Message boards : Number crunching : Unsent tasks decreasing much more slowly
| Author | Message |
|---|---|
|
WPrion Send message Joined: 30 Apr 13 Posts: 96 Credit: 2,643,434,111 RAC: 20,025,528 Level Scientific publications | |
|
I've noticed that the number of Unsent Tasks is decreasing at a much slower rate even though the number of tasks in progress is growing and the Current GigaFLOPS is approaching record levels. | |
| ID: 54312 | Rating: 0 | rate:
| |
 Retvari Zoltan Retvari ZoltanSend message Joined: 20 Jan 09 Posts: 2343 Credit: 16,206,655,749 RAC: 261,147 Level Scientific publications | |
|
Toni prioritized some batches before, those have run out. That made the number of unsent task to decrease more rapidly. | |
| ID: 54314 | Rating: 0 | rate:
| |
|
WPrion Send message Joined: 30 Apr 13 Posts: 96 Credit: 2,643,434,111 RAC: 20,025,528 Level Scientific publications | |
|
Thanks! | |
| ID: 54317 | Rating: 0 | rate:
| |
|
ServicEnginIC Send message Joined: 24 Sep 10 Posts: 581 Credit: 9,770,362,024 RAC: 21,500,013 Level Scientific publications | |
|
On March 10th 2020 | 17:39:16 UTC Retvari Zoltan wrote at message #53884: I'm receiving many tasks which are the last one of their batch: At this time, the number of unsent tasks is 243.556, as can be seen at Server status page. The last tasks I'm currently receiving are similar to: 3tekA00_320_3-TONI_MDADpr4st-8-10-RND9554_0 As soon as series arrives 9-10 ones, it is predictable that unsent tasks will decrease again at a higher rate... (?) | |
| ID: 54579 | Rating: 0 | rate:
| |
|
ServicEnginIC Send message Joined: 24 Sep 10 Posts: 581 Credit: 9,770,362,024 RAC: 21,500,013 Level Scientific publications | |
As soon as series arrives 9-10 ones, it is predictable that unsent tasks will decrease again at a higher rate... (?) All my received WUs today are this kind. Current reading is 242.563 unsent tasks. We will be soon confirming or discarding this assumption. | |
| ID: 54604 | Rating: 0 | rate:
| |
|
Retvari Zoltan Send message Joined: 20 Jan 09 Posts: 2343 Credit: 16,206,655,749 RAC: 261,147 Level Scientific publications | |
I'm sure that the number of unsent tasks will drop drastically in the next few days.As soon as series arrives 9-10 ones, it is predictable that unsent tasks will decrease again at a higher rate... (?)All my received WUs today are this kind. The only question is the bottom of that drop. It depends on the priority of the tasks in the queue. If it's uniform, the number of unsent tasks will drop near 0, only the tasks stuck in slow or inactive hosts will remain in the queue (~1000 in this case). If there are lower priority tasks than the ones we receive now, then we will receive those soon. We will know if that's the case as they will have low sequence number (for example 3-10). In this case the number of unsent tasks will remain high. I guess there are no lower priority tasks, so the number of unsent tasks will drop near 0. Number of unsent task is 237.790 at the moment. (-4.773 ~2% drop in 3h 45m) | |
| ID: 54607 | Rating: 0 | rate:
| |
|
Toni Volunteer moderator Project administrator Project developer Project tester Project scientist Send message Joined: 9 Dec 08 Posts: 1006 Credit: 5,068,599 RAC: 0 Level Scientific publications | |
|
I prioritised tasks ending with _0: 1gaxA04_348_0 over the others (_1 to _4) | |
| ID: 54608 | Rating: 0 | rate:
| |
|
Retvari Zoltan Send message Joined: 20 Jan 09 Posts: 2343 Credit: 16,206,655,749 RAC: 261,147 Level Scientific publications | |
