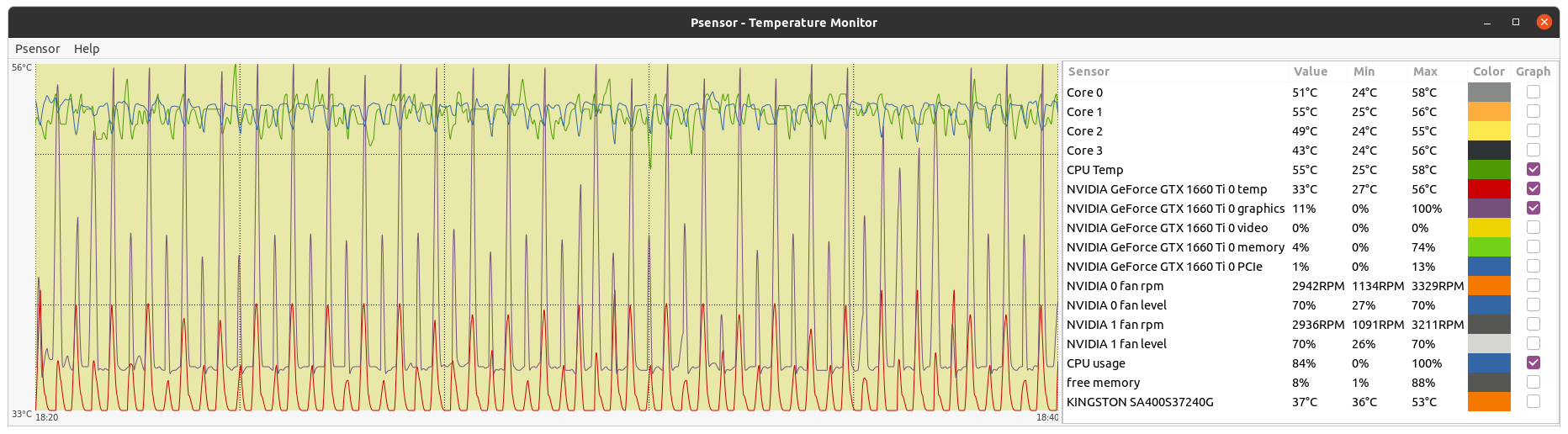
Your CPU being a Core2Duo, this architecture does not have a dedicated PCIe link to the CPU. it uses the older architecture where the PCIe and memory connect to the Northbridge chipset and the chipset is what has a single 10.6GB/s link to the CPU, the memory will take most of this bandwidth unfortunately, and since GPUGRID is pretty heavy on bus use, I can see some conflicts happening on this kind of architecture. but the CPU power itself shouldnt be an issue if you're trying to run 1 GPU and no CPU work. Inspired on your timely appointment, I've worked for experimenting the difference between newer dedicated PCIe link architecture versus the older based on an intermediate chipset. I have still in production Two Linux hosts based on the older architecture, same Asus P5E3 PRO motherboard. Main characteristics are: Intel X48/ICH9R chipset, DDR3 RAM, PCIe rev. 2.0, CPU socket LGA775 (the same as previously mentioned Core 2 Duo E7400 and E8500 CPUs) - Host #482132 - Host #325908 Both hosts are also based on the same low power Intel Core 2 Quad Q9550S CPU Host #482132 is harboring an Asus EX-GTX1050TI-4G graphics card (GTX 1050 Ti GPU) Host #325908 mounts a Gigabyte GV-N75TOC-2GI graphics card (GTX 750 Ti GPU) Psensor utility graphics for both hosts are the following (Gpugrid task running at each one): Host #482132: 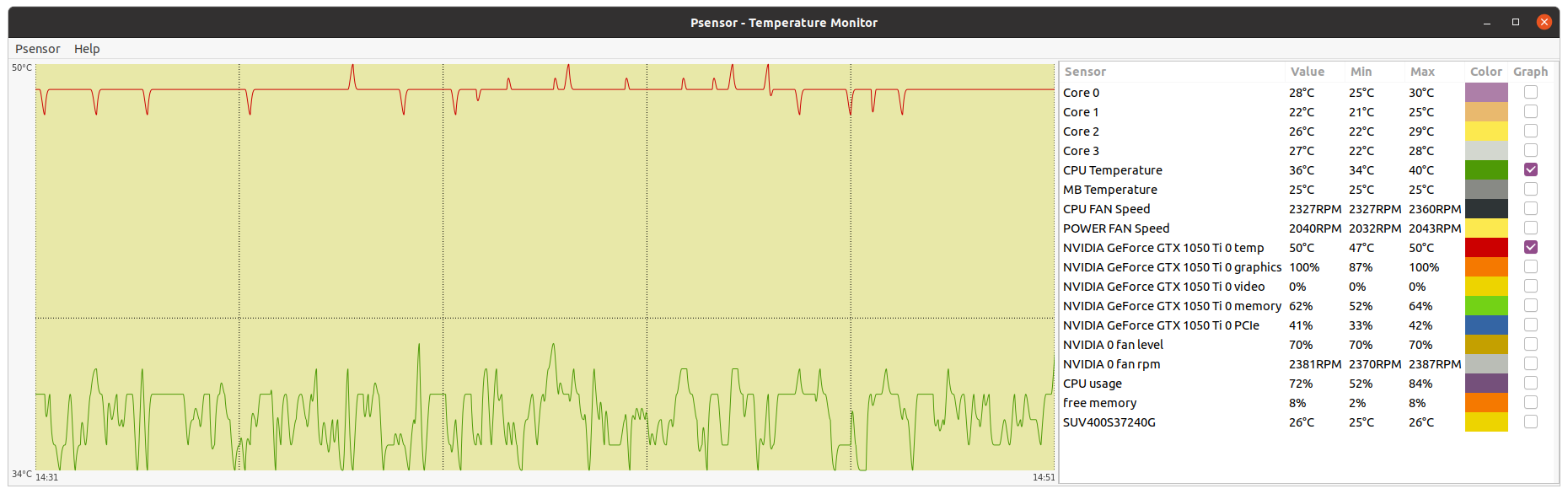 Host #325908:  Before going further, let's mention that Q9550S CPU TDP is 65 Watts, and that CPU series worked at fixed clock frequencies, 2,83 GHz in this case, so no power increase