Message boards : News : acemdbeta application - discussion
| Author | Message |
|---|---|
 MJH MJHProject administrator Project developer Project scientist Send message Joined: 12 Nov 07 Posts: 696 Credit: 27,266,655 RAC: 0 Level Scientific publications | |
|
The Beta application may be somewhat volatile for the next few days, as we try to understand and fix the remaining common failure modes. This will ultimately lead to a more stable production application, so please do continue to take WUs from there. Your help's appreciated. | |
| ID: 32645 | Rating: 0 | rate:
| |
|
Bedrich Hajek Send message Joined: 28 Mar 09 Posts: 486 Credit: 11,351,780,632 RAC: 9,362,860 Level Scientific publications | |
|
These new betas did reduce the speed of the 690 video cards, on my windows 7 computer from 1097 Mhz to 914 Mhz when they were running on that GPU. If I had a non beta running along side the beta on another GPU, the non beta was running at the higher speed. When the beta finished, and a non beta started running on that GPU the speed returned to 1097 Mhz. This did not happened on windows xp, with the 690 video card. The driver on the windows 7 computer is the beta 326.80, with EVGA precision x 4.0, while the windows xp computer is running 314.22, with EVGA precision x 4.0. | |
| ID: 32652 | Rating: 0 | rate:
| |
|
juan BFP Send message Joined: 11 Dec 11 Posts: 21 Credit: 145,887,858 RAC: 0 Level Scientific publications | |
|
How do we make to get the beta apps? I did´t receive anyone. My seetings: | |
| ID: 32653 | Rating: 0 | rate:
| |
|
zombie67 [MM]  Send message Joined: 16 Jul 07 Posts: 209 Credit: 4,110,911,456 RAC: 2,681,116 Level Scientific publications | |
How do we make to get the beta apps? I did´t receive anyone. My seetings: Also select "Run test applications?" ____________ Reno, NV Team: SETI.USA | |
| ID: 32654 | Rating: 0 | rate:
| |
|
I hope my massive quantity of failed beta wus is helping ;) | |
| ID: 32655 | Rating: 0 | rate:
| |
|
juan BFP Send message Joined: 11 Dec 11 Posts: 21 Credit: 145,887,858 RAC: 0 Level Scientific publications | |
How do we make to get the beta apps? I did´t receive anyone. My seetings: OK i select it now. May i ask something else, i see a lot of beta WU with running times of about 60sec who paid 1500 credits. That´s right? Normaly the WU takes a long time to crunch here. All my GPU´s are Cuda55 capable, did i need to do change something else in the settings? Thanks for the help ____________  | |
| ID: 32657 | Rating: 0 | rate:
| |
|
MJH Project administrator Project developer Project scientist Send message Joined: 12 Nov 07 Posts: 696 Credit: 27,266,655 RAC: 0 Level Scientific publications | |
5pot - that's exactly the problem that I am trying to fix. Your machine seems one of the worst affected. Could you PM more details about its setup please? In particular if you have any AV or GPU-related utilities installed. MJH | |
| ID: 32660 | Rating: 0 | rate:
| |
|
skgiven Volunteer moderator Volunteer tester  Send message Joined: 23 Apr 09 Posts: 3968 Credit: 1,995,359,260 RAC: 0 Level Scientific publications | |
|
# GPU 0 Current Temp: 66 C Target Temp 1 | |
| ID: 32661 | Rating: 0 | rate:
| |
|
I got 3 beta's ACEMD v 8.07 overnight and all failed. I got 3 short ones with v 8.09 that ran longer. And now I have a NOELIA_KLEBEbeta-2-3 running v 8.09 and has done 76% in 16h32m on my 660. This is way longer than on version 8.00 to 8.04. | |
| ID: 32662 | Rating: 0 | rate:
| |
|
Carlos Augusto Engel Send message Joined: 5 Jun 09 Posts: 38 Credit: 2,880,758,878 RAC: 0 Level Scientific publications | |