Current reading is 242.563 unsent tasks. We will be soon confirming or discarding this assumption.Current reading is 222 460 that is -20 103 (8.28%) drop in 12h 20m = 27.17 / minute If this rate is constant, the present supply will last for 5 days 16 hours 28 minutes and 50.8 seconds. :) | |
| ID: 54612 | Rating: 0 | rate:
| |
|
Retvari Zoltan Send message Joined: 20 Jan 09 Posts: 2343 Credit: 16,206,655,749 RAC: 261,147 Level Scientific publications | |
The current reading is 200,361 that is 42,202 (17.4%) decrease in 24h 10m = 29.10 / minuteCurrent reading is 242.563 unsent tasks. We will be soon confirming or discarding this assumption.Current reading is 222 460 that is -20 103 (8.28%) drop in 12h 20m = 27.17 / minute The rate is slightly increased. According to this new rate, the present supply will last 4 days 18 hours 44 minutes 6.94 seconds from now .:) | |
| ID: 54613 | Rating: 0 | rate:
| |
|
ServicEnginIC Send message Joined: 24 Sep 10 Posts: 581 Credit: 9,770,362,024 RAC: 21,500,013 Level Scientific publications | |
The current reading is 200,361 that is 42,202 (17.4%) decrease in 24h 10m = 29.10 / minute -1) Mr. Zoltan: Thank you very much for making this funny. I took screenshots that are confirming your data. 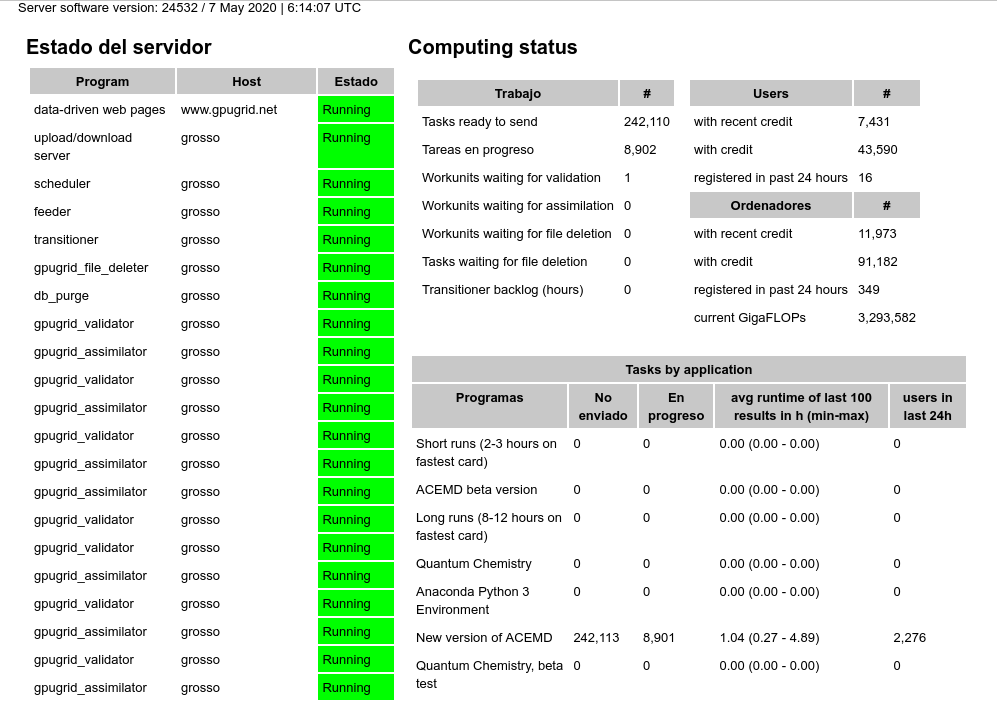 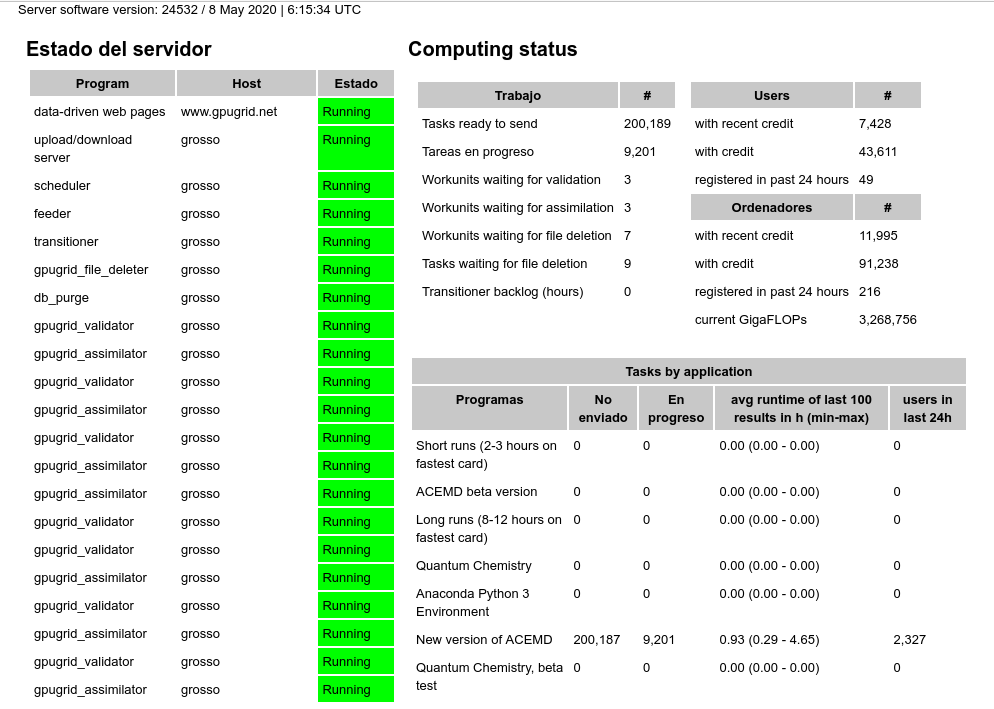 Reduction in unsent tasks: 41.926 in this about 24H lapse. -2) Mr. Toni/GPUGrid's Team: Thank you very much for your continuous support. This high decreasing rate has been greatly facilitated by exceptionally good communications since yesterday's morning. Whatever you did in the transition from May 6th to 7th, it supposed a drastic change between extremely sluggish to very agile communications. Please, take note of the recipy. At he moment of writing this, scheduler is stopped. I guess that this high rate in returning results has caused a new momentary buffer disk overflow... | |
| ID: 54618 | Rating: 0 | rate:
| |
|
Retvari Zoltan Send message Joined: 20 Jan 09 Posts: 2343 Credit: 16,206,655,749 RAC: 261,147 Level Scientific publications | |
The current reading is 200,361 that is 42,202 (17.4%) decrease in 24h 10m = 29.10 / minute Note that the return rate was this high all along hence there are frequent disk buffer overflows. As new tasks created from the returned tasks the number of unsent workunits remain constant, so the return rate remain hidden from us, until the batches reach their final sequence number. | |
| ID: 54621 | Rating: 0 | rate:
| |
|
ServicEnginIC Send message Joined: 24 Sep 10 Posts: 581 Credit: 9,770,362,024 RAC: 21,500,013 Level Scientific publications | |
Note that the return rate was this high all along hence there are frequent disk buffer overflows. As new tasks created from the returned tasks the number of unsent workunits remain constant, so the return rate remain hidden from us, until the batches reach their final sequence number. Yes, you're right, and I'm aware of it. Lately frequent schduler stops most probably keep relationship with this Optimized bandwith anouncement, and significantly raised number of crunchers... This combination has likely caused some bottleneck in project's resources. | |
| ID: 54622 | Rating: 0 | rate:
| |
robertmiles  Send message Joined: 16 Apr 09 Posts: 503 Credit: 755,370,933 RAC: 212,472 Level Scientific publications | |
|
It looks like the server status page needs something added - free disk space - at least for this disk areas that receive uploads. | |
| ID: 54624 | Rating: 0 | rate:
| |
|