due to any turbo frequencies. This allows to easy maintain full load CPU temperatures at low levels, around 40 ºC. Also GPU TPDs are relatively low: 75 Watts for GTX 1050 Ti, and 46 Watts for GTX 750 Ti respectively. This helps to maintain their full-load temperatures at around 50 ºC, even being overclocked as they are. Now, for comparison, I'll take one of my newly refurbished hosts, Host #557889. It is based on the newer architecture with dedicated PCIe link to the CPU, Gigabyte Z390UD motherboard Main characteristics are: Intel Z390 chipset, DDR4 RAM, PCIe rev. 3.0, CPU socket LGA1151. This host mounts a 9th generation Intel Core i5-9400F CPU. Rated TDP for this processor is also 65 Watts at 2,90 GHz base clock frequency, but here come in play increased power consumptions due to higher turbo frequencies up to 4,10 GHz... Two of the three mainboard available PCIe slots are occupied by GTX 1650 GPU based graphics cards. Psensor utility graphic for this host is the following (2X Gpugrid tasks running, one at each GPU): Host #325908: 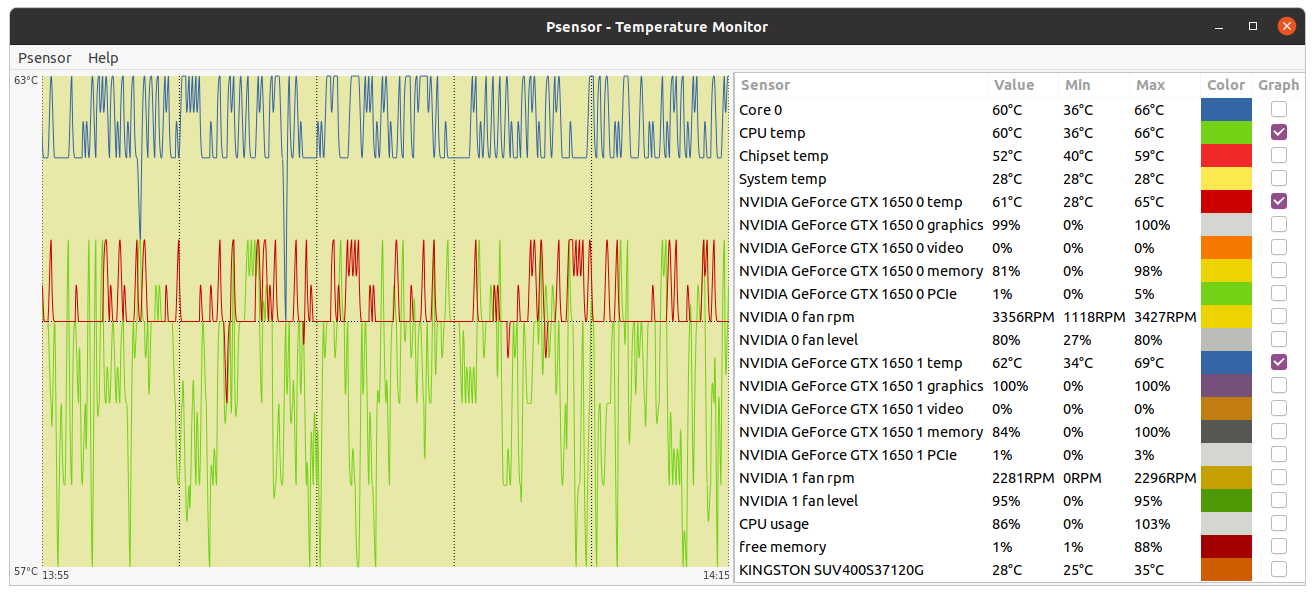 A general temperature rising at this host can be observed, due to the mentioned extra CPU power consumption, and the higher density (Two graphics cards) in the same computer case. And here is the conclusion we were looking for: While older architecture used respectively 41% and 36% of PCIe 2.0 bandwidth, the newer architecture is properly feeding two GPUs with only 1% to 2% PCIe 3.0 bandwidth usage each one. But it seems not to be an impediment for the older architecture to reliably manage the current ADRIA Gpugrid tasks...Slow but safe. | |