May i ask something else, i see a lot of beta WU with running times of about 60sec who paid 1500 credits. That´s right? Normaly the WU takes a long time to crunch here. That is ok. I received a lot of small ones too: 7242845 4748357 3 Sep 2013 | 4:51:19 UTC 3 Sep 2013 | 9:11:28 UTC Completo e validado 14,906.95 7,437.96 15,000.00 ACEMD beta version v8.10 (cuda55) 7242760 4748284 3 Sep 2013 | 4:35:37 UTC 3 Sep 2013 | 4:48:40 UTC Completo e validado 152.31 76.89 1,500.00 ACEMD beta version v8.10 (cuda55) 7242759 4748283 3 Sep 2013 | 4:35:37 UTC 3 Sep 2013 | 4:42:40 UTC Completo e validado 152.00 74.30 1,500.00 ACEMD beta version v8.10 (cuda55) 7242751 4748277 3 Sep 2013 | 4:35:37 UTC 3 Sep 2013 | 4:51:19 UTC Completo e validado 151.85 74.69 1,500.00 ACEMD beta version v8.10 (cuda55) ____________ | |
| ID: 32664 | Rating: 0 | rate:
| |
|
juan BFP Send message Joined: 11 Dec 11 Posts: 21 Credit: 145,887,858 RAC: 0 Level Scientific publications | |
|
But that kind of WU produces a lot of: | |
| ID: 32665 | Rating: 0 | rate:
| |
|
Richard Haselgrove Send message Joined: 11 Jul 09 Posts: 1626 Credit: 9,295,466,723 RAC: 18,414,230 Level Scientific publications | |
But that kind of WU produces a lot of: Number crunching knows. | |
| ID: 32666 | Rating: 0 | rate:
| |
|
juan BFP Send message Joined: 11 Dec 11 Posts: 21 Credit: 145,887,858 RAC: 0 Level Scientific publications | |
But that kind of WU produces a lot of: Thanks for the info, but edit client_state.xml is a dangerous territory, at least for me, i wait for the fix. ____________ | |
| ID: 32667 | Rating: 0 | rate:
| |
|
Bedrich Hajek Send message Joined: 28 Mar 09 Posts: 486 Credit: 11,351,780,632 RAC: 9,362,860 Level Scientific publications | |
|
On my computers, the beta versions 8.05 to 8.10 are significantly slower than version 8.04. The MJHARVEY_TEST14, for example ran about 70 seconds with version 8.04, but takes about 4 minutes to complete on versions 8.05 through 8.10. I ran NOELIA_KLEBEbeta WU's in 10 to 12 hours on version 8.04, while currently I am running 4 of these NOELIA unit on versions 8.05 and 8.10, and it looks like they will finish in about 16 to 20 hours. These results are typical for windows 7 and xp, cuda 4.2 and 5.5, Nvidia drivers 314.22 and 326.80. Windows 7 down clocks, but xp doesn't is the only difference. Please don't cancel the units, they seem to be running okay, and I want to finish them to proof that point. I hope the next beta version is faster and better. | |
| ID: 32668 | Rating: 0 | rate:
| |
|
skgiven Volunteer moderator Volunteer tester Send message Joined: 23 Apr 09 Posts: 3968 Credit: 1,995,359,260 RAC: 0 Level Scientific publications | |
|
Had another Blue Screen crash! | |
| ID: 32675 | Rating: 0 | rate:
| |
|
Jacob Klein Send message Joined: 11 Oct 08 Posts: 1127 Credit: 1,901,927,545 RAC: 0 Level Scientific publications | |
|
Oh man, skgiven! You lost 330 hours of work? That's very unfortunate. | |
| ID: 32680 | Rating: 0 | rate:
| |
|
skgiven Volunteer moderator Volunteer tester Send message Joined: 23 Apr 09 Posts: 3968 Credit: 1,995,359,260 RAC: 0 Level Scientific publications | |
|
It's not the first time, or the second - Maybe I'll never learn! | |
| ID: 32686 | Rating: 0 | rate:
| |
|
MJH Project administrator Project developer Project scientist Send message Joined: 12 Nov 07 Posts: 696 Credit: 27,266,655 RAC: 0 Level Scientific publications | |
Highly surprising that the driver reset would cause two non-GPU-using apps (I repsume) to crash. Were their graphical screen-savers enabled? Sure the BOINC client didn't get confused and terminate them? MJH | |
| ID: 32690 | Rating: 0 | rate:
| |
|
MJH Project administrator Project developer Project scientist Send message Joined: 12 Nov 07 Posts: 696 Credit: 27,266,655 RAC: 0 Level Scientific publications | |
8.11 (now on beta and short) represents the best that can be done using that method. MJH | |
| ID: 32691 | Rating: 0 | rate:
| |
|
Jacob Klein Send message Joined: 11 Oct 08 Posts: 1127 Credit: 1,901,927,545 RAC: 0 Level Scientific publications | |
|
Note: A Blue-Screen is worse than a driver reset. And I have sometimes seen GPUGrid tasks, when being suspended (looking at the NOELIA ones again)... give me blue screens in the past, with error DPC_WATCHDOG_VIOLATION.