ServicEnginIC Send message Joined: 24 Sep 10 Posts: 581 Credit: 9,770,362,024 RAC: 21,500,013 Level Scientific publications | |
|
One more conclusion that could be drawn: | |
| ID: 54631 | Rating: 0 | rate:
| |
|
Richard Haselgrove Send message Joined: 11 Jul 09 Posts: 1620 Credit: 8,822,866,430 RAC: 19,442,844 Level Scientific publications | |
|
What we don't know - at least, I certainly don't know, and I've not seen it described here, ever - is what exactly the processing path of that data is after our raw results are returned to the server. | |
| ID: 54632 | Rating: 0 | rate:
| |
|
ServicEnginIC Send message Joined: 24 Sep 10 Posts: 581 Credit: 9,770,362,024 RAC: 21,500,013 Level Scientific publications | |
|
Project's scheduler is just up again, with 174.874 tasks left ready to send! | |
| ID: 54640 | Rating: 0 | rate:
| |
|
ServicEnginIC Send message Joined: 24 Sep 10 Posts: 581 Credit: 9,770,362,024 RAC: 21,500,013 Level Scientific publications | |
|
All my stacked WUs have been reported as finished, and all (but one 8-10) the new WUs I've received are of the kind 9-10. | |
| ID: 54641 | Rating: 0 | rate:
| |
|
Retvari Zoltan Send message Joined: 20 Jan 09 Posts: 2343 Credit: 16,206,655,749 RAC: 261,147 Level Scientific publications | |
|
I have a couple of ghost tasks, so I suppose that many other ghost tasks are waiting to pass their deadline, so some 8-10 tasks will be re-send to other hosts. | |
| ID: 54642 | Rating: 0 | rate:
| |
|
Keith Myers Send message Joined: 13 Dec 17 Posts: 1340 Credit: 7,653,123,724 RAC: 13,404,739 Level Scientific publications | |
|
What is the ghost recovery procedure on this project? | |
| ID: 54650 | Rating: 0 | rate:
| |
|
ServicEnginIC Send message Joined: 24 Sep 10 Posts: 581 Credit: 9,770,362,024 RAC: 21,500,013 Level Scientific publications | |
|
Ghost tasks are on GPUGRID's server side. | |
| ID: 54651 | Rating: 0 | rate:
| |
|
Retvari Zoltan Send message Joined: 20 Jan 09 Posts: 2343 Credit: 16,206,655,749 RAC: 261,147 Level Scientific publications | |
What is the ghost recovery procedure on this project?I've tried the way it works for SETI, but it didn't work here. Luckily GPUGrid has a much shorter deadline than SETI, so it's not a big problem. | |
| ID: 54652 | Rating: 0 | rate:
| |
|
Retvari Zoltan Send message Joined: 20 Jan 09 Posts: 2343 Credit: 16,206,655,749 RAC: 261,147 Level Scientific publications | |
the present supply (171,016) will last for about 4 days from now.The rate of decline seems to stabilize around 30/minute, so the supply will last for about 3 days from now. (exactly 2 days 22 hours 39 minutes and 42.9 seconds) | |
| ID: 54653 | Rating: 0 | rate:
| |
|
ServicEnginIC Send message Joined: 24 Sep 10 Posts: 581 Credit: 9,770,362,024 RAC: 21,500,013 Level Scientific publications | |
Ghost tasks are on GPUGRID's server side. [Clarification] We call "Ghost task" to that the server counts as sent to a Host, but for any reason, it was not really received. It doesn't interfere at the host side, as BOINC Manager will not see these ghost tasks, and it will continue asking for new tasks until tasks buffer is full, or maximum "2 tasks per GPU" is achieved. On the server's side, ghost tasks are wrongly being counted as "In process" tasks, while really they are not. | |
| ID: 54654 | Rating: 0 | rate:
| |
|
ServicEnginIC Send message Joined: 24 Sep 10 Posts: 581 Credit: 9,770,362,024 RAC: 21,500,013 Level Scientific publications | |
The rate of decline seems to stabilize around 30/minute, so the supply will last for about 3 days from now. What is coming next, is a mystery... | |
