Message boards : Number crunching : Anaconda Python 3 Environment v4.01 failures
| Author | Message |
|---|---|
|
Richard Haselgrove Send message Joined: 11 Jul 09 Posts: 1620 Credit: 8,822,866,430 RAC: 19,442,844 Level Scientific publications | |
|
On Linux Mint hosts 537311 and 508381 | |
| ID: 55917 | Rating: 0 | rate:
| |
|
Sergey Kovalchuk Send message Joined: 18 Feb 16 Posts: 6 Credit: 1,121,331 RAC: 0 Level Scientific publications | |
|
wrapper uses absolute path (from root) wrapper: running ../../projects/boinc.project.org/apps (arg) | |
| ID: 55918 | Rating: 0 | rate:
| |
|
Ian&Steve C. Send message Joined: 21 Feb 20 Posts: 1069 Credit: 40,231,533,983 RAC: 527 Level Scientific publications | |
|
it's interesting that even though all the wingmen experience some error, they are not receiving the same error, and some are running for quite a while before erroring out. | |
| ID: 55919 | Rating: 0 | rate:
| |
|
Richard Haselgrove Send message Joined: 11 Jul 09 Posts: 1620 Credit: 8,822,866,430 RAC: 19,442,844 Level Scientific publications | |
|
My Linux machines run under the systemd daemon install. We found a problem recently where systemd was set up to have no access at all to the Linux tmp area - couldn't even read it. My machines are now able to read there, but may still be prevented from writing - wherever flock is trying to unpack python for installation. | |
| ID: 55922 | Rating: 0 | rate:
| |
|
Keith Myers  Send message Joined: 13 Dec 17 Posts: 1340 Credit: 7,653,123,724 RAC: 13,404,739 Level Scientific publications | |
|
Anybody successful yet in the new Python tasks? | |
| ID: 55924 | Rating: 0 | rate:
| |
|
Ian&Steve C. Send message Joined: 21 Feb 20 Posts: 1069 Credit: 40,231,533,983 RAC: 527 Level Scientific publications | |
|
Looks like Kevvy's system completed a bunch of them. | |
| ID: 55925 | Rating: 0 | rate:
| |
|
Keith Myers Send message Joined: 13 Dec 17 Posts: 1340 Credit: 7,653,123,724 RAC: 13,404,739 Level Scientific publications | |
|
Well, if mine really are going to run for 3 hours, then that is about 1.5X longer than ADRIA tasks on my hosts. | |
| ID: 55927 | Rating: 0 | rate:
| |
|
Ian&Steve C. Send message Joined: 21 Feb 20 Posts: 1069 Credit: 40,231,533,983 RAC: 527 Level Scientific publications | |
|
looks like I picked up a couple resends (i only just enabled Beta tasks). I'll see if they complete on my system. both picked up on my RTX 2070 system. | |
| ID: 55929 | Rating: 0 | rate:
| |
|
Keith Myers Send message Joined: 13 Dec 17 Posts: 1340 Credit: 7,653,123,724 RAC: 13,404,739 Level Scientific publications | |
|
Everyone has failed again on my two hosts. | |
| ID: 55930 | Rating: 0 | rate:
| |
|
Keith Myers Send message Joined: 13 Dec 17 Posts: 1340 Credit: 7,653,123,724 RAC: 13,404,739 Level Scientific publications | |
|
Finally had success on several new Python tasks. Wonder if the failures are logged to forward correct the task configuration so that future attempts are finished correctly. | |
| ID: 55934 | Rating: 0 | rate:
| |
|
Richard Haselgrove Send message Joined: 11 Jul 09 Posts: 1620 Credit: 8,822,866,430 RAC: 19,442,844 Level Scientific publications | |
|
I thought I'd turned off Python tasks after the failures, but I forgot to turn off test tasks as well, so I've been sent another one. | |
| ID: 55937 | Rating: 0 | rate:
| |
|
rod4x4 Send message Joined: 4 Aug 14 Posts: 266 Credit: 2,219,935,054 RAC: 0 Level Scientific publications | |
|
The latest round of tasks look fairly good. | |
| ID: 55938 | Rating: 0 | rate:
| |
|
Richard Haselgrove Send message Joined: 11 Jul 09 Posts: 1620 Credit: 8,822,866,430 RAC: 19,442,844 Level Scientific publications | |
|
Well, it failed again, with the program 'flock' failing to create a temporary directory. That's the very first task in the job spec, and it seems to be trying to install miniconda. | |
| ID: 55939 | Rating: 0 | rate:
| |
|
rod4x4 Send message Joined: 4 Aug 14 Posts: 266 Credit: 2,219,935,054 RAC: 0 Level Scientific publications | |
Well, it failed again, with the program 'flock' failing to create a temporary directory. That's the very first task in the job spec, and it seems to be trying to install miniconda. Apologies, should have read original post. Just to compare your failed tasks with successful tasks...https://gpugrid.net/result.php?resultid=31667292 It appears the tmp folder is a sub folder of the gpugrid.net project folder - miniconda and in the slot N folder gpugridpy. I currently have a task running now, both populated with the app compile environment. Is the user listed in /lib/systemd/system/boinc-client.service also in the /etc/group - boinc group? Does this user have correct permissions on /var/lib/boinc-client folder, sub folders? | |
| ID: 55940 | Rating: 0 | rate:
| |
|
Ian&Steve C. Send message Joined: 21 Feb 20 Posts: 1069 Credit: 40,231,533,983 RAC: 527 Level Scientific publications | |
|
Looks like I have 11 successful tasks, and 2 failures. | |
| ID: 55944 | Rating: 0 | rate:
| |
|
gemini8 Send message Joined: 3 Jul 16 Posts: 31 Credit: 2,212,787,676 RAC: 4,959,470 Level Scientific publications | |
|
Several failures for me as well. | |
| ID: 55950 | Rating: 0 | rate:
| |
|
Ian&Steve C. Send message Joined: 21 Feb 20 Posts: 1069 Credit: 40,231,533,983 RAC: 527 Level Scientific publications | |
|
Just spitballing, but it seems the people failing all their tasks are using a repository/service install of BOINC. | |
| ID: 55952 | Rating: 0 | rate:
| |
|
Keith Myers Send message Joined: 13 Dec 17 Posts: 1340 Credit: 7,653,123,724 RAC: 13,404,739 Level Scientific publications | |
|
First thing I would ask of the BOINC service install users, is their user added to the boinc group. | |
| ID: 55960 | Rating: 0 | rate:
| |
|
Richard Haselgrove Send message Joined: 11 Jul 09 Posts: 1620 Credit: 8,822,866,430 RAC: 19,442,844 Level Scientific publications | |
It appears the tmp folder is a sub folder of the gpugrid.net project folder - miniconda and in the slot N folder gpugridpy. I'm not entirely convinced by that. It's certainly the final destination for the installation, but is it the temp directory as well? Call me naive, but wouldn't a generic temp folder be created in /tmp/, unless directed otherwise? The last change to the BOINC service installation came as a result of https://github.com/BOINC/boinc/issues/3715#issuecomment-727609578. Previously, there was no access at all to /tmp/, which blocked idle detection. I'm running the fixed version, so I have access - but maybe it's only read access? That may explain why I was able to install conda on 11 November - with no access to /tmp/, it would have been forced to try another location. But access with no write permission??? Consistent with the error message. Anyway, I've made it private again. All we need now is a test task... | |
| ID: 55967 | Rating: 0 | rate:
| |
|
Richard Haselgrove Send message Joined: 11 Jul 09 Posts: 1620 Credit: 8,822,866,430 RAC: 19,442,844 Level Scientific publications | |
|
YAY! I got one, and it's running. Installed conda, got through all the setup stages, and is now running ACEMD, and reporting proper progress. | |
| ID: 55968 | Rating: 0 | rate:
| |
|
Ian&Steve C. Send message Joined: 21 Feb 20 Posts: 1069 Credit: 40,231,533,983 RAC: 527 Level Scientific publications | |
YAY! I got one, and it's running. Installed conda, got through all the setup stages, and is now running ACEMD, and reporting proper progress. hoping for a successful run. but it'll probably take 5-6hrs on a 1660ti. did you make any changes to your system between the last failed task and this one? ____________  | |
| ID: 55971 | Rating: 0 | rate:
| |
|