| |
| ID: 32696 | Rating: 0 | rate:
| |
|
MJH Project administrator Project developer Project scientist Send message Joined: 12 Nov 07 Posts: 696 Credit: 27,266,655 RAC: 0 Level Scientific publications | |
Yes - I read "blue-screen" but heard "driver reset". BSOD's are by definition a driver bug. It's axiomatic that no user program should be able to crash the kernel. "DPC_WATCHDOG_VIOLATION" is the event that the driver is supposed to trap and recover from, triggering a driver reset. Evidently that's not a perfect process. MJH | |
| ID: 32697 | Rating: 0 | rate:
| |
|
Jacob Klein Send message Joined: 11 Oct 08 Posts: 1127 Credit: 1,901,927,545 RAC: 0 Level Scientific publications | |
|
I think if a driver encounters too many TDRs in a short period of time, the OS issues the DPC_WATCHDOG_VIOLATION BSOD. | |
| ID: 32699 | Rating: 0 | rate:
| |
Stoneageman  Send message Joined: 25 May 09 Posts: 224 Credit: 34,057,374,498 RAC: 17 Level Scientific publications | |
|
5/5, 8.11-Noelia beta wu's failed on time exceeded.Sample | |
| ID: 32707 | Rating: 0 | rate:
| |
|
MJH Project administrator Project developer Project scientist Send message Joined: 12 Nov 07 Posts: 696 Credit: 27,266,655 RAC: 0 Level Scientific publications | |
|
Just killing off the remaining beta WUs now. | |
| ID: 32709 | Rating: 0 | rate:
| |
|
Retvari Zoltan Send message Joined: 20 Jan 09 Posts: 2353 Credit: 16,375,531,916 RAC: 5,811,976 Level Scientific publications | |
Just killing off the remaining beta WUs now. I had a beta WU from the TEST18 series, and my host reported it successfully, and it didn't received an abort request from the GPUGrid scheduler. Is there anything we should do? (for example manually abort all beta tasks, including NOELIA_KLEBEbeta tasks?) | |
| ID: 32716 | Rating: 0 | rate:
| |
|
Bedrich Hajek Send message Joined: 28 Mar 09 Posts: 486 Credit: 11,351,780,632 RAC: 9,362,860 Level Scientific publications | |
|
I guess we did enough testing for now, and we can forgot beta versions 8.05 to 8.10. Here is the proof. Look at the finishing times. | |
| ID: 32718 | Rating: 0 | rate:
| |
|
MJH Project administrator Project developer Project scientist Send message Joined: 12 Nov 07 Posts: 696 Credit: 27,266,655 RAC: 0 Level Scientific publications | |
|
The "simulation unstable" (err -97) failure mode can be quite painful in terms of lost credit. In some circumstances this can be recoverable error, so aborting the WU is unnecessarily wasteful. | |
| ID: 32722 | Rating: 0 | rate:
| |
|
juan BFP Send message Joined: 11 Dec 11 Posts: 21 Credit: 145,887,858 RAC: 0 Level Scientific publications | |
|
Sorry if i put this on the wrong thread. | |
| ID: 32724 | Rating: 0 | rate:
| |
|
Retvari Zoltan Send message Joined: 20 Jan 09 Posts: 2353 Credit: 16,375,531,916 RAC: 5,811,976 Level Scientific publications | |
Could be just curiosity but somebody could explain why this WU receives such diferences in credits, if they uses about the same GPU/CPU times on similar hosts and are from the same kind of WU (NOELIA) These workunits are from the same scientist (Noelia), but they are not in the same batch. The first workunit is a NOELIA_FRAG041p. The second workunit is a NOELIA_INS1P. | |
| ID: 32725 | Rating: 0 | rate:
| |
|
juan BFP Send message Joined: 11 Dec 11 Posts: 21 Credit: 145,887,858 RAC: 0 Level Scientific publications | |
Could be just curiosity but somebody could explain why this WU receives such diferences in credits, if they uses about the same GPU/CPU times on similar hosts and are from the same kind of WU (NOELIA) By that i understand, the credit "paid" is not related to the processing power used to crunch the WU is related to the batch of the WU when somebody decides the number of credit paid by the batch WU´s, that´s diferent from most of the other Boinc projects and why that´s bugs my mind. Initialy i expect the same number of credits for the same processing time used on the same host (or something aproximately). Please understand me, i don´t question the metodoth i just want to find the answer why. That´s ok now. Thanks for the answer and happy crunching. ____________ | |
| ID: 32726 | Rating: 0 | rate:
| |
|
Retvari Zoltan Send message Joined: 20 Jan 09 Posts: 2353 Credit: 16,375,531,916 RAC: 5,811,976 Level Scientific publications | |
By that i understand, the credit "paid" is not related to the processing power used to crunch the WU is related to the batch of the WU when somebody decides the number of credit paid by the batch WU´s, that´s diferent from most of the other Boinc projects and why that´s bugs my mind. Initialy i expect the same number of credits for the same processing time used on the same host (or something aproximately). For the second time I've read your previous post it came to my mind that your problem could be that a shorter WU received more credit than a longer WU. Well, that's a paradox. It happens from time to time. Later on you will get used to it. It's probably caused by the method used for approximating the processing power needed for the given WU (based on the complexity of the model, and the steps needed). The shorter (~30ksec) WU had 6.25 million steps, and received 180k credit. (6 credit/sec) The longer (~31.4ksec) WU had 4.2 million steps, and received 148.5k credit. (4.73 credit/sec) There is 27% difference between the credit/sec rate of the two workunits. It's significant, but not unusual. | |