| ID: 58076 | Rating: 0 | rate:
| |
|
Ian&Steve C. Send message Joined: 21 Feb 20 Posts: 1074 Credit: 40,231,533,983 RAC: 161 Level Scientific publications | |
|
it would be a better comparison to run the same GPU on both systems for a more apples to apples comparison. | |
| ID: 58080 | Rating: 0 | rate:
| |
|
ServicEnginIC Send message Joined: 24 Sep 10 Posts: 581 Credit: 9,994,706,652 RAC: 19,061,528 Level Scientific publications | |
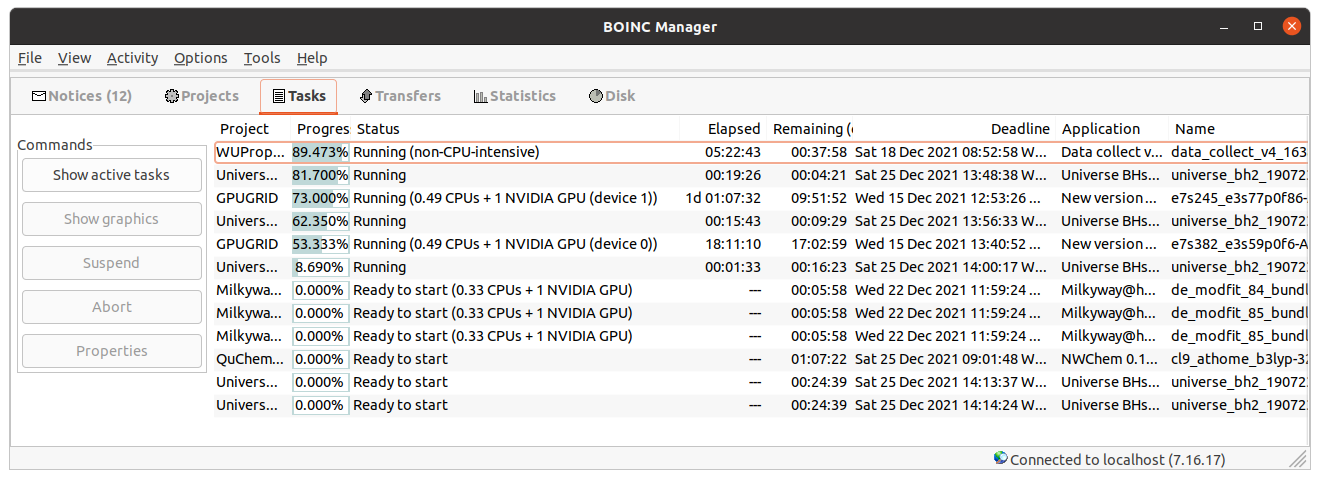
something about your 1% PCIe use doesnt seem right. Thank you for your kind comments. I enjoy reading every of them. I'm also somehow bewildered about it. I've noted such a PCIe bandwidth usage reduction at my newer hosts after New version of ACEMD 2.19 was launched on November 10th. Every of my four 9th generation i3-i5-i7 hosts are experiencing the same. At the moment of taking the presented Psensor graphic, GPU0 was executing task e7s382_e3s59p0f6-ADRIA_BanditGPCR_APJ_b1-0-1-RND7973_0, and GPU1 was executing task e7s245_e3s77p0f86-ADRIA_BanditGPCR_APJ_b1-0-1-RND1745_0 At the same moment, I took this Boinc Manager screenshot. Additionally, at the host I'm writing this on, I've just taken this combined Boinc Manager - Psensor image. As can be seen, at this i3-9100F CPU / GTX 1650 SUPER GPU host, the behavior is very similar. other than PCIe generation (3.0), what are the link widths for each card? how do you have them populated? I'm assuming the two topmost slots? that should be x16 and x4 respectively You're right. At this particular Gigabyte Z390UD