Richard Haselgrove Send message Joined: 11 Jul 09 Posts: 1620 Credit: 8,822,866,430 RAC: 19,442,844 Level Scientific publications | |
|
I applied the (very few) system updates that were waiting. I don't think anything would have been relevant to running tasks. [I remember a new version of curl, and of SSL, which might have affected external comms, but nothing caught my eye apart from those] | |
| ID: 55972 | Rating: 0 | rate:
| |
|
Ian&Steve C. Send message Joined: 21 Feb 20 Posts: 1069 Credit: 40,231,533,983 RAC: 527 Level Scientific publications | |
|
you probably didn't need to change the bounds to avoid a timeout. my early tasks all estimated sub 1min run times, but all ran to completion anyway, even my 1660Super which took 5+hrs to run. | |
| ID: 55973 | Rating: 0 | rate:
| |
|
Richard Haselgrove Send message Joined: 11 Jul 09 Posts: 1620 Credit: 8,822,866,430 RAC: 19,442,844 Level Scientific publications | |
|
Somebody mentioned a time out, so I thought it was better to be safe than sorry. After all the troubles, it would have been sad to lose a successful test to that (besides being a waste of time. At least the temp directory errors only wasted a couple of seconds!). | |
| ID: 55974 | Rating: 0 | rate:
| |
|
rod4x4 Send message Joined: 4 Aug 14 Posts: 266 Credit: 2,219,935,054 RAC: 0 Level Scientific publications | |
The last change to the BOINC service installation came as a result of https://github.com/BOINC/boinc/issues/3715#issuecomment-727609578. Previously, there was no access at all to /tmp/, which blocked idle detection. Did you find adding PrivateTmp=false to the boinc-client.service file changed the TMP access error in the original post? It is weird, as PrivateTmp defaults to false. I could set this to true on one of my working hosts to see what happens. YAY! I got one, and it's running. Installed conda, got through all the setup stages, and is now running ACEMD, and reporting proper progress. Progress! EDIT: I'm not entirely convinced by that. It's certainly the final destination for the installation, but is it the temp directory as well? Debian based distros seem to use /proc/locks directory for lock file location. If you use lslocks command, you will see the current locks, including any boinc/Gpugrid locks. (cat /proc/locks will also work, but you will need to know the PID of the processes listed to interpret the output) I cant think of anything that would prevent access to this directory structure, as it is critical in OS operations. I am leaning towards a bug in the Experimental Tasks scripts that causes this issue (and has since been cleaned up). | |
| ID: 55977 | Rating: 0 | rate:
| |
|
rod4x4 Send message Joined: 4 Aug 14 Posts: 266 Credit: 2,219,935,054 RAC: 0 Level Scientific publications | |
|
Ian&Steve C. wrote: Looks like I have 11 successful tasks, and 2 failures. gemini8 wrote: Several failures for me as well. I have seen the same errors on my hosts. It is a bug in those particular work units as they fail on all hosts. Some hosts report the Disk Limit Exceeded error, some hosts report an AssertionError - assert os.path.exists('output.coor') (AssertionError is from an assert statement inserted into the code by the programmer to trap and report errors) A host belonging to gemini8 experienced a flock timeout on Work Unit 26277866. All other hosts processing this task reported this error: os.remove('restart.chk') FileNotFoundError: [Errno 2] No such file or directory: 'restart.chk' gemini8 3 of your hosts with older CUDA driver report this: ACEMD failed: Error loading CUDA module: CUDA_ERROR_INVALID_PTX (218). Perhaps time for a driver update. It wont fix the errors being reported (reported errors are task bugs), but may prevent other issues developing in the future. | |
| ID: 55980 | Rating: 0 | rate:
| |
|
Richard Haselgrove Send message Joined: 11 Jul 09 Posts: 1620 Credit: 8,822,866,430 RAC: 19,442,844 Level Scientific publications | |
EDIT: Remember that I had a very specific reason for reverting a single recent change. The BOINC systemd file had PrivateTmp=true until very recently, and I had evidence that at least one Anaconda had successfully passed the installation phase in the past. The systemd file as distributed now has PrivateTmp=false, and my machine had that setting when the error messages appeared. I changed it back, so I now have PrivateTmp=true again. And with that one change (plus an increased time limit for safety), the task has completed successfully. I have a second machine, where I haven't yet made that change. Compare tasks 31712246 (WU created 10 Dec 2020 | 20:54:14 UTC, PrivateTmp=true) and 31712588 (WU created 10 Dec 2020 | 21:05:06 UTC, PrivateTmp=false). The first succeeded, the second failed with 'cannot create temporary directory'. I don't think it was a design change by the project. I now have a DCF of 87, and I need to go and talk to the Debian/BOINC maintenance team again... | |
| ID: 55981 | Rating: 0 | rate:
| |
|
gemini8 Send message Joined: 3 Jul 16 Posts: 31 Credit: 2,212,787,676 RAC: 4,959,470 Level Scientific publications | |
|
rod4x4 wrote: gemini8 Thanks for your concern! The systems run with the 'standard' proprietary Nvidia Debian driver. Wasn't able to get a later one working, so I keep them this way. Could switch the systems to Ubuntu which features later drivers, but I like Debian better and thus don't plan to do so. ____________ - - - - - - - - - - Greetings, Jens | |
| ID: 55982 | Rating: 0 | rate:
| |
|
kksplace Send message Joined: 4 Mar 18 Posts: 53 Credit: 2,591,271,749 RAC: 6,720,230 Level Scientific publications | |
|
Not a technical guru like you all here, but if it helps, my system has had one Anaconda failure back on 4 Dec, and now completed 4 in the last several days with one more in progress. Let me know if I can provide any information that helps. | |
| ID: 55983 | Rating: 0 | rate:
| |
 ServicEnginIC ServicEnginICSend message Joined: 24 Sep 10 Posts: 581 Credit: 9,768,112,024 RAC: 21,327,418 Level Scientific publications | |
|
Richard Haselgrove: INTERNAL ERROR: cannot create temporary directory! I executed the stated command: sudo systemctl edit boinc-client.service And I added to the file the suggested lines: [Service] After saving changes and rebooting, the mentioned error vanished. Task 2p95010002r00-RAIMIS_NNPMM-0-1-RND3897_0 has succeeded on my Host #482132. This host had previously failed 28 Anaconda Python tasks one after another... I've applied the same remedy to several other hosts, and three more tasks seem to be progressing normally. You have hit the mark | |
| ID: 55986 | Rating: 0 | rate:
| |
|
rod4x4 Send message Joined: 4 Aug 14 Posts: 266 Credit: 2,219,935,054 RAC: 0 Level Scientific publications | |
The systemd file as distributed now has PrivateTmp=false, and my machine had that setting when the error messages appeared. I changed it back, so I now have PrivateTmp=true again. And with that one change (plus an increased time limit for safety), the task has completed successfully. On my hosts that are not reporting this issue, PrivateTmp is not set (so defaults to false) https://gpugrid.net/show_host_detail.php?hostid=483378 https://gpugrid.net/show_host_detail.php?hostid=544286 https://gpugrid.net/show_host_detail.php?hostid=483296 I do have ProtectHome=true set on all hosts. One thing I did note on 31712588 is that the tmp directory creation error is reported on a different PID to the wrapper. All transactions should be on the same PID. 21:48:18 (21729): wrapper: running /usr/bin/flock (/var/lib/boinc-client/projects/www.gpugrid.net/miniconda.lock -c "/bin/bash ./miniconda-installer.sh -b -u -p /var/lib/boinc-client/projects/www.gpugrid.net/miniconda && My concern is different outcomes are being seen with similar setting of PrivateTmp=false Would be interested in Debian/BOINC maintenance team feedback. | |