| ID: 32727 | Rating: 0 | rate:
| |
|
juan BFP Send message Joined: 11 Dec 11 Posts: 21 Credit: 145,887,858 RAC: 0 Level Scientific publications | |
For the second time I've read your previous post it came to my mind that your problem could be that a shorter WU received more credit than a longer WU. Well, that's a paradox......It's significant, but not unusual. That´s exactly what i means, the paradox (less time more credit - more time less credit). But if is normal and not a bug... then Go crunching both. Thanks for your time and explanations. ____________ | |
| ID: 32728 | Rating: 0 | rate:
| |
|
MJH Project administrator Project developer Project scientist Send message Joined: 12 Nov 07 Posts: 696 Credit: 27,266,655 RAC: 0 Level Scientific publications | |
|
Ok chaps, there's a new beta 8.12. | |
| ID: 32729 | Rating: 0 | rate:
| |
|
Richard Haselgrove Send message Joined: 11 Jul 09 Posts: 1626 Credit: 9,295,466,723 RAC: 18,414,230 Level Scientific publications | |
I have had to update the BOINC client library to implement this, so expect everything to go hilariously wrong. ROFL - now that's a good way to attract testers! We have been duly warned, and I'm off to try and download some now. I've seen a few exits with 'error -97', but not any great number. If I get any CRASH1 tasks now, they will run on device 0 - the hotter of my two GTX 670s - hopefully that will generate some material for you to work with. | |
| ID: 32730 | Rating: 0 | rate:
| |
|
Jacob Klein Send message Joined: 11 Oct 08 Posts: 1127 Credit: 1,901,927,545 RAC: 0 Level Scientific publications | |
|
I grabbed 4 of them too. It'll be a couple hours before my 2 GPUs can begin work on them. | |
| ID: 32731 | Rating: 0 | rate:
| |
|
Richard Haselgrove Send message Joined: 11 Jul 09 Posts: 1626 Credit: 9,295,466,723 RAC: 18,414,230 Level Scientific publications | |
|
I hadn't reset my DCF, so I only got one job, and it started immediately in high priority - task 7250880. Initial indications are that it will run for roughly 2 hours, if it doesn't spend too much time rewinding. | |
| ID: 32732 | Rating: 0 | rate:
| |
|
MJH Project administrator Project developer Project scientist Send message Joined: 12 Nov 07 Posts: 696 Credit: 27,266,655 RAC: 0 Level Scientific publications | |
|
The next version will emit temperatures only when they change. | |
| ID: 32733 | Rating: 0 | rate:
| |
|
Jacob Klein Send message Joined: 11 Oct 08 Posts: 1127 Credit: 1,901,927,545 RAC: 0 Level Scientific publications | |
|
Just to clarify... Most of my GPUGrid tasks get "started" about 5-10 times, as I'm suspending the GPU often (for exclusive apps), and restarting the machine often (troubleshooting nVidia driver problems). | |
| ID: 32734 | Rating: 0 | rate:
| |
|
MJH Project administrator Project developer Project scientist Send message Joined: 12 Nov 07 Posts: 696 Credit: 27,266,655 RAC: 0 Level Scientific publications | |
|
8.13: reduce temperature verbosity and trap access violations and recover. | |
| ID: 32736 | Rating: 0 | rate:
| |
|
Richard Haselgrove Send message Joined: 11 Jul 09 Posts: 1626 Credit: 9,295,466,723 RAC: 18,414,230 Level Scientific publications | |
task 7250880. I think we got what you were hoping for: # The simulation has become unstable. Terminating to avoid lock-up (1) Edit - on the other hand, task 7250828 wasn't so lucky. And I can't see any special messages in the BOINC event log either: these are all ones I would have expected to see anyway. 05/09/2013 18:52:21 | GPUGRID | Finished download of 147-MJHARVEY_CRASH1-0-xsc_file | |
| ID: 32738 | Rating: 0 | rate:
| |
|
MJH Project administrator Project developer Project scientist Send message Joined: 12 Nov 07 Posts: 696 Credit: 27,266,655 RAC: 0 Level Scientific publications | |
|
Grand. Worked as designed in both cases - in the first it was able to restart and continue, in the second the restart lead to immediate failure, so it corrected aborted, rather than getting stuck in a loop. | |
| ID: 32739 | Rating: 0 | rate:
| |
|
ExtraTerrestrial Apes Volunteer moderator Volunteer tester Send message Joined: 17 Aug 08 Posts: 2705 Credit: 1,311,122,549 RAC: 0 Level Scientific publications | |
|
That's some really nice progress! | |
| ID: 32740 | Rating: 0 | rate:
| |
|
Jacob Klein Send message Joined: 11 Oct 08 Posts: 1127 Credit: 1,901,927,545 RAC: 0 Level Scientific publications | |
|
Right -- I think this begs the question: Is it normal or possible for the program to become unstable due to a problem in the program? ie: If the hardware isn't overclocked and is calculating perfectly, is it normal or possible to encounter a recoverable program instability? | |
| ID: 32741 | Rating: 0 | rate:
| |
|
Richard Haselgrove Send message Joined: 11 Jul 09 Posts: 1626 Credit: 9,295,466,723 RAC: 18,414,230 Level Scientific publications | |