| ID: 54656 | Rating: 0 | rate:
| |
|
Keith Myers Send message Joined: 13 Dec 17 Posts: 1340 Credit: 7,653,123,724 RAC: 13,404,739 Level Scientific publications | |
What is the ghost recovery procedure on this project?I've tried the way it works for SETI, but it didn't work here. Thanks Zoltan, I tried my Seti ghost recovery protocol and it didn't work either. I managed to pick up 10 ghosts and wanted to clear them. Good thing the deadline here is so short compared to Seti. | |
| ID: 54660 | Rating: 0 | rate:
| |
|
Pop Piasa Send message Joined: 8 Aug 19 Posts: 252 Credit: 458,054,251 RAC: 0 Level Scientific publications | |
|
These ghost tasks seem to occur after the server runs out of disk space. Are they somehow related to that? 🤔 (unknown error) - exit code 195 (0xc3)</message> It apparently signals that the WU is bad- when you track them. After getting 6 of them I'm curious what the bug might be. Bad code? | |
| ID: 54662 | Rating: 0 | rate:
| |
|
Ian&Steve C. Send message Joined: 21 Feb 20 Posts: 1069 Credit: 40,231,533,983 RAC: 527 Level Scientific publications | |
|
yes, I saw a bunch of bad WUs. checking the resends, they are all erroring out also on different hosts. | |
| ID: 54663 | Rating: 0 | rate:
| |
|
Keith Myers Send message Joined: 13 Dec 17 Posts: 1340 Credit: 7,653,123,724 RAC: 13,404,739 Level Scientific publications | |
|
Looks like a lot of tasks lost their file references on the storage. Can't pull the correct data for the tasks. <core_client_version>7.17.0</core_client_version> <![CDATA[ <message> ERROR: /home/user/conda/conda-bld/acemd3_1570536635323/work/src/mdsim/trajectory.cpp line 135: Simulation box has to be rectangular! 07:01:16 (1119448): acemd3 exited; CPU time 0.557061 07:01:16 (1119448): app exit status: 0x9e 07:01:16 (1119448): called boinc_finish(195) | |
| ID: 54664 | Rating: 0 | rate:
| |
|
Richard Haselgrove Send message Joined: 11 Jul 09 Posts: 1620 Credit: 8,822,866,430 RAC: 19,442,844 Level Scientific publications | |
|
I'm interpreting that message as "file is present, but contains bad contents". | |
| ID: 54665 | Rating: 0 | rate:
| |
|
Aurum Send message Joined: 12 Jul 17 Posts: 401 Credit: 16,755,010,632 RAC: 220,113 Level Scientific publications | |
The rate of decline seems to stabilize around 30/minute, so the supply will last for about 3 days from now. And what we're finishing now is a complete and utter mystery as well. | |
| ID: 54666 | Rating: 0 | rate:
| |
|
Pop Piasa Send message Joined: 8 Aug 19 Posts: 252 Credit: 458,054,251 RAC: 0 Level Scientific publications | |
And what we're finishing now is a complete and utter mystery as well I've only been able to glean that it is a vigorous attempt at mapping the simulation environment which is meant to improve (or simplify?) future modeling methods. If one of the admins would want to comment, we're all ears... 👂👂👂👂👂🦻👂😉 | |
| ID: 54674 | Rating: 0 | rate:
| |
|
ServicEnginIC Send message Joined: 24 Sep 10 Posts: 581 Credit: 9,770,362,024 RAC: 21,500,013 Level Scientific publications | |
|
New version of ACEMD: 73,631 Unsent tasks left | |
| ID: 54675 | Rating: 0 | rate:
| |
|
Retvari Zoltan Send message Joined: 20 Jan 09 Posts: 2343 Credit: 16,206,655,749 RAC: 261,147 Level Scientific publications | |
3 days passed, there are 11.806 workunits left, this supply will last for another 6~7 hours.the present supply (171,016) will last for about 4 days from now.The rate of decline seems to stabilize around 30/minute, so the supply will last for about 3 days from now. | |