| ID: 55987 | Rating: 0 | rate:
| |
|
rod4x4 Send message Joined: 4 Aug 14 Posts: 266 Credit: 2,219,935,054 RAC: 0 Level Scientific publications | |
Richard Haselgrove: Good feedback! So Richard Haselgrove, does ProtectHome=true imply PrivateTmp=true (or vice versa)? | |
| ID: 55988 | Rating: 0 | rate:
| |
|
Keith Myers Send message Joined: 13 Dec 17 Posts: 1340 Credit: 7,653,123,724 RAC: 13,404,739 Level Scientific publications | |
|
Yes, I too would like to hear the feedback from the developers, in my case what can be done with the project DCF of 93 on all my hosts. | |
| ID: 55989 | Rating: 0 | rate:
| |
|
ServicEnginIC Send message Joined: 24 Sep 10 Posts: 581 Credit: 9,768,112,024 RAC: 21,327,418 Level Scientific publications | |
On my hosts that are not reporting this issue, PrivateTmp is not set (so defaults to false) All your three successful hosts have 7.9.3 BOINC version in use. That version was default to PrivateTmp=true Newer versions 7.16.xx changed this criterium to PrivateTmp=false by default. | |
| ID: 55990 | Rating: 0 | rate:
| |
|
rod4x4 Send message Joined: 4 Aug 14 Posts: 266 Credit: 2,219,935,054 RAC: 0 Level Scientific publications | |
On my hosts that are not reporting this issue, PrivateTmp is not set (so defaults to false) Good pickup. Thanks for the clarification. I missed that! Answers all my concerns. I noted that the security directories created by PrivateTmp existed on my system, but could not work out why they existed. | |
| ID: 55991 | Rating: 0 | rate:
| |
|
Richard Haselgrove Send message Joined: 11 Jul 09 Posts: 1620 Credit: 8,822,866,430 RAC: 19,442,844 Level Scientific publications | |
|
Thanks guys. I've written up the problem for upstream at https://github.com/BOINC/boinc/issues/4125, and I'm hoping to get further ideas from there. At the moment, the situation seems to be that you can either use idle detection to keep BOINC out of the way when working, or run Python tasks, but not both together. That seems unsatisfactory. either adding /var/tmp and /tmp to ReadWritePaths= Both sound insecure and not recommended for general use, but try them at your own risk. I'll be doing that. Responding to other comments: rod4x4 wrote: the tmp directory creation error is reported on a different PID to the wrapper. That's the nature of the wrapper. Its job is to spawn child processes. It will be the child processes which will be trying to create temporary folders, and their PIDs will be different from the parent's. rod4x4 wrote: does ProtectHome=true imply PrivateTmp=true (or vice versa)? I don't know. I've got a lot of experience with BOINC, but I'm a complete n00b with Linux - learning on the job, by using analogies from other areas of computing. We'll find out as we go along. Keith Myers wrote: what can be done with the project DCF of 93 on all my hosts. That's an easy problem, totally within the scope of the project admins here. We just have to ask TONI to have a word with RAIMIS, and ask him/her to increase the template <rsc_fpops_est> to a more realistic value. Then, the single DCF value controlling all runtime estimates throughout this project can settle back on a value close to 1. ServicEnginIC wrote: Newer versions 7.16.xx changed this criterium to PrivateTmp=false by default. The suggestion for making this change was first made on 15 November 2020. Only people who use a quickly updating Linux repo - like Gianfranco Costamagna's PPA - will have encountered it so far. But the mainstream stable repos will get to it eventually | |
| ID: 55993 | Rating: 0 | rate:
| |
|
rod4x4 Send message Joined: 4 Aug 14 Posts: 266 Credit: 2,219,935,054 RAC: 0 Level Scientific publications | |
Thanks guys. I've written up the problem for upstream at https://github.com/BOINC/boinc/issues/4125, and I'm hoping to get further ideas from there. At the moment, the situation seems to be that you can either use idle detection to keep BOINC out of the way when working, or run Python tasks, but not both together. That seems unsatisfactory. Thanks Richard Haselgrove. Will follow that issue request with interest. The last suggestion by BryanQuigley has merit. Either way, the project has the BOINC writable directory - why not use that? You can make your own tmp directory there if I'm not mistaken (haven't tried it) His suggestion will mean any temp files will be protected by the Boinc security system already in place, bypasses the need for PrivateTmp=true and be accessible for Boinc process calls. One issue would be a a clean up process for the temp folder will need to be controlled by BOINC to prevent run away file storage. | |
| ID: 55998 | Rating: 0 | rate:
| |
|
rod4x4 Send message Joined: 4 Aug 14 Posts: 266 Credit: 2,219,935,054 RAC: 0 Level Scientific publications | |
His suggestion will mean any temp files will be protected by the Boinc security system already in place, bypasses the need for PrivateTmp=true and be accessible for Boinc process calls. Which circles back to how flock uses /tmp directory. Perhaps BryanQuigley can clear that point up. | |
| ID: 55999 | Rating: 0 | rate:
| |
|
rod4x4 Send message Joined: 4 Aug 14 Posts: 266 Credit: 2,219,935,054 RAC: 0 Level Scientific publications | |
His suggestion will mean any temp files will be protected by the Boinc security system already in place, bypasses the need for PrivateTmp=true and be accessible for Boinc process calls. I am starting to think the error is not related to flock temp folder handling nor is PrivateTmp the cause, rather they highlight an error in the Gpugrid work unit script. I have noticed that 9 files are written to /tmp folder for each experimental task. These files are readable and contain nvidia compiler data. The work unit script should be placing these files in the boinc folder structure. It is these file writes that are causing the error. 21:48:18 (21729): wrapper: running /usr/bin/flock (/var/lib/boinc-client/projects/www.gpugrid.net/miniconda.lock -c "/bin/bash ./miniconda-installer.sh -b -u -p /var/lib/boinc-client/projects/www.gpugrid.net/miniconda && Once this script error is corrected, PrivateTmp can be reverted to the preferred setting. It should also be noted that the task is not cleaning up these files on completion. This will lead to disk space exhaustion if not controlled. | |
| ID: 56000 | Rating: 0 | rate:
| |
|
Richard Haselgrove Send message Joined: 11 Jul 09 Posts: 1620 Credit: 8,822,866,430 RAC: 19,442,844 Level Scientific publications | |
|
I think it's more likely to be the /bin/bash which actually needs to write temporary files. I've now managed (with some difficulty) to separate the 569 lines of actual script from the 90 MB of payload. There's export TMP_BACKUP="$TMP" export TMP=$PREFIX/install_tmp but no sign of the TMPDIR mentioned in https://linux.die.net/man/1/bash. More than that is above my pay-grade, I'm afraid. You can run the script in your home directory if you want to know more about it. (Like the End User License Agreement, the Notice of Third Party Software Licenses, and the Export; Cryptography Notice!) | |
| ID: 56001 | Rating: 0 | rate:
| |
|
ServicEnginIC Send message Joined: 24 Sep 10 Posts: 581 Credit: 9,768,112,024 RAC: 21,327,418 Level Scientific publications | |
|
For those users waiting to receive these new Anaconda Python tasks: | |
| ID: 56002 | Rating: 0 | rate:
| |
|
ServicEnginIC Send message Joined: 24 Sep 10 Posts: 581 Credit: 9,768,112,024 RAC: 21,327,418 Level Scientific publications | |