8.13: reduce temperature verbosity and trap access violations and recover. First v8.13 returned - task 7250857 Stderr compact enough to fit inside the 64KB limit, but no restart event to bulk it up. I note the workunits still have the old 5 PetaFpop estimate: <name>147-MJHARVEY_CRASH1-0-25-RND2539</name> <app_name>acemdbeta</app_name> <version_num>813</version_num> <rsc_fpops_est>5000000000000000.000000</rsc_fpops_est> <rsc_fpops_bound>250000000000000000.000000</rsc_fpops_bound> That has led to an APR of 546 for host 132158. That's not a problem, while the jobs are relatively long (nearer 2.5 hours than my initial guess of 2 hours) - that APR is high, but nowhere near high enough to cause any problems, so no immediate remedial action is needed. But it would be good to get into the habit of dialling it down as a matter of routine. | |
| ID: 32742 | Rating: 0 | rate:
| |
|
MJH Project administrator Project developer Project scientist Send message Joined: 12 Nov 07 Posts: 696 Credit: 27,266,655 RAC: 0 Level Scientific publications | |
This fix addresses two specific failure modes - 1) an access violation and 2) transient instability of the simulation. As you know, the application regularly checkpoints so that it can resume if suspended. We use that mechanism to simply restart the simulation at the last known good point when failure occurs. (If no checkpoint state exists, or itself is corrupted, the WU will be aborted as before). What we are not doing is ignoring the error and ploughing on regardless (which wouldn't be possible anyway, because the sim is dead by that point). Because of the nature of our simulations and analytical methods, we can treat any transient error that perturbs but does not kill the simulation as an ordinary source of random experimental error. Concerning the problems themselves: the first is not so important in absolute terms, only a few users are affected by it (though those that are suffer repeatedly), but the workaround is similar to that for 2) so it was no effort to include a fix for it also. This problem is almost certainly some peculiarity of their systems, whether interaction with some other running software, specific version of some DLLs, or colour of gonk sat on top of the monitor. The second problem is our current major failure modem largely because it is effectively a catch-all for problems that interfered somehow with the correct operation of the GPU, but which did not kill the application process outright. When this type of error occurs on reliable computers of known quality and configuration I know that it strongly indicates either hardware or driver problems (and the boundary between those two blurs at times). In GPUGRID, where every client is unique, root-causing these failures is exceedingly difficult and can only really be approached statistically.[1] The problem is compounded by having an app that really exercises the whole system (not just CPU, but GPU, PCIe and al whole heap of OS drivers). The opportunity for unexpected and unfavourable interactions with other system activities is increased, and tractability of debugging decreased. To summarise -my goal here is not to eliminate WU errors entirely (which is practically impossible), but to 1) mitigate them to a sufficiently low level that they do not impede our use of GPUGRID (or, put another way, maximise the effective throughput of an inherently unreliable system) 2) minimise the amount of wastage of your volunteered resources, in terms of lost contribution from failed partially-complete WUs Hope that explains the situation. MJH [1] For a great example of this, see how Microsoft manages WER bug reports. http://research.microsoft.com/pubs/81176/sosp153-glerum-web.pdf | |
| ID: 32744 | Rating: 0 | rate:
| |
|
Retvari Zoltan Send message Joined: 20 Jan 09 Posts: 2353 Credit: 16,375,531,916 RAC: 5,811,976 Level Scientific publications | |
To summarise -my goal here is not to eliminate WU errors entirely (which is practically impossible), but to These are really nice goals, which meet all crunchers' expectations (or dreams if you like). I have two down-to-earth suggestions to help you achieve your goals: 1. for the server side: do not send long workunits to unreliable, or slow hosts 2. for the client side: now that you can monitor the GPU temperature, you should throttle the client if the GPU it's running on became too hot (for example above 80°C, and a warning should be present in the stderr.out) | |
| ID: 32758 | Rating: 0 | rate:
| |
|
juan BFP Send message Joined: 11 Dec 11 Posts: 21 Credit: 145,887,858 RAC: 0 Level Scientific publications | |
|
I don´t know if that is what you look for, i was forced to abort this WU after > 10 hr of crunching and only 35% done (normal WU crunching total time of 8-9 hrs) | |
| ID: 32764 | Rating: 0 | rate:
| |
|
skgiven Volunteer moderator Volunteer tester Send message Joined: 23 Apr 09 Posts: 3968 Credit: 1,995,359,260 RAC: 0 Level Scientific publications | |