motherboard, graphics card installed at PCIe 3.0 slot 0 runs at X8 link width, while graphics card installed at PCIe slot 1 (and any eventually installed at PCIe slot 2) runs at X4. At my most productive Host #480458, based on i7-9700F CPU / 3X GTX 1650 GPUs, all the three PCIe slots are used that way. | |
| ID: 58089 | Rating: 0 | rate:
| |
|
Ian&Steve C. Send message Joined: 21 Feb 20 Posts: 1074 Credit: 40,231,533,983 RAC: 161 Level Scientific publications | |
|
One thing that I just noticed. All of your hosts are running the New Feature Branch 495 drivers. These are “kinda-sorta” beta and the recommended driver branch is still the 470 branch. So I wonder if this is just a reporting issue. Does the Nvidia-Settings application report the same PCIe value as Psensor? | |
| ID: 58090 | Rating: 0 | rate:
| |
|
ServicEnginIC Send message Joined: 24 Sep 10 Posts: 581 Credit: 9,994,706,652 RAC: 19,061,528 Level Scientific publications | |
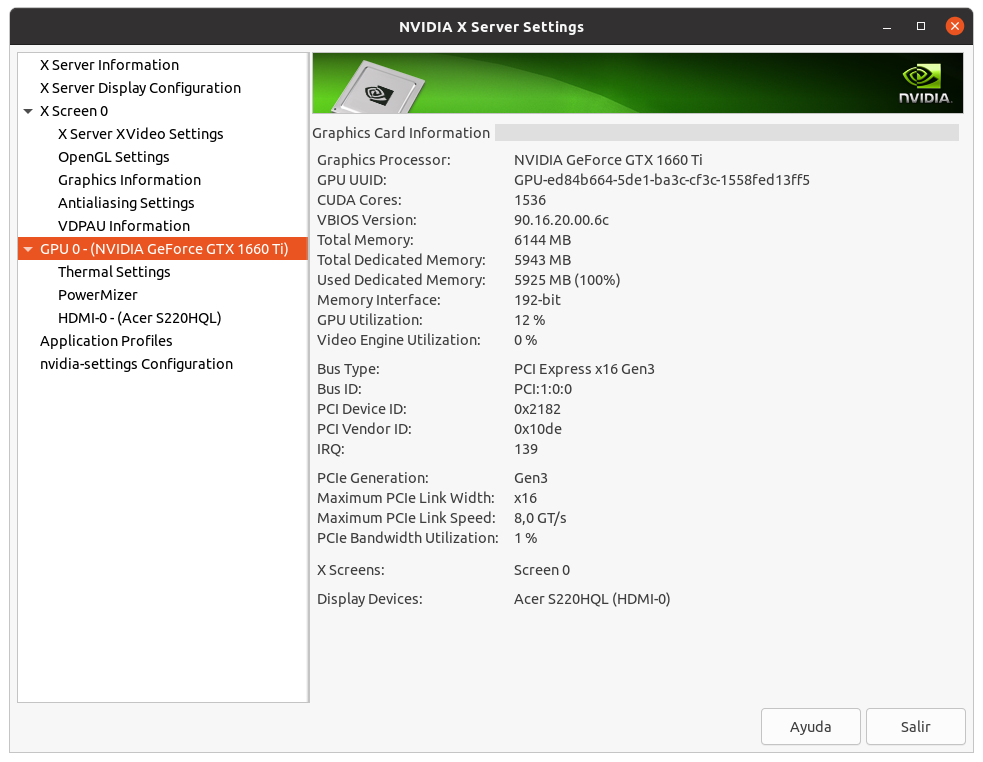
One thing that I just noticed. All of your hosts are running the New Feature Branch 495 drivers Good punctualization. In the interim between New version of ACEMD 2.18 and 2.19, I took the opportunity to update Nvidia drivers to version 495 at all my hosts. But I have no time left today for more than this: 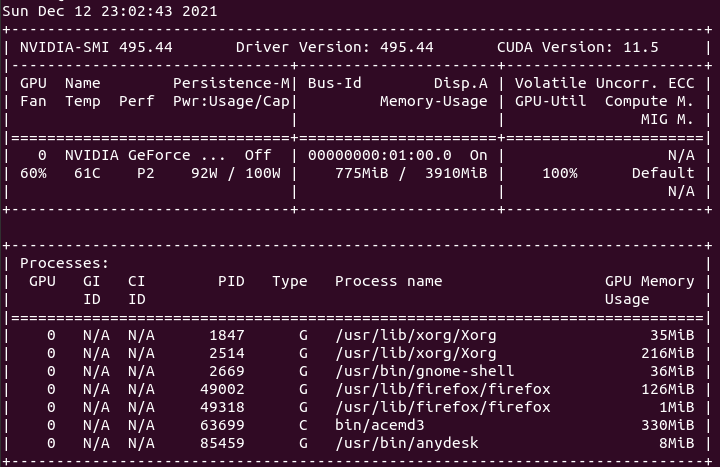 and this: 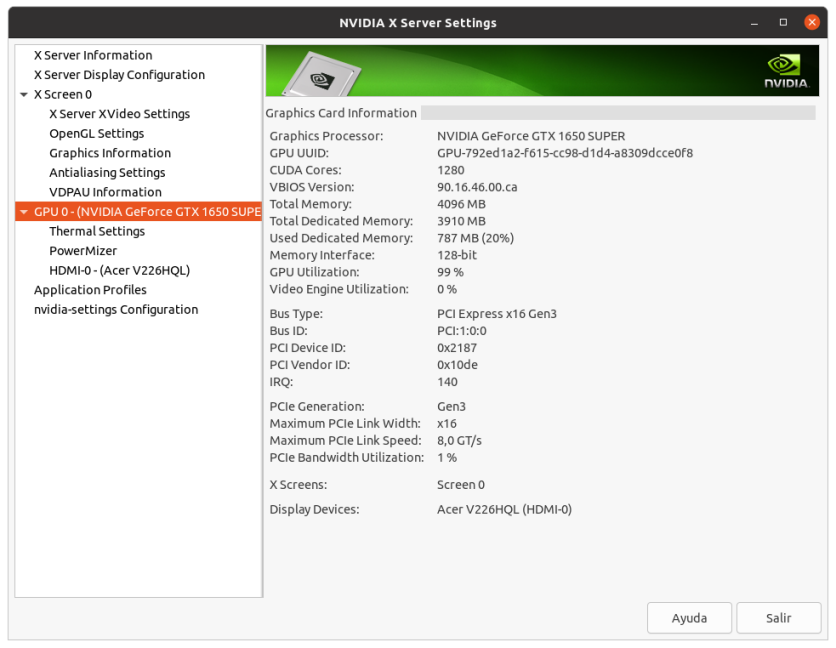 from my Host #186626 ... | |
| ID: 58091 | Rating: 0 | rate:
| |
|
Ian&Steve C. Send message Joined: 21 Feb 20 Posts: 1074 Credit: 40,231,533,983 RAC: 161 Level Scientific publications | |
|