I suspect that graphics card with more than 2 GB internal RAM is a requirement (?) This theory has been empirically rebated: My Host #557889 has received today its first Python task: 3pwd006012-RAIMIS_NNPMM-0-1-RND4045_1, WU #26416972. This system is based on a GTX 750 Ti graphics card with 2GB internal RAM. Pitifully, the mentioned task failed after its first computing stage. On the other hand, my Host #480458, having previously failed 39 Python tasks after few seconds past, is progressing apparently normal a new one after resetting GPUGrid project on this computer. | |
| ID: 56003 | Rating: 0 | rate:
| |
|
rod4x4 Send message Joined: 4 Aug 14 Posts: 266 Credit: 2,219,935,054 RAC: 0 Level Scientific publications | |
I think it's more likely to be the /bin/bash which actually needs to write temporary files. I've now managed (with some difficulty) to separate the 569 lines of actual script from the 90 MB of payload. There's When using /bin/bash with -c, temporary files are not needed by bash. Within a script, there can be cases when temporary storage is required by /bin/bash. This is dependent on how the script is written. TMPDIR referenced in the link, refers to the option of using and specifying a temporary directory if desired. This practice is avoided where possible, mktemp is the safest method (but not used here). From what I can gather, wrapper starts the script successfully, miniconda folder is installed silently in /www.gpugrid.net/ directory, conda install starts the setup of the environment, unpacks files then initiates processes to compile the task.
/miniconda/etc/profile.d/ directory, /miniconda/lib/python3.7/<_sysconfigdata_> files
| |
| ID: 56004 | Rating: 0 | rate:
| |
|
Richard Haselgrove Send message Joined: 11 Jul 09 Posts: 1620 Credit: 8,822,866,430 RAC: 19,442,844 Level Scientific publications | |
|
Curious observation. I've got a Python task running, with all the usual values - 3,000 GFLOPS size, progress rate 14.760% per hour - but BOINC is estimating over 13 days until completion. Normally it's the TONI tasks which are messed up by DCF = 87.8106. (Python) estimated total NVIDIA GPU task duration: 1631149 seconds (TONI) estimated total NVIDIA GPU task duration: 731036 seconds Ah - the speed has dropped right down - <flops> 164,825,886 in <app_version>. Observing and investigating. (it was the other one they needed to change - <rsc_fpops_est> in <workunit>) Edit - my other machine still has <flops> 61,081,927,479, but it hasn't picked up any Python work since 22:00 last night. | |
| ID: 56005 | Rating: 0 | rate:
| |
|
ServicEnginIC Send message Joined: 24 Sep 10 Posts: 581 Credit: 9,768,112,024 RAC: 21,327,418 Level Scientific publications | |
|
Returning to graphics card RAM size and Python tasks: | |
| ID: 56022 | Rating: 0 | rate:
| |
Returning to graphics card RAM size and Python tasks: Yeah, my GTX 1650 is running one of the Python tasks at the moment and it's using 2.6 GB | |
| ID: 56024 | Rating: 0 | rate:
| |
|
bozz4science Send message Joined: 22 May 20 Posts: 109 Credit: 102,786,176 RAC: 103,187 Level Scientific publications | |
|
I happened to receive my first beta task today on a 750Ti (2GB VRAM). It started okay and the task progress bar advanced normally just to fail after ~800 sec. What I have seen so far on other hosts was that either the task seemed to fail immediately within seconds or it finished successfully, so it's strange that it did compute for quite some time. Saw that some of you reported >2GB VRAM used for the task so that could be an issue here as well, but I can't find in the stderr file what might have caused this error. Task 26520658 | |
| ID: 56025 | Rating: 0 | rate:
| |
|
Ian&Steve C. Send message Joined: 21 Feb 20 Posts: 1069 Credit: 40,231,533,983 RAC: 527 Level Scientific publications | |
I happened to receive my first beta task today on a 750Ti (2GB VRAM). It started okay and the task progress bar advanced normally just to fail after ~800 sec. What I have seen so far on other hosts was that either the task seemed to fail immediately within seconds or it finished successfully, so it's strange that it did compute for quite some time. Saw that some of you reported >2GB VRAM used for the task so that could be an issue here as well, but I can't find in the stderr file what might have caused this error. Task 26520658 this is the specific reason: Traceback (most recent call last): could be a bug in the task, or a consequence of not having enough memory. ____________ | |
| ID: 56026 | Rating: 0 | rate:
| |
|
bozz4science Send message Joined: 22 May 20 Posts: 109 Credit: 102,786,176 RAC: 103,187 Level Scientific publications | |
|
Thanks for the pointer Ian&Steve. Seems like this issue prevails. Just got another beta task that failed and gave me the same error message. | |
| ID: 56029 | Rating: 0 | rate:
| |
|
zombie67 [MM]  Send message Joined: 16 Jul 07 Posts: 209 Credit: 4,095,161,456 RAC: 22,338,324 Level Scientific publications | |
|
I just read through this whole thread, and I am still not clear what changes I need to make to fix the permissions error. FWIW, I have the regular BOINC installation, not a service installation. | |
| ID: 56032 | Rating: 0 | rate:
| |
|
rod4x4 Send message Joined: 4 Aug 14 Posts: 266 Credit: 2,219,935,054 RAC: 0 Level Scientific publications | |
I just read through this whole thread, and I am still not clear what changes I need to make to fix the permissions error. FWIW, I have the regular BOINC installation, not a service installation. Apply this modification: Extracted from post by ServicEnginIC (https://www.gpugrid.net/forum_thread.php?id=5204&nowrap=true#55988
I executed the stated command:
sudo systemctl edit boinc-client.service
And I added to the file the suggested lines:
[Service]
PrivateTmp=true
A reboot is recommended after applying this change. (Or at the least, restart the boinc-client service) | |
| ID: 56034 | Rating: 0 | rate:
| |
|
zombie67 [MM] Send message Joined: 16 Jul 07 Posts: 209 Credit: 4,095,161,456 RAC: 22,338,324 Level Scientific publications | |
I just read through this whole thread, and I am still not clear what changes I need to make to fix the permissions error. FWIW, I have the regular BOINC installation, not a service installation. Thanks. I wan't sure that applied to my situation, since my installation is not a service installation. And those instructions included "service". I added the lines, assuming I figured out the editor correctly. I know only vi. Anyway, just waiting for new tasks to try out now. ____________ Reno, NV Team: SETI.USA | |
| ID: 56035 | Rating: 0 | rate:
| |
|
Richard Haselgrove Send message Joined: 11 Jul 09 Posts: 1620 Credit: 8,822,866,430 RAC: 19,442,844 Level Scientific publications | |
|
It would help if you identified exactly which version you have now installed (by version number, not some relative generality like "the latest"), and who released it. Berkeley has not released a new version for Linux, and so far as I know every Linux distribution or repository version available is designed to install as a service. I find the newest versions publicly available are in Gianfranco Costamagna's (LocutusOfBorg) PPA. That's where my problem originated. | |
| ID: 56038 | Rating: 0 | rate:
| |
|
zombie67 [MM] Send message Joined: 16 Jul 07 Posts: 209 Credit: 4,095,161,456 RAC: 22,338,324 Level Scientific publications | |
|
I was running 7.9.3, which is what was in the default repository for mint. It had the other problem, with only 20 credits per task. | |
| ID: 56039 | Rating: 0 | rate:
| |
|
Ian&Steve C. Send message Joined: 21 Feb 20 Posts: 1069 Credit: 40,231,533,983 RAC: 527 Level Scientific publications | |
|
I've never seen a Windows installation that WASN'T a service install. | |
| ID: 56040 | Rating: 0 | rate:
| |
|