for the server side: do not send long workunits to unreliable, or slow hosts Indeed this would be of great benefit to the researchers and entry level crunchers alike, A GT620 isn't fast enough to crunch Long WU's, so ideally it wouldn't be offered any. Even if there is no other work, there would still be no point in sending Long work to a GF 605, GT610, GT620, GT625... For example, http://www.gpugrid.net/forum_thread.php?id=3463&nowrap=true#32750 Perhaps this could be done most easily based on the GFLOPS? If so I suggest a cutoff point of 595, as this would still allow the GTS 450, GTX 550 Ti, GTX 560M, GT640, and GT 745M to run long WU's, should people chose to (especially via 'If no work for selected applications is available, accept work from other applications?'). You might want to note that some of the smaller cards have seriously low bandwidth, so maybe that should be factored in too. Is the app able to detect a downclock (say from 656MHz to 402MHz on a GF400)? If so could a message be sent to the user either through Boinc or email alerting the user of the downclock. Ditto, if as Zoltan suggested, the temp goes over say 80°C, so the user can increase their fan speeds (or clean the dust out)? I like pro-active. ____________ FAQ's HOW TO: - Opt out of Beta Tests - Ask for Help | |
| ID: 32768 | Rating: 0 | rate:
| |
8.13: reduce temperature verbosity and trap access violations and recover. Hi Matt, My 770 had a MJHARVEY_CRACH ACEMD beta 8.13 overnight. When I looked this morning it had done little more than 96% but it was not running anymore. I saw that as I monitor the GPU behavior and the temp. was lower, the fan was lower and GPU use was zero. I wait about 10 minutes to see if it recovered, but no. So I suspended it, another one started. I suspended that one and resume the one that stood still. It finished okay. In the log afterwards it is shown that it was re-started, (a second block with info about the card) but no line in the output that I suspend/resumed it, and no reason why it stopped running. Here it is. As you can see no error message. Edit: I don´t know how low it stopped running, but the time between sent and received is quite long. Run time and CPU time is almost the same. I have put a line in cc-config to report finished WU´s immediately (especially for Rosetta). ____________ Greetings from TJ | |
| ID: 32769 | Rating: 0 | rate:
| |
|
Bedrich Hajek Send message Joined: 28 Mar 09 Posts: 486 Credit: 11,351,780,632 RAC: 9,362,860 Level Scientific publications | |
|
My windows 7 computer was running 4 of these MJHARVEY_CRASH beta units on 2 690 video cards. Boinc manager decided to run a benchmark. When the units resumed, their status was listed as running, but they were not running, (no progress was being made, the video card were cooling off, and not running anything). I had to suspend all the units and restart them one by one in order to get them going. They all finished successfully. | |
| ID: 32772 | Rating: 0 | rate:
| |
|
skgiven Volunteer moderator Volunteer tester Send message Joined: 23 Apr 09 Posts: 3968 Credit: 1,995,359,260 RAC: 0 Level Scientific publications | |
|
MJHARVEY_CRASH2 WU's are saying they have a Virtual memory size of 16.22GB on Linux, but on Windows it's 253MB. | |
| ID: 32773 | Rating: 0 | rate:
| |
|
MJH Project administrator Project developer Project scientist Send message Joined: 12 Nov 07 Posts: 696 Credit: 27,266,655 RAC: 0 Level Scientific publications | |
That's normal, and nothing to worry about. Matt | |
| ID: 32774 | Rating: 0 | rate:
| |
|
MJH Project administrator Project developer Project scientist Send message Joined: 12 Nov 07 Posts: 696 Credit: 27,266,655 RAC: 0 Level Scientific publications | |
Understanding the crazy in the server is also on the Todo list. MJH | |
| ID: 32775 | Rating: 0 | rate:
| |
|
Thanks for your post Bedrich. | |
| ID: 32776 | Rating: 0 | rate:
| |
|
MJH Project administrator Project developer Project scientist Send message Joined: 12 Nov 07 Posts: 696 Credit: 27,266,655 RAC: 0 Level Scientific publications | |
Sounds like a BOINC client problem. Why is it running benchmarks? does't it only do that the once? MJH | |
| ID: 32777 | Rating: 0 | rate:
| |
yes indeed it does when BOINC starts but also once in a while. When a system runs 24/7 than it will do it "regularly" it suspends all work and then resumes again. But that didn´t work with MJHARVEY_CRASH. So every rig that runs24/7/365 will have this issue now, wan´t before 8.13. ____________ Greetings from TJ | |
| ID: 32778 | Rating: 0 | rate:
| |
|
MJH Project administrator Project developer Project scientist Send message Joined: 12 Nov 07 Posts: 696 Credit: 27,266,655 RAC: 0 Level Scientific publications | |
|
After the benchmark, exactly what was the state of the machine? | |
| ID: 32780 | Rating: 0 | rate:
| |
|
Jacob Klein Send message Joined: 11 Oct 08 Posts: 1127 Credit: 1,901,927,545 RAC: 0 Level Scientific publications | |
|
I just did it as a test (it's very easy to manually run benchmarks you know, just click Advanced -> Run CPU benchmarks!) | |
| ID: 32786 | Rating: 0 | rate:
| |
|
My Pc crash and reboot. | |
| ID: 32787 | Rating: 0 | rate:
| |
|
Richard Haselgrove Send message Joined: 11 Jul 09 Posts: 1626 Credit: 9,295,466,723 RAC: 18,414,230 Level Scientific publications | |
|
Benchmarks can be invoked at any time for testing - they are listed as 'Run CPU benchmarks' on the Advanced menu. | |
| ID: 32788 | Rating: 0 | rate:
| |
|
MJH Project administrator Project developer Project scientist Send message Joined: 12 Nov 07 Posts: 696 Credit: 27,266,655 RAC: 0 Level Scientific publications | |
|
Thanks Richard, | |
| ID: 32790 | Rating: 0 | rate:
| |
|