| ID: 54686 | Rating: 0 | rate:
| |
|
Aurum Send message Joined: 12 Jul 17 Posts: 401 Credit: 16,755,010,632 RAC: 220,113 Level Scientific publications | |
|
They're all gone, so what now? | |
| ID: 54690 | Rating: 0 | rate:
| |
|
Our poor GPUs start getting hangry!! :) | |
| ID: 54691 | Rating: 0 | rate:
| |
|
ServicEnginIC Send message Joined: 24 Sep 10 Posts: 581 Credit: 9,770,362,024 RAC: 21,500,013 Level Scientific publications | |
They're all gone, so what now? I liked this expresion: ...is a complete and utter mystery... Familiar? (I took note for such a moment like this) Now that unsent tasks have reached and stuck on zero, the topic of this thread recovers full sense: Unsent tasks decreasing much more slowly (Unless negative values are permitted, who knows?) | |
| ID: 54693 | Rating: 0 | rate:
| |
|
Retvari Zoltan Send message Joined: 20 Jan 09 Posts: 2343 Credit: 16,206,655,749 RAC: 261,147 Level Scientific publications | |
They're all gone, so what now?It will take at least 5-10 days (or more) until all the workunits out in the field are finished (or timed out, and finished on another host). I don't expect that another batch will be queued until then. Exam period is coming, then the summer break is coming, so perhaps there won't be much work queued soon. Unless Toni prepared some COVID-19 related work. Or perhaps we could help out the Acellera drug design people doing their job. | |
| ID: 54696 | Rating: 0 | rate:
| |
|
Erich56 Send message Joined: 1 Jan 15 Posts: 1132 Credit: 10,205,482,676 RAC: 29,855,510 Level Scientific publications | |
|
the difference between the tasks of the current series in contrast to all the others before is: | |
| ID: 54698 | Rating: 0 | rate:
| |
|
Keith Myers Send message Joined: 13 Dec 17 Posts: 1340 Credit: 7,653,123,724 RAC: 13,404,739 Level Scientific publications | |
|
I picked up 4 resends after the RTS buffer had hit zero today. | |
| ID: 54699 | Rating: 0 | rate:
| |
|
Richard Haselgrove Send message Joined: 11 Jul 09 Posts: 1620 Credit: 8,822,866,430 RAC: 19,442,844 Level Scientific publications | |
I picked up 4 resends after the RTS buffer had hit zero today. Were they from the 'instant crashing' batch? I've had a few of those recently, though I haven't checked to see if I got any while I was asleep. | |
| ID: 54700 | Rating: 0 | rate:
| |
|
Toni Volunteer moderator Project administrator Project developer Project tester Project scientist Send message Joined: 9 Dec 08 Posts: 1006 Credit: 5,068,599 RAC: 0 Level Scientific publications | |
|
The large batch has essentially finished. If there are MDAD left, they are probably failing leftovers. | |
| ID: 54702 | Rating: 0 | rate:
| |
|
Keith Myers Send message Joined: 13 Dec 17 Posts: 1340 Credit: 7,653,123,724 RAC: 13,404,739 Level Scientific publications | |
|
No,3 in fact were original issue -1's from yesterday. Must have been the very last issued. One was a -2 resend from an aborted user. None were from the badly formatted task run. I got lucky. | |
| ID: 54707 | Rating: 0 | rate:
| |
|
Richard Haselgrove Send message Joined: 11 Jul 09 Posts: 1620 Credit: 8,822,866,430 RAC: 19,442,844 Level Scientific publications | |
|
At this project, only the _0 are original issue. _1 is already a replacement, unlike projects which use comparison validation. | |
| ID: 54709 | Rating: 0 | rate:
| |
|
Keith Myers Send message Joined: 13 Dec 17 Posts: 1340 Credit: 7,653,123,724 RAC: 13,404,739 Level Scientific publications | |