Richard Haselgrove Send message Joined: 11 Jul 09 Posts: 1620 Credit: 8,822,866,430 RAC: 19,442,844 Level Scientific publications | |
Interesting to learn that all linux installations do it as a service install. I thought that caused a problem with GPU crunching? Yes, your statement is right. The "GPUs are not available to services" is a specific, Windows only, driver security matter. Mac and Linux have different ways of handling it. | |
| ID: 56041 | Rating: 0 | rate:
| |
|
Ian&Steve C. Send message Joined: 21 Feb 20 Posts: 1069 Credit: 40,231,533,983 RAC: 527 Level Scientific publications | |
Interesting to learn that all linux installations do it as a service install. I thought that caused a problem with GPU crunching? maybe we mean different things? When I've installed boinc on Windows in the past, it hooked into the OS the same way many installed Windows applications do, and ran at startup without user intervention. It did so also with GPU crunching and I never saw an issue with GPU crunching in this configuration. is that not a service install? ____________ | |
| ID: 56042 | Rating: 0 | rate:
| |
|
Richard Haselgrove Send message Joined: 11 Jul 09 Posts: 1620 Credit: 8,822,866,430 RAC: 19,442,844 Level Scientific publications | |
|
Under Windows, the installer gives you the choice of how and where to install BOINC. There are defaults, which are designed to 'just work', or you can enter the 'advanced' page and choose your own. Any personal choice will be remembered and offered as the default the next time round. | |
| ID: 56043 | Rating: 0 | rate:
| |
|
Ian&Steve C. Send message Joined: 21 Feb 20 Posts: 1069 Credit: 40,231,533,983 RAC: 527 Level Scientific publications | |
|
ah, that might be the difference then. the past installs were all on windows 7 and I never did anything special or advanced for the install of BOINC. But since they were just crunchers I never bothered having a login prompt, and just let them login automatically at startup. guess that's why I never noticed any issues with GPU crunching this way. To me, if it's running automatically in any way without me actually manually executing the file, it's being run as some sort of service. | |
| ID: 56044 | Rating: 0 | rate:
| |
|
Richard Haselgrove Send message Joined: 11 Jul 09 Posts: 1620 Credit: 8,822,866,430 RAC: 19,442,844 Level Scientific publications | |
|
When a user logs on, Windows Registry Editor Version 5.00 [HKEY_CURRENT_USER\Software\Microsoft\Windows\CurrentVersion\Run] "boincmgr"="\"D:\\BOINC\\boincmgr.exe\" /a /s" [HKEY_CURRENT_USER\Software\Space Sciences Laboratory, U.C. Berkeley\BOINC Manager] "DisableAutoStart"=dword:00000000 1) Open the BOINC Manager - automatically, silently [implies unconditionally, minimised] 2) If the user has not disabled startup, the Manager will start the client. If they have disabled startup, backout before anyone notices. All in user space - no service. | |
| ID: 56045 | Rating: 0 | rate:
| |
|
Toni Volunteer moderator Project administrator Project developer Project tester Project scientist Send message Joined: 9 Dec 08 Posts: 1006 Credit: 5,068,599 RAC: 0 Level Scientific publications | |
|
I increased the FLOPS estimate to 5e15 (was 3e12) and disk usage limit to 10 GB. | |
| ID: 56121 | Rating: 0 | rate:
| |
|
Toni Volunteer moderator Project administrator Project developer Project tester Project scientist Send message Joined: 9 Dec 08 Posts: 1006 Credit: 5,068,599 RAC: 0 Level Scientific publications | |
|
Also: there shouldn't be Windows Python tasks right now. | |
| ID: 56122 | Rating: 0 | rate:
| |
|
Richard Haselgrove Send message Joined: 11 Jul 09 Posts: 1620 Credit: 8,822,866,430 RAC: 19,442,844 Level Scientific publications | |
I increased the FLOPS estimate to 5e15 (was 3e12) and disk usage limit to 10 GB. Thanks, that's a great help. But could you do something similar to the speed estimate, too, please? I'm working on a python task now. The machine also works on ACEMD Tasks, too, but the speeds are totally mis-aligned: <app_version> <app_name>acemd3</app_name> <version_num>211</version_num> <platform>x86_64-pc-linux-gnu</platform> <flops>610819274798.369263</flops> ... <app_version> <app_name>Python</app_name> <version_num>401</version_num> <platform>x86_64-pc-linux-gnu</platform> <flops>165617818.500620</flops> ... That's 610 GigaFlops when running ACEMD, and a measly 165 MegaFlops when running Python (on the same GTX 1660 SUPER). As a result, at 87% done, it's still estimating nearly 600 days to completion! Edit - those figures are what your server sends in response to the 'average processing rate' in https://www.gpugrid.net/host_app_versions.php?hostid=537311 | |
| ID: 56143 | Rating: 0 | rate:
| |
|
Richard Haselgrove Send message Joined: 11 Jul 09 Posts: 1620 Credit: 8,822,866,430 RAC: 19,442,844 Level Scientific publications | |
Also: spaces in directory names may well create problems. But why spaces? that's inviting problems. Sadly, you've missed that boat. Long file names and directory names, including spaces in either, have been de rigeur in Windows since 1995! The accepted solution is to enclose affected names "in quotation marks". | |
| ID: 56144 | Rating: 0 | rate:
| |
Also: spaces in directory names may well create problems. But why spaces? that's inviting problems. This is a thread for an app that runs on Linux. I think most of us prefer to use the "_" underscore. | |
| ID: 56150 | Rating: 0 | rate:
| |
|
Azmodes Send message Joined: 7 Jan 17 Posts: 34 Credit: 1,371,429,518 RAC: 0 Level Scientific publications | |
|
Been getting "1 (0x1) Unknown error number" after a couple of minutes on a few of my machines (one of which also had valid ones a few days ago). Is this something on my end? <core_client_version>7.16.6</core_client_version> <![CDATA[ <message> process exited with code 1 (0x1, -255)</message> <stderr_txt> 12:51:44 (69060): wrapper (7.7.26016): starting 12:51:44 (69060): wrapper (7.7.26016): starting 12:51:44 (69060): wrapper: running /usr/bin/flock (/var/lib/boinc-client/projects/www.gpugrid.net/miniconda.lock -c "/bin/bash ./miniconda-installer.sh -b -u -p /var/lib/boinc-client/projects/www.gpugrid.net/miniconda && /var/lib/boinc-client/projects/www.gpugrid.net/miniconda/bin/conda install -m -y -p gpugridpy --file requirements.txt ") 0%| | 0/96 [00:00<?, ?it/s] Extracting : libgcc-ng-9.1.0-hdf63c60_0.conda: 0%| | 0/96 [00:00<?, ?it/s] Extracting : libgcc-ng-9.1.0-hdf63c60_0.conda: 1%|1 | 1/96 [00:00<00:23, 4.13it/s] Extracting : tk-8.6.8-hbc83047_0.conda: 1%|1 | 1/96 [00:00<00:23, 4.13it/s] Extracting : setuptools-46.4.0-py37_0.conda: 2%|2 | 2/96 [00:00<00:22, 4.13it/s] Extracting : requests-2.23.0-py37_0.conda: 3%|3 | 3/96 [00:00<00:22, 4.13it/s] Extracting : cudnn-7.6.5-cuda10.2_0.conda: 4%|4 | 4/96 [03:04<00:22, 4.13it/s] Extracting : cudnn-7.6.5-cuda10.2_0.conda: 5%|5 | 5/96 [03:04<21:12, 13.99s/it] Extracting : numpy-1.19.2-py37h54aff64_0.conda: 5%|5 | 5/96 [03:04<21:12, 13.99s/it] Extracting : pysocks-1.7.1-py37_0.conda: 6%|6 | 6/96 [03:04<20:59, 13.99s/it] Extracting : cffi-1.14.0-py37he30daa8_1.conda: 7%|7 | 7/96 [03:04<20:45, 13.99s/it] Extracting : conda-package-handling-1.6.1-py37h7b6447c_0.conda: 8%|8 | 8/96 [03:04<20:31, 13.99s/it] Extracting : pycosat-0.6.3-py37h7b6447c_0.conda: 9%|9 | 9/96 [03:04<20:17, 13.99s/it] Extracting : wheel-0.34.2-py37_0.conda: 10%|# | 10/96 [03:04<20:03, 13.99s/it] Extracting : libedit-3.1.20181209-hc058e9b_0.conda: 11%|#1 | 11/96 [03:04<19:49, 13.99s/it] Extracting : sqlite-3.31.1-h62c20be_1.conda: 12%|#2 | 12/96 [03:04<19:35, 13.99s/it] Extracting : libstdcxx-ng-9.1.0-hdf63c60_0.conda: 14%|#3 | 13/96 [03:04<19:21, 13.99s/it] Extracting : chardet-3.0.4-py37_1003.conda: 15%|#4 | 14/96 [03:04<19:07, 