It was as Jacob explained in post 32786. No error message and not stopping the ACEMD app. BOINC manager said running and the time kept ticking, but no progress. Seems to be almost 2 hours in that state in my case. | |
| ID: 32791 | Rating: 0 | rate:
| |
|
Richard Haselgrove Send message Joined: 11 Jul 09 Posts: 1626 Credit: 9,295,466,723 RAC: 18,414,230 Level Scientific publications | |
|
My most recent one (task 7253807) shows a crash and recovery from a SWAN : FATAL : Cuda driver error 999 in file 'swanlibnv2.cpp' in line 1963. # SWAN swan_assert 0 which is pretty impressive. In case you're puzzled by the high frequency of restarts at the beginning of the task: at the moment, I'm restricting BOINC to running only one GPUGrid task at a time ('<max_concurrent>'). If the running task suffers a failure, the next in line gets called forward, and runs for a few seconds. But when the original task is ready to resume, 'high priority' (EDF) forces it to run immediately, and the second task to be swapped out. So, a rather stuttering start, but not the fault of the application. The previous task (7253208) shows a number of # The simulation has become unstable. Terminating to avoid lock-up (1) which account for the false starts. | |
| ID: 32799 | Rating: 0 | rate:
| |
|
Jacob Klein Send message Joined: 11 Oct 08 Posts: 1127 Credit: 1,901,927,545 RAC: 0 Level Scientific publications | |
|
The 8.13 app is still spitting out too much temperature data. | |
| ID: 32800 | Rating: 0 | rate:
| |
|
MJH Project administrator Project developer Project scientist Send message Joined: 12 Nov 07 Posts: 696 Credit: 27,266,655 RAC: 0 Level Scientific publications | |
|
New beta 8.14. Suspend and resume, of either favour, should now be working without problems. | |
| ID: 32801 | Rating: 0 | rate:
| |
|
MJH Project administrator Project developer Project scientist Send message Joined: 12 Nov 07 Posts: 696 Credit: 27,266,655 RAC: 0 Level Scientific publications | |
Only maxima printed now | |
| ID: 32802 | Rating: 0 | rate:
| |
|
Jacob Klein Send message Joined: 11 Oct 08 Posts: 1127 Credit: 1,901,927,545 RAC: 0 Level Scientific publications | |
|
8.14 appears to be resuming appropriately from running CPU benchmarks. # BOINC suspending at user request (thread suspend) # BOINC resuming at user request (thread suspend) # BOINC suspending at user request (exit) Great job! I also see you've done some work to condense the temp readings. Thanks for that.
If that means "Only printing a temperature reading if it has increased since the start of the run", then that is a GREAT compromise. Do you think you need them for all GPUs? Or could you maybe just limit to the running GPU? # GPU [GeForce GTX 460] Platform [Windows] Rev [3203] VERSION [55] # SWAN Device 1 : # Name : GeForce GTX 460 # ECC : Disabled # Global mem : 1024MB # Capability : 2.1 # PCI ID : 0000:08:00.0 # Device clock : 1526MHz # Memory clock : 1900MHz # Memory width : 256bit # Driver version : r325_00 : 32680 # GPU 0 : 67C # GPU 1 : 66C # GPU 2 : 76C # GPU 1 : 67C # GPU 2 : 77C | |
| ID: 32803 | Rating: 0 | rate:
| |
|
MJH Project administrator Project developer Project scientist Send message Joined: 12 Nov 07 Posts: 696 Credit: 27,266,655 RAC: 0 Level Scientific publications | |
The GPU numbering doesn't necessarily correspond to that that the rest of the app uses, so I'm going to leave them all in. MJH | |
| ID: 32804 | Rating: 0 | rate:
| |
|
Jacob Klein Send message Joined: 11 Oct 08 Posts: 1127 Credit: 1,901,927,545 RAC: 0 Level Scientific publications | |
|
Thanks Matt. | |
| ID: 32806 | Rating: 0 | rate:
| |
|
Despite units GPUGRID test "Crash" my machine continues to produce blue screens and reboot, I need to work with, I am forced to stop GPUGRID and replace by Seti Beta. | |
| ID: 32807 | Rating: 0 | rate:
| |
|
MJH Project administrator Project developer Project scientist Send message Joined: 12 Nov 07 Posts: 696 Credit: 27,266,655 RAC: 0 Level Scientific publications | |
|
Zarck, hello! Don't give up now - I've been watching your tasks and 8.13 has a fix especially for you! | |
| ID: 32808 | Rating: 0 | rate:
| |
|
MJH Project administrator Project developer Project scientist Send message Joined: 12 Nov 07 Posts: 696 Credit: 27,266,655 RAC: 0 Level Scientific publications | |
|
Ok folks - last call for feature/mod requests for the beta. | |
| ID: 32810 | Rating: 0 | rate:
| |
|
skgiven Volunteer moderator Volunteer tester Send message Joined: 23 Apr 09 Posts: 3968 Credit: 1,995,359,260 RAC: 0 Level Scientific publications | |
|
Performed a CPU Benchmark (with LAIM off). The WU running on the 8.13 app stopped and didn't resume, but the WU on the 8.14 app resumed normally (also with LAIM on). | |
| ID: 32811 | Rating: 0 | rate:
| |
|
Jim1348 Send message Joined: 28 Jul 12 Posts: 819 Credit: 1,591,285,971 RAC: 0 Level Scientific publications | |
Ok folks - last call for feature/mod requests for the beta. Since you asked. There have been a number of comments about monitoring temperature, which is good. But I have found that cards can crash due to overclocking while still running relatively cool (less than 70C for example). I don't know if BOINC allows you to monitor the actual GPU core speed, but if so that would be worthwhile to report in some form. I don't know that it is high priority for this beta, but maybe the next one. | |