|
Thanks for correcting me Richard. I forgot about the workunits on this project with quorum of 1. | |
| ID: 54710 | Rating: 0 | rate:
| |
|
Pop Piasa Send message Joined: 8 Aug 19 Posts: 252 Credit: 458,054,251 RAC: 0 Level Scientific publications | |
|
I figure what we see trickle out for a while will be timed-out tasks that are recycled by Grosso. I'm curious as to how many tasks expire on how many hosts by the end of a run the size of this one. | |
| ID: 54713 | Rating: 0 | rate:
| |
|
Richard Haselgrove Send message Joined: 11 Jul 09 Posts: 1620 Credit: 8,822,866,430 RAC: 19,442,844 Level Scientific publications | |
|
Looks like I'm participating in that trickle-down, too. Somebody let WU 19993861 slip past it's deadline, so they tossed it back for me. | |
| ID: 54714 | Rating: 0 | rate:
| |
|
folding@home has many GPU work units now against Corona Virus. So that would be a good option. | |
| ID: 54716 | Rating: 0 | rate:
| |
|
robertmiles Send message Joined: 16 Apr 09 Posts: 503 Credit: 755,370,933 RAC: 212,472 Level Scientific publications | |
folding@home has many GPU work units now against Corona Virus. So that would be a good option. I signed up for folding@home at least a week ago, and then enabled GPU work for them. No GPU work downloaded so far, only CPU work. Also, so far, I've been unable to log into their forums. | |
| ID: 54718 | Rating: 0 | rate:
| |
|
Jim1348 Send message Joined: 28 Jul 12 Posts: 819 Credit: 1,591,285,971 RAC: 0 Level Scientific publications | |
I signed up for folding@home at least a week ago, and then enabled GPU work for them. No GPU work downloaded so far, only CPU work. Things seem to be a bit strange on Folding at the moment. I can't get to the forums either, but I have been getting work regularly (both CPU and GPU) for a couple of weeks. But on some cards I don't get any work. It is not a difference in the cards, but some of their servers have more problems than others, due to the recent growing pains. If you try later, you will probably get some. And make sure you are using their latest release. They have fixed a few bugs recently that could hang up getting work. https://foldingathome.org/start-folding/ EDIT: I think this explains it. https://foldingathome.org/2020/05/16/foldingforum-org-is-currently-out-of-service/ | |
| ID: 54719 | Rating: 0 | rate:
| |
|
robertmiles Send message Joined: 16 Apr 09 Posts: 503 Credit: 755,370,933 RAC: 212,472 Level Scientific publications | |
|
OK, that site offers a more recent version. | |
| ID: 54720 | Rating: 0 | rate:
| |
|
Pop Piasa Send message Joined: 8 Aug 19 Posts: 252 Credit: 458,054,251 RAC: 0 Level Scientific publications | |
|
Robert, I had to adjust the slider to full power to get my GPUs to engage. It will take a while to catch some available work the first time as I recall. Once you have GPU tasks you can run at any speed. | |
| ID: 54721 | Rating: 0 | rate:
| |
|
robertmiles Send message Joined: 16 Apr 09 Posts: 503 Credit: 755,370,933 RAC: 212,472 Level Scientific publications | |
|
Pop Piasa, | |
| ID: 54724 | Rating: 0 | rate:
| |
|
ServicEnginIC Send message Joined: 24 Sep 10 Posts: 581 Credit: 9,770,362,024 RAC: 21,500,013 Level Scientific publications | |
|
Here we are again in the same situation: | |
| ID: 55133 | Rating: 0 | rate:
| |
|
Erich56 Send message Joined: 1 Jan 15 Posts: 1132 Credit: 10,205,482,676 RAC: 29,855,510 Level Scientific publications | |
What will come the next? maybe tasks related to Corona? | |