Good to know that psensor is at least still reading the correct value from the new driver. | |
| ID: 58092 | Rating: 0 | rate:
| |
|
ServicEnginIC Send message Joined: 24 Sep 10 Posts: 581 Credit: 9,994,706,652 RAC: 19,061,528 Level Scientific publications | |
Definitely interested to know if the reading goes back after the switch back to 470 when you have time. I am too. But I've experienced that there is a sure Gpugrid task crash when Nvidia driver update is done and the task is restarted. It crashes with the same error that when a task is restarted in a different device on a multi-GPU host. Luckily, my Host #186626, finished its Gpugrid task overnight, so I've reverted it to Nvidia Driver Version 470.86 Curious that PCIe load reduction is only reflected in my newer systems. As shown, PCIe usage at older ones remains about the same than usual. Now waiting to receive some (currently scarce) new task... | |
| ID: 58093 | Rating: 0 | rate:
| |
|
Aurum Send message Joined: 12 Jul 17 Posts: 401 Credit: 16,755,010,632 RAC: 67,080 Level Scientific publications | |
One thing that I just noticed. All of your hosts are running the New Feature Branch 495 drivers. These are “kinda-sorta” beta and the recommended driver branch is still the 470 branch. So I wonder if this is just a reporting issue. Does the Nvidia-Settings application report the same PCIe value as Psensor? I updated my driver on a couple of computers to 495 thinking higher is better. There was something hinky about it, I believe it reported something wrong. Then I read the nvidia driver page and sure enough it's beta so I reverted to 470.86 