13.99s/it] Extracting : readline-8.0-h7b6447c_0.conda: 16%|#5 | 15/96 [03:04<18:53, 13.99s/it] Extracting : python-3.7.7-hcff3b4d_5.conda: 17%|#6 | 16/96 [03:04<18:39, 13.99s/it] Extracting : libffi-3.3-he6710b0_1.conda: 18%|#7 | 17/96 [03:04<18:25, 13.99s/it] Extracting : pip-20.0.2-py37_3.conda: 19%|#8 | 18/96 [03:04<18:11, 13.99s/it] Extracting : pyopenssl-19.1.0-py37_0.conda: 20%|#9 | 19/96 [03:04<17:57, 13.99s/it] Extracting : _libgcc_mutex-0.1-main.conda: 21%|## | 20/96 [03:04<17:43, 13.99s/it] Extracting : urllib3-1.25.8-py37_0.conda: 22%|##1 | 21/96 [03:04<17:29, 13.99s/it] Extracting : blas-1.0-mkl.conda: 23%|##2 | 22/96 [03:04<17:15, 13.99s/it] Extracting : certifi-2020.4.5.1-py37_0.conda: 24%|##3 | 23/96 [03:04<17:01, 13.99s/it] Extracting : scipy-1.5.2-py37h0b6359f_0.conda: 25%|##5 | 24/96 [03:04<16:47, 13.99s/it] Extracting : six-1.14.0-py37_0.conda: 26%|##6 | 25/96 [03:04<16:33, 13.99s/it] Extracting : idna-2.9-py_1.conda: 27%|##7 | 26/96 [03:04<16:19, 13.99s/it] Extracting : ncurses-6.2-he6710b0_1.conda: 28%|##8 | 27/96 [03:04<16:05, 13.99s/it] Extracting : zlib-1.2.11-h7b6447c_3.conda: 29%|##9 | 28/96 [03:04<15:51, 13.99s/it] Extracting : ld_impl_linux-64-2.33.1-h53a641e_7.conda: 30%|### | 29/96 [03:04<15:37, 13.99s/it] Extracting : xz-5.2.5-h7b6447c_0.conda: 31%|###1 | 30/96 [03:04<15:23, 13.99s/it] Extracting : ca-certificates-2020.1.1-0.conda: 32%|###2 | 31/96 [03:04<15:09, 13.99s/it] Extracting : tqdm-4.46.0-py_0.conda: 33%|###3 | 32/96 [03:04<14:55, 13.99s/it] Extracting : pycparser-2.20-py_0.conda: 34%|###4 | 33/96 [03:04<14:41, 13.99s/it] Extracting : openssl-1.1.1g-h7b6447c_0.conda: 35%|###5 | 34/96 [03:04<14:27, 13.99s/it] Extracting : cudatoolkit-10.2.89-hfd86e86_1.conda: 36%|###6 | 35/96 [03:40<14:13, 13.99s/it] Extracting : cudatoolkit-10.2.89-hfd86e86_1.conda: 38%|###7 | 36/96 [03:40<10:08, 10.14s/it] Extracting : yaml-0.1.7-had09818_2.conda: 38%|###7 | 36/96 [03:40<10:08, 10.14s/it] Extracting : ruamel_yaml-0.15.87-py37h7b6447c_0.conda: 39%|###8 | 37/96 [03:40<09:58, 10.14s/it] Extracting : numpy-base-1.19.2-py37hfa32c7d_0.conda: 40%|###9 | 38/96 [03:40<09:47, 10.14s/it] Extracting : cryptography-2.9.2-py37h1ba5d50_0.conda: 41%|#### | 39/96 [03:40<09:37, 10.14s/it] Extracting : ncurses-6.2-h58526e2_3.tar.bz2: 42%|####1 | 40/96 [03:40<09:27, 10.14s/it] Extracting : libstdcxx-ng-9.3.0-h2ae2ef3_17.tar.bz2: 43%|####2 | 41/96 [03:40<09:17, 10.14s/it] Extracting : cffi-1.14.3-py37h00ebd2e_1.tar.bz2: 44%|####3 | 42/96 [03:40<09:07, 10.14s/it] Extracting : networkx-2.5-py_0.tar.bz2: 45%|####4 | 43/96 [03:40<08:57, 10.14s/it] Extracting : libffi-3.2.1-he1b5a44_1007.tar.bz2: 46%|####5 | 44/96 [03:40<08:47, 10.14s/it] Extracting : libllvm10-10.0.1-he513fc3_3.tar.bz2: 47%|####6 | 45/96 [03:40<08:36, 10.14s/it] Extracting : mkl-2020.4-h726a3e6_304.tar.bz2: 48%|####7 | 46/96 [03:40<08:26, 10.14s/it] Extracting : brotlipy-0.7.0-py37hb5d75c8_1001.tar.bz2: 49%|####8 | 47/96 [03:40<08:16, 10.14s/it] Extracting : six-1.15.0-pyh9f0ad1d_0.tar.bz2: 50%|##### | 48/96 [03:40<08:06, 10.14s/it] Extracting : sqlite-3.33.0-h4cf870e_1.tar.bz2: 51%|#####1 | 49/96 [03:40<07:56, 10.14s/it] Extracting : xz-5.2.5-h516909a_1.tar.bz2: 52%|#####2 | 50/96 [03:40<07:46, 10.14s/it] Extracting : mkl_fft-1.2.0-py37h161383b_1.tar.bz2: 53%|#####3 | 51/96 [03:40<07:36, 10.14s/it] Extracting : urllib3-1.25.11-py_0.tar.bz2: 54%|#####4 | 52/96 [03:40<07:25, 10.14s/it] Extracting : conda-4.8.3-py37_0.tar.bz2: 55%|#####5 | 53/96 [03:40<07:15, 10.14s/it] Extracting : mkl_random-1.2.0-py37h9fdb41a_1.tar.bz2: 56%|#####6 | 54/96 [03:40<07:05, 10.14s/it] Extracting : lark-parser-0.10.0-pyh9f0ad1d_0.tar.bz2: 57%|#####7 | 55/96 [03:40<06:55, 10.14s/it] Extracting : zlib-1.2.11-h516909a_1010.tar.bz2: 58%|#####8 | 56/96 [03:40<06:45, 10.14s/it] Extracting : wheel-0.35.1-pyh9f0ad1d_0.tar.bz2: 59%|#####9 | 57/96 [03:40<06:35, 10.14s/it] Extracting : tqdm-4.51.0-pyh9f0ad1d_0.tar.bz2: 60%|###### | 58/96 [03:40<06:25, 10.14s/it] Extracting : libgcc-ng-9.3.0-h5dbcf3e_17.tar.bz2: 61%|######1 | 59/96 [03:40<06:15, 10.14s/it] Extracting : _libgcc_mutex-0.1-conda_forge.tar.bz2: 62%|######2 | 60/96 [03:40<06:04, 10.14s/it] Extracting : numba-0.51.2-py37h9fdb41a_0.tar.bz2: 64%|######3 | 61/96 [03:40<05:54, 10.14s/it] Extracting : llvmlite-0.34.0-py37h5202443_2.tar.bz2: 65%|######4 | 62/96 [03:40<05:44, 10.14s/it] Extracting : certifi-2020.6.20-py37he5f6b98_2.tar.bz2: 66%|######5 | 63/96 [03:40<05:34, 10.14s/it] Extracting : torchani-2.2-pyh9f0ad1d_0.tar.bz2: 67%|######6 | 64/96 [03:40<05:24, 10.14s/it] Extracting : ld_impl_linux-64-2.35-h769bd43_9.tar.bz2: 68%|######7 | 65/96 [03:40<05:14, 10.14s/it] Extracting : pycparser-2.20-pyh9f0ad1d_2.tar.bz2: 69%|######8 | 66/96 [03:40<05:04, 10.14s/it] Extracting : ca-certificates-2020.11.8-ha878542_0.tar.bz2: 70%|######9 | 67/96 [03:40<04:53, 10.14s/it] Extracting : pysocks-1.7.1-py37he5f6b98_2.tar.bz2: 71%|####### | 68/96 [03:40<04:43, 10.14s/it] Extracting : cryptography-3.2.1-py37hc72a4ac_0.tar.bz2: 72%|#######1 | 69/96 [03:40<04:33, 10.14s/it] Extracting : python-dateutil-2.8.1-py_0.tar.bz2: 73%|#######2 | 70/96 [03:40<04:23, 10.14s/it] Extracting : acemd3-3.3.0-cuda100_0.tar.bz2: 74%|#######3 | 71/96 [03:40<04:13, 10.14s/it] Extracting : tk-8.6.10-hed695b0_1.tar.bz2: 75%|#######5 | 72/96 [03:40<04:03, 10.14s/it] Extracting : mkl-service-2.3.0-py37h8f50634_2.tar.bz2: 76%|#######6 | 73/96 [03:40<03:53, 10.14s/it] Extracting : _openmp_mutex-4.5-1_llvm.tar.bz2: 77%|#######7 | 74/96 [03:40<03:42, 10.14s/it] Extracting : readline-8.0-he28a2e2_2.tar.bz2: 78%|#######8 | 75/96 [03:40<03:32, 10.14s/it] Extracting : decorator-4.4.2-py_0.tar.bz2: 79%|#######9 | 76/96 [03:40<03:22, 10.14s/it] Extracting : python_abi-3.7-1_cp37m.tar.bz2: 80%|######## | 77/96 [03:40<03:12, 10.14s/it] Extracting : setuptools-49.6.0-py37he5f6b98_2.tar.bz2: 81%|########1 | 78/96 [03:40<03:02, 10.14s/it] Extracting : libgfortran4-7.5.0-hae1eefd_17.tar.bz2: 82%|########2 | 79/96 [03:40<02:52, 10.14s/it] Extracting : acemd3-3.3.0_72_gcceda4a-cuda102_0.tar.bz2: 83%|########3 | 80/96 [03:40<02:42, 10.14s/it] Extracting : ninja-1.10.1-hfc4b9b4_2.tar.bz2: 84%|########4 | 81/96 [03:40<02:32, 10.14s/it] Extracting : idna-2.10-pyh9f0ad1d_0.tar.bz2: 85%|########5 | 82/96 [03:40<02:21, 10.14s/it] Extracting : requests-2.24.0-pyh9f0ad1d_0.tar.bz2: 86%|########6 | 83/96 [03:40<02:11, 10.14s/it] Extracting : openssl-1.1.1h-h516909a_0.tar.bz2: 88%|########7 | 84/96 [03:40<02:01, 10.14s/it] Extracting : pytorch-1.6.0-py3.7_cuda10.2.89_cudnn7.6.5_0.tar.bz2: 89%|########8 | 85/96 [04:56<01:51, 10.14s/it] Extracting : pytorch-1.6.0-py3.7_cuda10.2.89_cudnn7.6.5_0.tar.bz2: 90%|########9 | 86/96 [04:56<01:15, 7.55s/it] Extracting : pytz-2020.4-pyhd8ed1ab_0.tar.bz2: 90%|########9 | 86/96 [04:56<01:15, 7.55s/it] Extracting : nnpops-pytorch-0.0.0a3-0.tar.bz2: 91%|######### | 87/96 [04:56<01:07, 7.55s/it] Extracting : chardet-3.0.4-py37he5f6b98_1008.tar.bz2: 92%|#########1| 88/96 [04:56<01:00, 7.55s/it] Extracting : pip-20.2.4-py_0.tar.bz2: 93%|#########2| 89/96 [04:56<00:52, 7.55s/it] Extracting : pandas-1.1.4-py37h10a2094_0.tar.bz2: 94%|#########3| 90/96 [04:56<00:45, 7.55s/it] Extracting : libgfortran-ng-7.5.0-hae1eefd_17.tar.bz2: 95%|#########4| 91/96 [04:56<00:37, 7.55s/it] Extracting : llvm-openmp-11.0.0-hfc4b9b4_1.tar.bz2: 96%|#########5| 92/96 [04:56<00:30, 7.55s/it] Extracting : moleculekit-0.4.4-py37_0.tar.bz2: 97%|#########6| 93/96 [04:56<00:22, 7.55s/it] Extracting : python-3.7.8-h6f2ec95_1_cpython.tar.bz2: 98%|#########7| 94/96 [04:56<00:15, 7.55s/it] Extracting : pyopenssl-19.1.0-py_1.tar.bz2: 99%|#########8| 95/96 [04:56<00:07, 7.55s/it] 12:56:52 (69060): /usr/bin/flock exited; CPU time 141.751422 application ./gpugridpy/bin/python missing </stderr_txt> ]]> | |