| ID: 55134 | Rating: 0 | rate:
| |
|
Jim1348 Send message Joined: 28 Jul 12 Posts: 819 Credit: 1,591,285,971 RAC: 0 Level Scientific publications | |
|
August is next. | |
| ID: 55135 | Rating: 0 | rate:
| |
|
ServicEnginIC Send message Joined: 24 Sep 10 Posts: 581 Credit: 9,770,362,024 RAC: 21,500,013 Level Scientific publications | |
maybe tasks related to Corona? 🤞️🤞️ | |
| ID: 55136 | Rating: 0 | rate:
| |
|
Jim1348 Send message Joined: 28 Jul 12 Posts: 819 Credit: 1,591,285,971 RAC: 0 Level Scientific publications | |
|
There are so many anti-virals and vaccines under testing now, and probably available in a few months, that any additional computer project would get lost in the noise. I think they are better in focusing on more general subject matter, where they can make a difference in the longer term. The databases or whatever it is that they are establishing look worthwhile to me. | |
| ID: 55137 | Rating: 0 | rate:
| |
|
ServicEnginIC Send message Joined: 24 Sep 10 Posts: 581 Credit: 9,770,362,024 RAC: 21,500,013 Level Scientific publications | |
|
About two days of tasks left to think about it... | |
| ID: 55138 | Rating: 0 | rate:
| |
|
robertmiles Send message Joined: 16 Apr 09 Posts: 503 Credit: 755,370,933 RAC: 212,472 Level Scientific publications | |
There are so many anti-virals and vaccines under testing now, and probably available in a few months, that any additional computer project would get lost in the noise. I think they are better in focusing on more general subject matter, where they can make a difference in the longer term. The databases or whatever it is that they are establishing look worthwhile to me. True for CPU workunits, but GPU workunits related to medical research are hard to find elsewhere. There appear to be none using BOINC. Folding@home and Quarantine@home have some non-BOINC GPU workunits, though. The ones at Quarantine@home are for Linux only. The OpenPandemics subproject at World Community Grid is looking into whether the right software is available to allow GPU workunits for them. If so, they may start while they are still working on COVID-19. | |
| ID: 55139 | Rating: 0 | rate:
| |
|
Jim1348 Send message Joined: 28 Jul 12 Posts: 819 Credit: 1,591,285,971 RAC: 0 Level Scientific publications | |
|
All true, but that is not the point. It is not what GPU work the projects can provide, but what we can do for the projects, and hence the science. Even if you handed them a new recipe to test now (there seem to be hundreds waiting in the wings to be tested), they could not do it for several more months. By then at least a first round of anti-virals will be ready, with the vaccines not far behind. | |
| ID: 55140 | Rating: 0 | rate:
| |
|
ServicEnginIC Send message Joined: 24 Sep 10 Posts: 581 Credit: 9,770,362,024 RAC: 21,500,013 Level Scientific publications | |
If repeating similar past behaviors, unsent tasks will start decreasing more quickly until they get exhausted. I love GPUGrid. It is a surprises box... Suddenly, behavior has given a quantum jump, and it somehow differs from precedents: Unsent tasks started to decrease more slowly today, in coincidence with receiving new tasks as: e1s241_17gen-PABLO_UCB_NMR_KIX_CMYB_8-0-5-RND1858_1 e1s321_villin_100ns_6-ADRIA_VillinAdaptive100ns-0-1-RND7450_0 1b5fC00_320_4-TONI_MDADpr4sb-0-10-RND9302_2 1ac5A00_320_0-TONI_MDADex7sa-0-50-RND9726_2 ... To be continued... (?) | |
| ID: 55143 | Rating: 0 | rate:
| |
|