and will stick with the repository recommended driver. Linux Mint has another strange quirk. If you leave it to the update manager it will give you the oldest kernel, now 5.4.0-91. If you click on the 5.13 tab and then one of the kernels and install it from then on it will keep you updated to the latest kernel, now 5.13.0-22. I don't know if this is a wise thing to do or if I'm now running a beta kernel. | |
| ID: 58094 | Rating: 0 | rate:
| |
|
Ian&Steve C. Send message Joined: 21 Feb 20 Posts: 1074 Credit: 40,231,533,983 RAC: 161 Level Scientific publications | |
Definitely interested to know if the reading goes back after the switch back to 470 when you have time. I see that you picked up a task today :) ____________  | |
| ID: 58096 | Rating: 0 | rate:
| |
|
Keith Myers Send message Joined: 13 Dec 17 Posts: 1352 Credit: 7,771,422,334 RAC: 10,333,081 Level Scientific publications | |
|
The later kernels are not necessarily considered beta. In fact the latest stable kernel is 5.15.7 as per the kernel.org site. https://www.kernel.org/ | |
| ID: 58098 | Rating: 0 | rate:
| |
|
ServicEnginIC Send message Joined: 24 Sep 10 Posts: 581 Credit: 9,994,706,652 RAC: 19,061,528 Level Scientific publications | |
I see that you picked up a task today :) Yes! They come and go, and I caught one today :) Ctrl + click over next two links, and new browser tabs will open for direct comparison between Nvidia Driver Version: 495.44 and Nvidia Driver Version: 470.86 at the same Host #186626. You're usually very insightful in your analysis. There is a drastic change in notified PCIe % usage