| ID: 56164 | Rating: 0 | rate:
| |
|
biodoc Send message Joined: 26 Aug 08 Posts: 183 Credit: 10,085,929,375 RAC: 2,083,841 Level Scientific publications | |
|
@azmodes, all of my python tasks have failed with the same error. Resetting the project did not make a difference. | |
| ID: 56165 | Rating: 0 | rate:
| |
|
rod4x4 Send message Joined: 4 Aug 14 Posts: 266 Credit: 2,219,935,054 RAC: 0 Level Scientific publications | |
@azmodes, all of my python tasks have failed with the same error. Resetting the project did not make a difference. Also have the same error application ./gpugridpy/bin/python missing The next line on successful tasks would normally be : wrapper: running ./gpugridpy/bin/python (run.py) Issue seems to be with further testing from Project Admin. There is a preliminary step to setup the environment for the app. This step is writing files to /tmp/ instead of the /var/lib/boinc-client/slots/ directory (This is the error for missing files). Hence the above error. Nothing wrong with your system. These tasks are Experimental. Errors are to be expected. | |
| ID: 56166 | Rating: 0 | rate:
| |
|
Ian&Steve C. Send message Joined: 21 Feb 20 Posts: 1069 Credit: 40,231,533,983 RAC: 527 Level Scientific publications | |
|
I did have one successful task today, but it might have been from the old set. | |
| ID: 56169 | Rating: 0 | rate:
| |
|
Richard Haselgrove Send message Joined: 11 Jul 09 Posts: 1620 Credit: 8,822,866,430 RAC: 19,442,844 Level Scientific publications | |
|
I had a long series of failures on 537311 earlier today, while I was out. Then saw that I had two waiting to run on 508381 - looked through the task specs, but couldn't see anything odd. And behold, they're now running normally (one approaching 50%). First-run tasks, created around 16:20 UTC today, so maybe they've found the fault and sent out a new batch. | |
| ID: 56170 | Rating: 0 | rate:
| |
|
Richard Haselgrove Send message Joined: 11 Jul 09 Posts: 1620 Credit: 8,822,866,430 RAC: 19,442,844 Level Scientific publications | |
|
The first one finished successfully, but its replacement has a different early failure: ERROR: /home/user/conda/conda-bld/acemd3_1592833101337/work/src/mdio/amberparm.cpp line 70: Failed to open PRMTOP file! | |
| ID: 56171 | Rating: 0 | rate:
| |
|
Ian&Steve C. Send message Joined: 21 Feb 20 Posts: 1069 Credit: 40,231,533,983 RAC: 527 Level Scientific publications | |
|
interesting error message on this one too. looks like it ran to term, but file size too big to upload upload failure: <file_xfer_error> http://gpugrid.net/result.php?resultid=32369678 ____________ | |
| ID: 56172 | Rating: 0 | rate:
| |
|
Had one finish and validate.
Started with a Time Remaining of 189 days Used under 400mb of GPU ram | |
| ID: 56173 | Rating: 0 | rate:
| |
|
Azmodes Send message Joined: 7 Jan 17 Posts: 34 Credit: 1,371,429,518 RAC: 0 Level Scientific publications | |
|
I'll be removing this for the time being. Been getting a lot of tasks that error out after hours, lots of wasted computing time. | |
| ID: 56178 | Rating: 0 | rate:
| |
|
biodoc Send message Joined: 26 Aug 08 Posts: 183 Credit: 10,085,929,375 RAC: 2,083,841 Level Scientific publications | |
interesting error message on this one too. looks like it ran to term, but file size too big to upload I've had quite a few of these errors. From boinc messages: 52988: 29-Dec-2020 11:24:44 (low) [GPUGRID] Output file 2za0216000-RAIMIS_NNPMM-0-1-RND5553_3_0 for task 2za0216000-RAIMIS_NNPMM-0-1-RND5553_3 exceeds size limit. 52989: 29-Dec-2020 11:24:44 (low) [GPUGRID] File size: 158101319.000000 bytes. Limit: 100000000.000000 bytes | |
| ID: 56179 | Rating: 0 | rate:
| |
|
biodoc Send message Joined: 26 Aug 08 Posts: 183 Credit: 10,085,929,375 RAC: 2,083,841 Level Scientific publications | |
interesting error message on this one too. looks like it ran to term, but file size too big to upload I went through the event log to look for more of the "output file exceeds size limit" errors. It looks like increasing the file upload size limit to 160000000 bytes or more would eliminate this problem. 53027: 29-Dec-2020 11:53:12 (low) [GPUGRID] File size: 123705476.000000 bytes. Limit: 100000000.000000 bytes 53019: 29-Dec-2020 11:30:56 (low) [GPUGRID] File size: 107341284.000000 bytes. Limit: 100000000.000000 bytes 52989: 29-Dec-2020 11:24:44 (low) [GPUGRID] File size: 158101319.000000 bytes. Limit: 100000000.000000 bytes 52981: 29-Dec-2020 10:50:22 (low) [GPUGRID] File size: 123461155.000000 bytes. Limit: 100000000.000000 bytes 52908: 29-Dec-2020 08:38:07 (low) [GPUGRID] File size: 123677635.000000 bytes. Limit: 100000000.000000 bytes 52870: 29-Dec-2020 08:18:04 (low) [GPUGRID] File size: 158191729.000000 bytes. Limit: 100000000.000000 bytes 52816: 29-Dec-2020 07:01:51 (low) [GPUGRID] File size: 138164005.000000 bytes. Limit: 100000000.000000 bytes 52808: 29-Dec-2020 06:25:55 (low) [GPUGRID] File size: 158342958.000000 bytes. Limit: 100000000.000000 bytes 52800: 29-Dec-2020 06:13:12 (low) [GPUGRID] File size: 158116895.000000 bytes. Limit: 100000000.000000 bytes 52781: 29-Dec-2020 05:33:28 (low) [GPUGRID] File size: 107236868.000000 bytes. Limit: 100000000.000000 bytes 52743: 29-Dec-2020 04:32:48 (low) [GPUGRID] File size: 138252720.000000 bytes. Limit: 100000000.000000 bytes 52645: 29-Dec-2020 02:03:47 (low) [GPUGRID] File size: 123487055.000000 bytes. Limit: 100000000.000000 bytes 52482: 29-Dec-2020 00:57:04 (low) [GPUGRID] File size: 123503099.000000 bytes. Limit: 100000000.000000 bytes 52343: 28-Dec-2020 23:55:57 (low) [GPUGRID] File size: 107409143.000000 bytes. Limit: 100000000.000000 bytes | |
| ID: 56180 | Rating: 0 | rate:
| |
|
Richard Haselgrove Send message Joined: 11 Jul 09 Posts: 1620 Credit: 8,822,866,430 RAC: 19,442,844 Level Scientific publications | |
interesting error message on this one too. looks like it ran to term, but file size too big to upload I can confirm that. I had four resends running this morning, which had failed this way on their previous hosts. There's only one upload file for these tasks, which makes things easier. The limit is set at 100 (decimal) MB, or 95.3674 (binary) MiB. I changed that with an extra zero, and they ran to completion. The upload files ended at up to 135 MB, but uploaded fine and validated. Instructions and notes 1) the tasks I worked on were reporting progress every 0.180%, but the latest ones are updating every 0.450%. Another change. 2) they claim to checkpoint each time, but don't. They restart right back at 10%, and previous work is lost (the output file starts again at 0 MB). 3) But the recorded runtime is not lost, and continues to increase. Anybody on the brink of the 20 credit sanity-check, take care. How to a) Let a new task start. I'd advise you let it run to 10.450% or whatever, to get past the 'Failed to open PRMTOP file!' failure point. b) Stop the BOINC client, by whatever means is appropriate for your version of Linux. c) Navigate to the BOINC data directory - often /var/lib/boinc-client, but YMMV. d) Make sure you have write access - may need sudo or similar. e) Open the file client_state.xml with a plain text editor. f) Find the start of the GPUGrid project section. g) Within that section, find the <file> description which contains an <upload_url> entry. h) A couple of lines above, you should see <max_nbytes>100000000.000000</max_nbytes> Make that number bigger. I'd suggest allowing plenty of headroom - change the '1' to '2', or simply add a nought to make it ten times bigger.i) Check that you have made no other changes to values or formats - this file is fragile. j) Save it, and restart the BOINC client. You should be good to go, but check it's running properly before you walk away. | |