robertmiles Send message Joined: 16 Apr 09 Posts: 503 Credit: 755,370,933 RAC: 212,472 Level Scientific publications | |
If repeating similar past behaviors, unsent tasks will start decreasing more quickly until they get exhausted. This suggests that the "new" tasks are really old tasks that required manual fixes to the input files before they could be sent again, and those manual fixes are getting harder and harder. | |
| ID: 55145 | Rating: 0 | rate:
| |
|
ServicEnginIC Send message Joined: 24 Sep 10 Posts: 581 Credit: 9,770,362,024 RAC: 21,500,013 Level Scientific publications | |
Suddenly, behavior has given a quantum jump, and it somehow differs from precedents:If repeating similar past behaviors, unsent tasks will start decreasing more quickly until they get exhausted.About two days of tasks left to think about it... Due to this fact, my current estimate for remaining unsent tasks has changed from a couple of days to more than a dozen. Thank you very much to all those goblins in the shadow... | |
| ID: 55147 | Rating: 0 | rate:
| |
|
ServicEnginIC Send message Joined: 24 Sep 10 Posts: 581 Credit: 9,770,362,024 RAC: 21,500,013 Level Scientific publications | |
|
At the present rate, I roughly estimate that current batch of TONI_MDAD available WUs will start to decrease at a significant higher rate at around next Sunday (January 3rd 2021) | |
| ID: 56155 | Rating: 0 | rate:
| |
|
rod4x4 Send message Joined: 4 Aug 14 Posts: 266 Credit: 2,219,935,054 RAC: 0 Level Scientific publications | |
At the present rate, I roughly estimate that current batch of TONI_MDAD available WUs will start to decrease at a significant higher rate at around next Sunday (January 3rd 2021) At current rate, your prediction from last year (27th dec) is looking pretty good! | |
| ID: 56220 | Rating: 0 | rate:
| |
|
Richard Haselgrove Send message Joined: 11 Jul 09 Posts: 1620 Credit: 8,822,866,430 RAC: 19,442,844 Level Scientific publications | |
|
All gone. We're down to the resends. | |
| ID: 56229 | Rating: 0 | rate:
| |
|
ServicEnginIC Send message Joined: 24 Sep 10 Posts: 581 Credit: 9,770,362,024 RAC: 21,500,013 Level Scientific publications | |
All gone. We're down to the resends. My backup GPU projects are waking up from their lethargy. In the interim, I'll be in the remote chance to discover a new prime number at PrimeGrid, or a new pulsar at Einstein@Home... ⏳️ | |
| ID: 56232 | Rating: 0 | rate:
| |
|
RJ The Bike Guy Send message Joined: 2 Apr 20 Posts: 20 Credit: 35,363,533 RAC: 0 Level Scientific publications | |
|
No more GPUGRID work? For how long? | |
| ID: 56233 | Rating: 0 | rate:
| |
|
Ian&Steve C. Send message Joined: 21 Feb 20 Posts: 1069 Credit: 40,231,533,983 RAC: 527 Level Scientific publications | |
|
No telling. Could be a couple days. Could be a couple weeks. Could be months. | |
| ID: 56234 | Rating: 0 | rate:
| |
|
Erich56 Send message Joined: 1 Jan 15 Posts: 1132 Credit: 10,205,482,676 RAC: 29,855,510 Level Scientific publications | |
No telling. Could be a couple days. Could be a couple weeks. Could be months. I don't understand why we are not given at least a rough idea of how long it could take :-( | |
| ID: 56235 | Rating: 0 | rate:
| |
|
zombie67 [MM]  Send message Joined: 16 Jul 07 Posts: 209 Credit: 4,095,161,456 RAC: 22,338,324 Level Scientific publications | |
|
https://www.dictionary.com/e/slang/take-for-granted/ WHAT DOES TAKE FOR GRANTED MEAN? ____________ Reno, NV Team: SETI.USA | |
| ID: 56236 | Rating: 0 | rate:
| |

Message boards : Number crunching : Unsent tasks decreasing much more slowly