between Regular Driver Branch V470.86 (31-37 %) and New Feature Driver Branch V495.44 (0-2 %) on this PCIe rev. 3.0 x16 test host. Now, immediately, a new question arises: Is it due to some bug at measuring/notifying algorithm on this new driver branch, or is it due to a true improvement in PCIe bandwidth management? I suppose that Nvidia driver developers usually have no time to read forums like this for clarifying... (?) By the moment, I don't know if I'll keep in using V470 or I'll reinstall V495. It will depend on processing times be better or worse. In a few days with steady work I'll collect enough data to evaluate and decide. | |
| ID: 58099 | Rating: 0 | rate:
| |
|
Ian&Steve C. Send message Joined: 21 Feb 20 Posts: 1074 Credit: 40,231,533,983 RAC: 161 Level Scientific publications | |
|
glad to see my hunch about the driver being the culprit was correct. | |
| ID: 58101 | Rating: 0 | rate:
| |
|
Keith Myers Send message Joined: 13 Dec 17 Posts: 1352 Credit: 7,771,422,334 RAC: 10,333,081 Level Scientific publications | |
|
The Nvidia 495.46 driver isn't considered a beta release now. Just a New Feature branch. | |
| ID: 58102 | Rating: 0 | rate:
| |
|
Ian&Steve C. Send message Joined: 21 Feb 20 Posts: 1074 Credit: 40,231,533,983 RAC: 161 Level Scientific publications | |
|
I dont think the PCIe use at 1% is "real". I think it's just misreporting the real value. GBM doesnt seem to have anything to do with PCIe traffic. that would be up to the app. It seems the app is coded to store a bunch of stuff in system memory rather than GPU memory and it's constantly sending data back and forth. this is up to the app, not the driver. | |