| ID: 56184 | Rating: 0 | rate:
| |
|
Is it possible to have the app clean up after itself in the /tmp folder? Each task leaves multiple files. Keep in mind that some people use ram for their /tmp folder, so zombie files are wasting ram -rw-r--r-- 1 boinc boinc 43314 Dec 28 10:23 7ea97c91d7361ec56632bfca26d5d9d13d642930_75_64 -rw-r--r-- 1 boinc boinc 126286 Dec 28 10:23 e0ef5982e1b68c789da96dc45363b9eb8c2aa57e_75_64 -rw-r--r-- 1 boinc boinc 80597 Dec 28 10:23 b4482d8d58bb8c6d2b7a91f73e7b773c0fd5dd94_75_64 -rw-r--r-- 1 boinc boinc 20647 Dec 28 10:23 714822709ce1b8bc002bdbbf552e28e75c6da4e6_75_64 -rw-r--r-- 1 boinc boinc 4733 Dec 28 10:23 fcf820cc959eabea7aebe1c17b691a0c2f4b0ff7_75_64 -rw-r--r-- 1 boinc boinc 10245 Dec 28 10:23 50f9f113993bfc730988bdc619171c634a15523f_75_64 -rw-r--r-- 1 boinc boinc 30374 Dec 28 10:23 f2dab3f09e77bbb4575c7ddc986723c25d6a4f3d_75_64 -rw-r--r-- 1 boinc boinc 20869 Dec 28 10:23 91f4a5a43a8501dea5dc4332cf4e8f9f5fd0359a_75_64 -rw-r--r-- 1 boinc boinc 13716 Dec 28 10:23 7980fb2556658945503bd805a0d8e93a948e72ba_75_64 -rw-r--r-- 1 boinc boinc 30377 Dec 28 10:23 93916279bb5343117c8bdbd1338022d943b665dc_75_64 -rw-r--r-- 1 boinc boinc 57843 Dec 28 10:23 7a1eb9372723ed7381f98389a26fd422b3bacdc9_75_64 -rw-r--r-- 1 boinc boinc 35422 Dec 28 10:23 39066daa18fdb7f9d5831a3a738a007a1c33bb21_75_64 -rw-r--r-- 1 boinc boinc 36936 Dec 28 10:23 97a2b7cad094f060cf83fbee7aa045351955025d_75_64 -rw-r--r-- 1 boinc boinc 36936 Dec 28 10:23 8764d8337c744fb5661e0b67108406e054c1ecf7_75_64 -rw-r--r-- 1 boinc boinc 126286 Dec 28 14:28 971f8bb04c1c0504d9d6226436fdcc5d07886be4_75_64 -rw-r--r-- 1 boinc boinc 80619 Dec 28 14:28 a102f87703190d04f8f9faa27478ab445379a41e_75_64 -rw-r--r-- 1 boinc boinc 10245 Dec 28 14:28 bceacf79d9e3a7852ce16958202b232509caa430_75_64 -rw-r--r-- 1 boinc boinc 30376 Dec 28 14:28 de46595abda900c61564054a4bd137ee3d70c9dd_75_64 -rw-r--r-- 1 boinc boinc 30379 Dec 28 14:28 b7c29d7e65c014012b9fd8c8c80b17c0e781422c_75_64 -rw-r--r-- 1 boinc boinc 57839 Dec 28 14:28 d12a034ced08fa013e7e9ba14395bb50e706b7c4_75_64 -rw-r--r-- 1 boinc boinc 35422 Dec 28 14:28 f58184112e590f9b8bac2ca1ba27f19730db8fe1_75_64 -rw-r--r-- 1 boinc boinc 36936 Dec 28 14:28 38eba1979b0e8c5c6c8337db39ec5e693353efd2_75_64 -rw-r--r-- 1 boinc boinc 36936 Dec 28 14:28 18682cb468a4f7ffe709f43654f80b950fd71e3e_75_64 -rw-r--r-- 1 boinc boinc 126295 Dec 28 18:18 9d841da4897f17abb1063a155a32a239510006d4_75_64 -rw-r--r-- 1 boinc boinc 80223 Dec 28 18:18 8f5b905c553a27de4570db40320a32e00282e107_75_64 -rw-r--r-- 1 boinc boinc 10245 Dec 28 18:18 87be55f7f9b2231f4bf29107ba0bc5586e26d8cc_75_64 -rw-r--r-- 1 boinc boinc 30391 Dec 28 18:18 56e68b46f69582f6255d5a6ea2b6c106147735ba_75_64 -rw-r--r-- 1 boinc boinc 30394 Dec 28 18:19 ee66161b69723e8e712d6305af6a5b0af4cb7d70_75_64 -rw-r--r-- 1 boinc boinc 57843 Dec 28 18:19 b0adc452ed6fa6fd24c9741c2b96482e35fa3923_75_64 -rw-r--r-- 1 boinc boinc 35428 Dec 28 18:19 742b600f272127103bb928076a71f4cd8c5bd736_75_64 -rw-r--r-- 1 boinc boinc 36942 Dec 28 18:19 9156034baf2ffa58ec15e153da37e52b70e396c2_75_64 -rw-r--r-- 1 boinc boinc 36942 Dec 28 18:19 60c5e6cea54031315f04913098148579068979fc_75_64 -rw-r--r-- 1 boinc boinc 126286 Dec 29 00:55 9233bab642d82fd791010f41501ae4d00de9a064_75_64 -rw-r--r-- 1 boinc boinc 80619 Dec 29 00:55 1700e1fa0b176d84ed7d27df18324a520188c225_75_64 -rw-r--r-- 1 boinc boinc 10245 Dec 29 00:55 5e0d2da29ad9b0dfc82c54d591826bf8ff0d142d_75_64 -rw-r--r-- 1 boinc boinc 30374 Dec 29 00:55 46d78c01e997eb624412f6a569d66daa53d1e29a_75_64 -rw-r--r-- 1 boinc boinc 30377 Dec 29 00:55 48b2935cd5e3da2f016c3332beb1a19cbd86e466_75_64 -rw-r--r-- 1 boinc boinc 57843 Dec 29 00:55 0e1f699fe80e24604c63598f5d787edeb8ea9f4e_75_64 -rw-r--r-- 1 boinc boinc 35422 Dec 29 00:55 a794b2186bfc30990054ab3ebb0426ce27632b6f_75_64 -rw-r--r-- 1 boinc boinc 36936 Dec 29 00:55 9d9a624fc68aa25d518928890e6ac3b36ca1d0cd_75_64 -rw-r--r-- 1 boinc boinc 36936 Dec 29 00:55 a836e46556989dc15e437e80577ddaa7c6393b75_75_64 -rw-r--r-- 1 boinc boinc 126286 Dec 29 04:51 fb42a08ad7eca6be05c99ee38f3b4f71f1a717b9_75_64 -rw-r--r-- 1 boinc boinc 80619 Dec 29 04:51 8408b5d9e631d0726f455499a816face8bab4174_75_64 -rw-r--r-- 1 boinc boinc 10245 Dec 29 04:51 e5cb623ff3b139a425e04b40a7c572c3005561d3_75_64 -rw-r--r-- 1 boinc boinc 30376 Dec 29 04:51 32c1d753d0db123091d675f042cf383ec465b4d9_75_64 -rw-r--r-- 1 boinc boinc 30379 Dec 29 04:51 b42845ba5a8b020687c1285c4f36c70f62a4ab9f_75_64 -rw-r--r-- 1 boinc boinc 57839 Dec 29 04:51 800c239c9c2ea4abf6b56821da41bd95c7dfbf74_75_64 -rw-r--r-- 1 boinc boinc 35422 Dec 29 04:51 2fa8fe0195793ba7d4867aeeca60dcd4c3941b88_75_64 -rw-r--r-- 1 boinc boinc 36936 Dec 29 04:51 1e91dd22529e2e5af37a6c1c356af9d7f3ffcf12_75_64 -rw-r--r-- 1 boinc boinc 36936 Dec 29 04:51 27c226ae18af868c3e7195046dd14dea61bf4101_75_64 -rw-r--r-- 1 boinc boinc 126295 Dec 29 08:26 8520d639fa8271b8962c3da8ae2803659d270827_75_64 -rw-r--r-- 1 boinc boinc 80223 Dec 29 08:26 ae54db82a21c8e2e5747967ed4f68427e90509bc_75_64 -rw-r--r-- 1 boinc boinc 10245 Dec 29 08:26 17fea8103490d36bfce7b9443641dfdedd2e24bb_75_64 -rw-r--r-- 1 boinc boinc 30391 Dec 29 08:26 33c9c1c55d8a8cb2db72b91b3344b4f33f5f15da_75_64 -rw-r--r-- 1 boinc boinc 30394 Dec 29 08:26 a6514953bc083c082f2ad6ebe386904bf2576ee2_75_64 -rw-r--r-- 1 boinc boinc 57845 Dec 29 08:26 573ac214fa460acfe44af24489e461d6aa3107ef_75_64 -rw-r--r-- 1 boinc boinc 35428 Dec 29 08:26 8ead506b530d7fe93e46f3a28ca9e77798609101_75_64 -rw-r--r-- 1 boinc boinc 36942 Dec 29 08:27 a1bee26d81077fe4b29a180e84aab497b09097d0_75_64 -rw-r--r-- 1 boinc boinc 36942 Dec 29 08:27 482ad04da8945ca75cd26712d462e899addae4f7_75_64 At the moment, I'm just asking for a task to do some cleanup when it finishes. Don't like seeing boinc outside of the boinc folder. | |
| ID: 56188 | Rating: 0 | rate:
| |
|
ServicEnginIC Send message Joined: 24 Sep 10 Posts: 581 Credit: 9,768,112,024 RAC: 21,327,418 Level Scientific publications | |
Returning to graphics card RAM size and Python tasks: After the last rebuilt of Python tasks on December 29th, all my 2 GB VRAM graphics cards have started to succeed them: These cards are based on GTX 750, GTX 750 TI, GTX 950, and GT 1030 GPUs. Also failures regarding "file size too big" disappeared. Some entity in the background seems to know well what is handling... | |
| ID: 56211 | Rating: 0 | rate:
| |
|
Ian&Steve C. Send message Joined: 21 Feb 20 Posts: 1069 Credit: 40,231,533,983 RAC: 527 Level Scientific publications | |
|
yeah i noticed the baseline behavior changed from the last round of Python to this latest round. | |
| ID: 56212 | Rating: 0 | rate:
| |
|
ServicEnginIC Send message Joined: 24 Sep 10 Posts: 581 Credit: 9,768,112,024 RAC: 21,327,418 Level Scientific publications | |
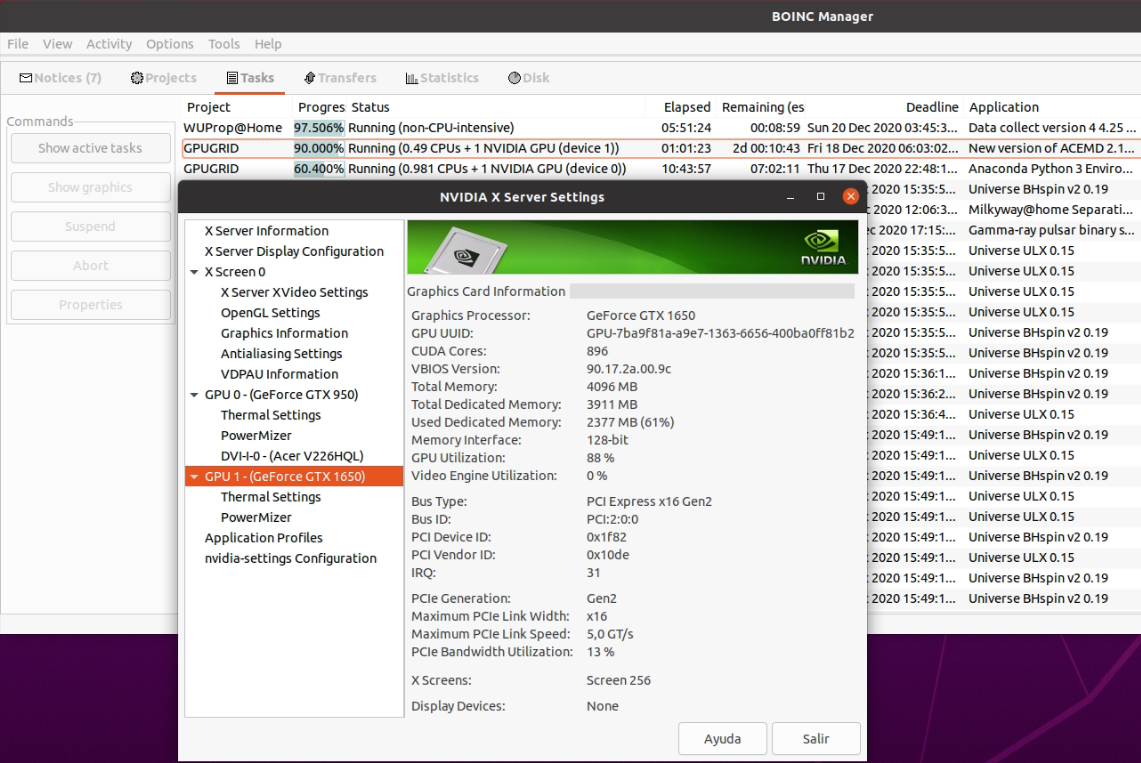
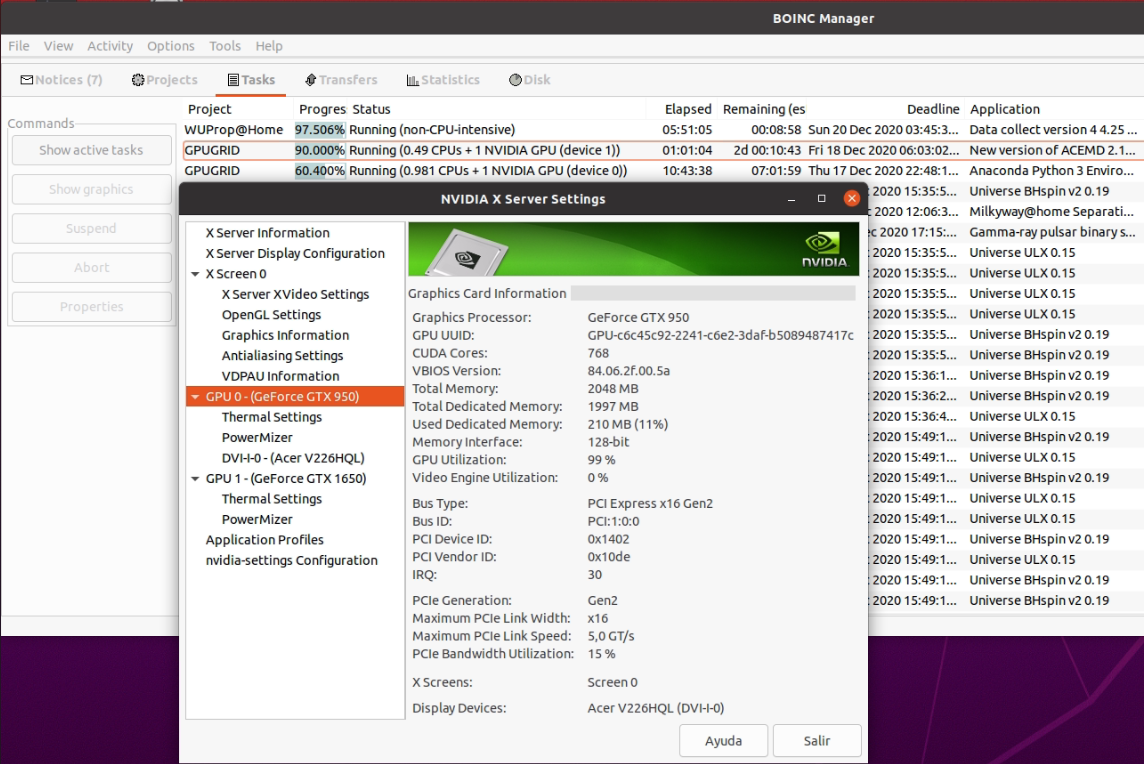
|
This week (february 22nd) I happened to catch one RAIMIS Python mt CPU task and an ADRIA ACEMD3 GPU task that ran concurrently. | |
| ID: 58387 | Rating: 0 | rate:
| |
|
Retvari Zoltan Send message Joined: 20 Jan 09 Posts: 2343 Credit: 16,206,655,749 RAC: 261,147 Level Scientific publications | |
|
I've made that observation back in 2017 on my 4th generation CPUs. I'm avare that this haven't changed much throughout the years, so I basically don't run CPU tasks and GPU tasks simultaneously on the same PC, except when I need that much heat output in the winter. Lately I rather reanimate a few older GPUs, instead of crunching on CPUs. | |
| ID: 58389 | Rating: 0 | rate:
| |
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Message boards : Number crunching : Anaconda Python 3 Environment v4.01 failures