| ID: 58103 | Rating: 0 | rate:
| |
|
ServicEnginIC Send message Joined: 24 Sep 10 Posts: 581 Credit: 9,994,706,652 RAC: 19,061,528 Level Scientific publications | |
|
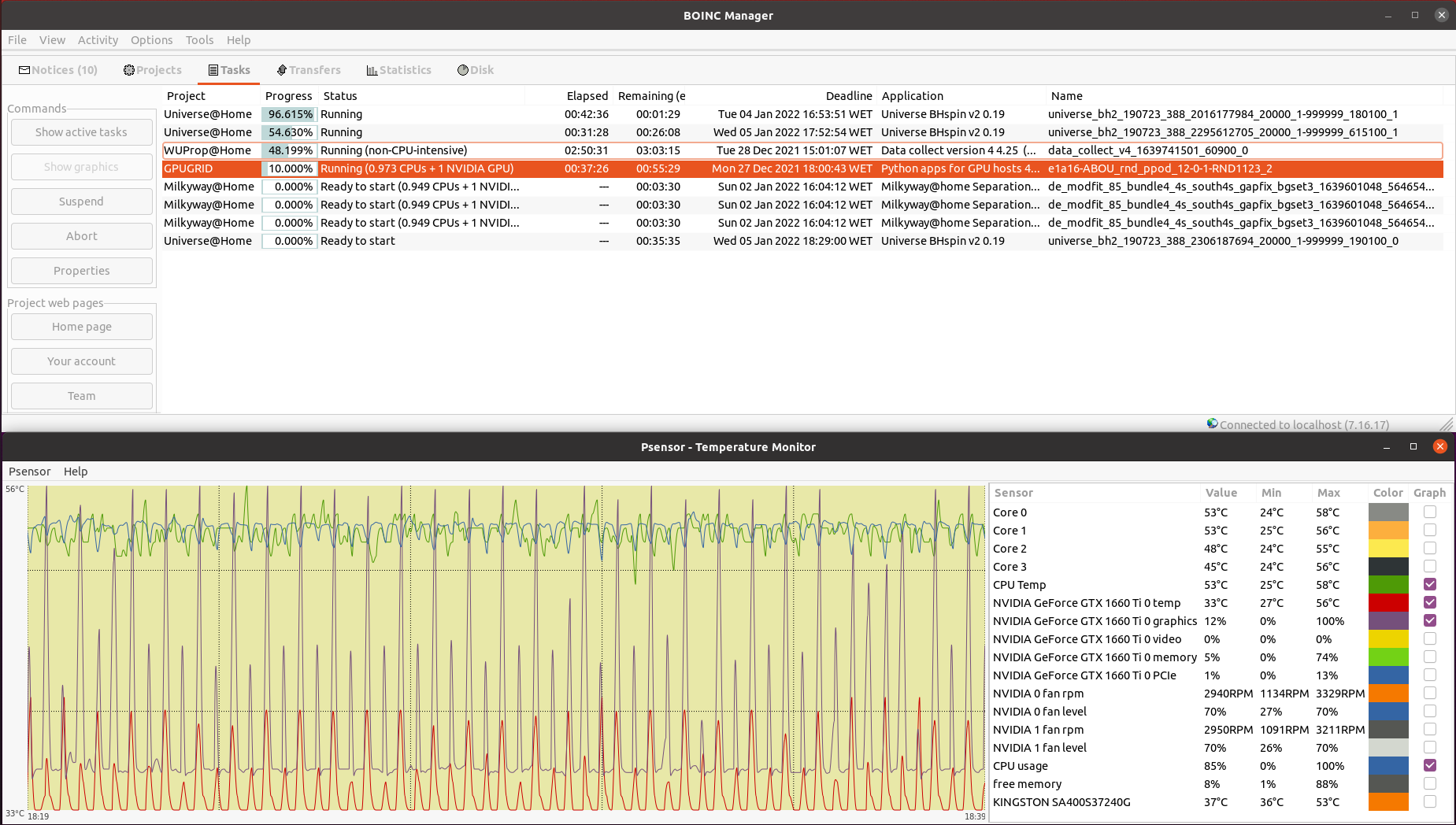
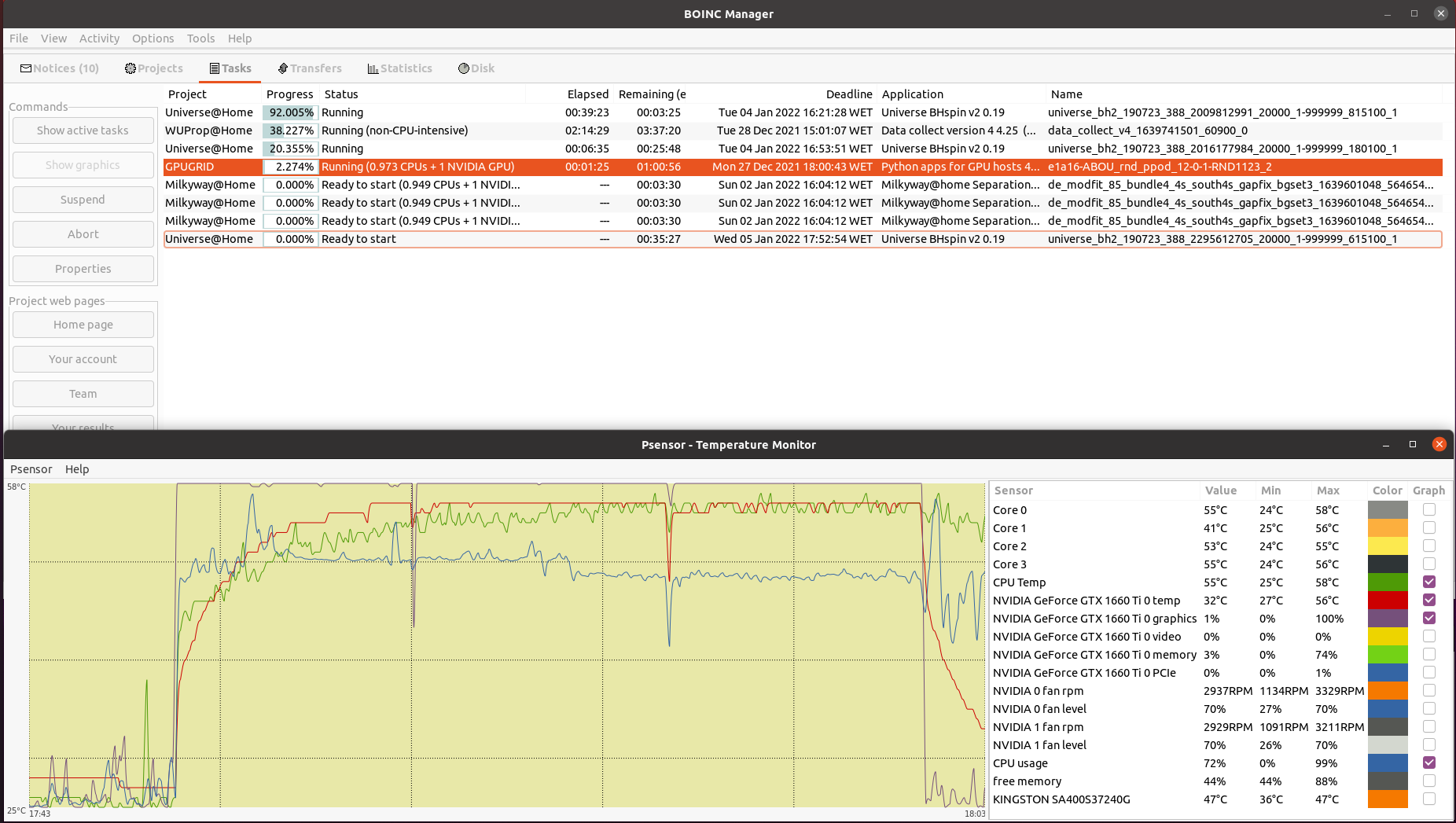
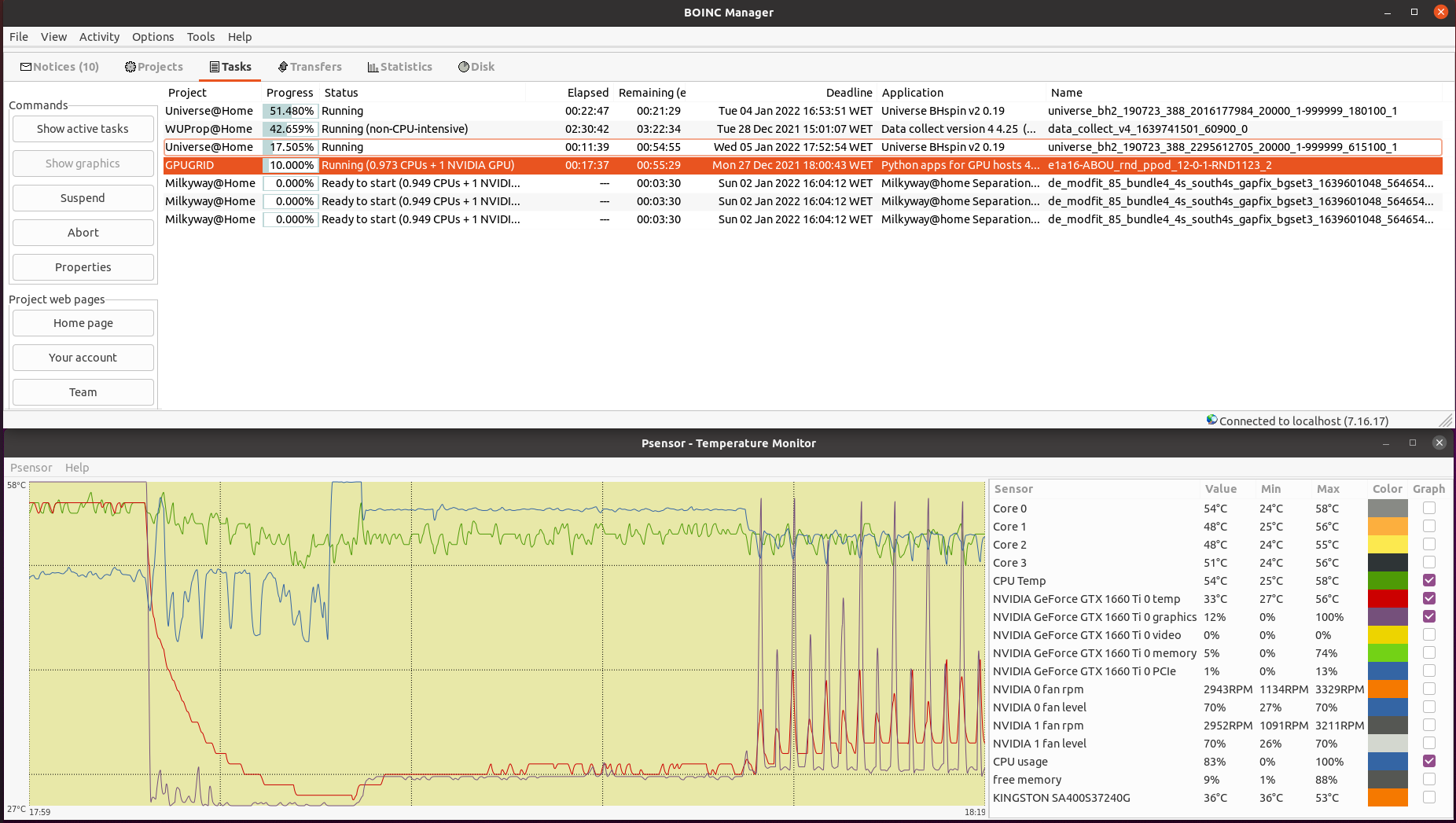
With the arrival of the last phase of Python GPU beta tasks for Linux systems, every of my hosts started to fail them. During the task, the agent first interacts with the environments for a while, then uses the GPU to process the collected data and learn from it, then interacts again with the environments, and so on. GPU keeps cycling between brief peaks of high activity (95% here) followed by valleys of low activity (11% here). CPU, on the other hand, presents peaks of lower activity in an anti cyclic pattern: When GPU activity increases, CPU activity decreases, and vice versa. Period for this cycling was about 21 seconds at this system. Result for this task: 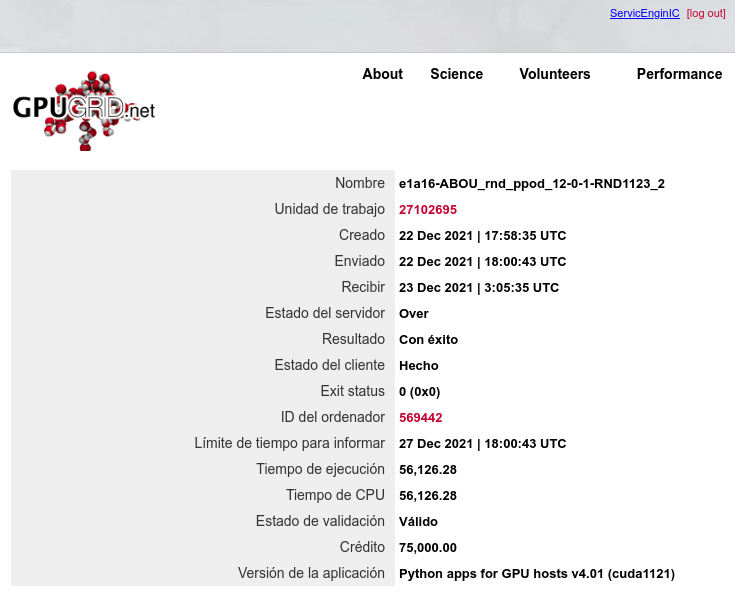 | |
| ID: 58199 | Rating: 0 | rate:
| |
|
ServicEnginIC Send message Joined: 24 Sep 10 Posts: 581 Credit: 9,994,706,652 RAC: 19,061,528 Level Scientific publications | |
|
Lately, In Canary Islands (Spain), electricity supply costs have been getting higher and higher, month after month. | |
| ID: 58366 | Rating: 0 | rate:
| |
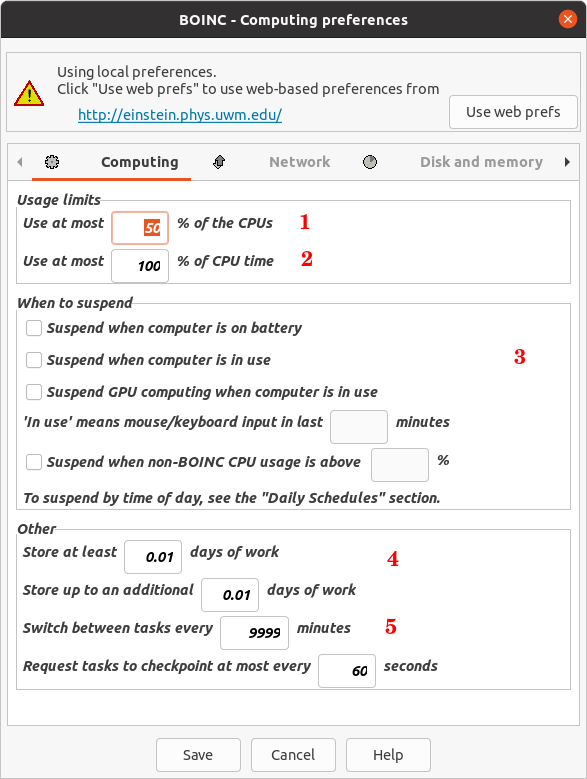
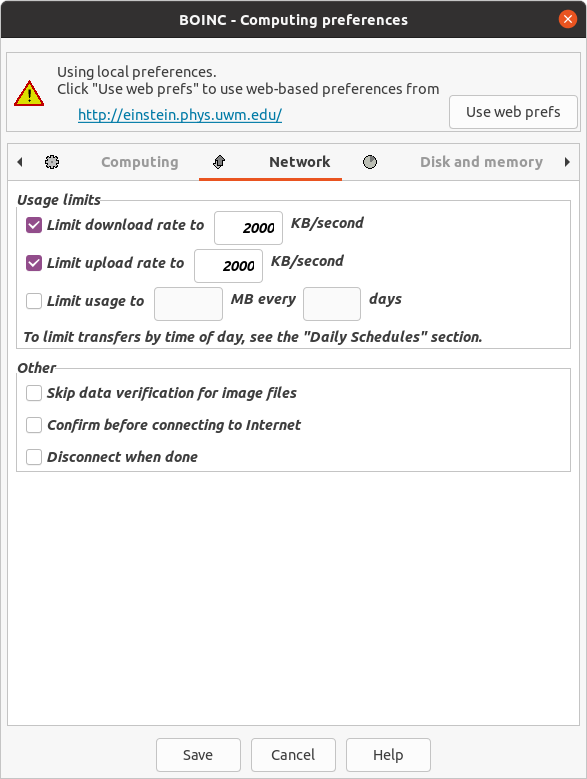
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Message boards : Number crunching : Managing non-high-end hosts