| ID: 32812 | Rating: 0 | rate:
| |
|
MJH Project administrator Project developer Project scientist Send message Joined: 12 Nov 07 Posts: 696 Credit: 27,266,655 RAC: 0 Level Scientific publications | |
Unsurprising - it's an inevitable consequence of the way the BOINC client library (which we build into our application) goes about doing suspend -resume[1] I've re-plumbed the whole thing entirely, using a much more reliable method. MJH [1] To paraphrase the old saying - 'Some people, when confronted with a problem, think "I'll uses threads". Now they have two problems'. | |
| ID: 32813 | Rating: 0 | rate:
| |
|
Jacob Klein Send message Joined: 11 Oct 08 Posts: 1127 Credit: 1,901,927,545 RAC: 0 Level Scientific publications | |
Ok folks - last call for feature/mod requests for the beta. Can you make it print an ascii rainbow at the end of a successful task? Seriously, though, can't think of much, except maybe - Format the driver version to say 326.80 instead of 32680 - Add a timestamp with every start/restart block | |
| ID: 32814 | Rating: 0 | rate:
| |
|
MJH Project administrator Project developer Project scientist Send message Joined: 12 Nov 07 Posts: 696 Credit: 27,266,655 RAC: 0 Level Scientific publications | |
|
There's a new batch of Beta WUs - "MJHARVEY-CRASHNPT". These test an important feature of the application that we've not been able to use much in the past because it seemed to be contributing towards crashes. The last series of CRASH units has given me good stats on the underlying error rates for control, so this batch should reveal whether there is in fact a bug with the feature. | |
| ID: 32875 | Rating: 0 | rate:
| |
|
Richard Haselgrove Send message Joined: 11 Jul 09 Posts: 1626 Credit: 9,295,466,723 RAC: 18,414,230 Level Scientific publications | |
|
First NPT processed with no errors at all - task 7269244. If I get any more, I'll try running them on the 'hot' GPU. | |
| ID: 32887 | Rating: 0 | rate:
| |
|
Jacob Klein Send message Joined: 11 Oct 08 Posts: 1127 Credit: 1,901,927,545 RAC: 0 Level Scientific publications | |
|
I have not had any problems processing the "MJHARVEY-CRASHNPT" units on my stable machine that runs GPUGrid on my GTX 660 Ti and GTX 460. | |
| ID: 32947 | Rating: 0 | rate:
| |
|
Carlesa25 Send message Joined: 13 Nov 10 Posts: 328 Credit: 72,619,453 RAC: 0 Level Scientific publications | |
|
Hello: You are about to finish without problems Beta " 102-MJHARVEY_CRASHNPT-7-25-RND3270_0 " and what I've noticed is a different behavior of the CPU usage, at least Linux | |
| ID: 32951 | Rating: 0 | rate:
| |
|
ExtraTerrestrial Apes Volunteer moderator Volunteer tester Send message Joined: 17 Aug 08 Posts: 2705 Credit: 1,311,122,549 RAC: 0 Level Scientific publications | |
|
Matt, thanks for the explanations some week ago! Going back to my original question, if there was a better way to communicate the number of task restarts instead of "when in doubt take a close look at the task outputs". Zoltan wrote: 2. for the client side: now that you can monitor the GPU temperature, you should throttle the client if the GPU it's running on became too hot (for example above 80°C, and a warning should be present in the stderr.out) I don't think throtteling by GPU-Grid itself would be a good idea. Titans and newer cards with Boost 2 are set for a target temperature of 80°C, which could be changed by the user. Older cards fan control often targets "<90°C" under load. And GPU-Grid would only have one lever available: switching calculations on or off. Which is not efficient at all if a GPU boosts into a high-voltage state (because its boost settings say that's OK), which then triggers an app-internal throttle, pausing computations for a moment.. only to run again into the inefficient high-performance state. In this case it would be much better if the user simply adjusted the temperature target to a good value, so that the card could choose a more efficient lower voltage state which allows sustained load at the target temperature. I agree, though, that a notification system could help users how're unfamiliar with these things. On the other hand: these users would probably not look into the stderr.out either. SK suggests using e-mail or the boinc notification system for this. I'd caution against overusing these - users could easily feel spammed if they read the warning but have reasons to ignore it, yet keep recieving them. Also the notifications are pushed out to all the users machines connected to the project (Or could this be changed? I don't think it's intended for individual messages), which could be badgering. I'm already getting quite a few messages through this system repeatedly which.. ehm, I don't like getting. Let's leave it at that ;) MJH wrote: Unsurprising - it's an inevitable consequence of the way the BOINC client library (which we build into our application) goes about doing suspend -resume[1] I've re-plumbed the whole thing entirely, using a much more reliable method. Sounds like an iprovement which should find its way back into the main branch :) MrS ____________ Scanning for our furry friends since Jan 2002 | |
| ID: 32974 | Rating: 0 | rate:
| |
|
skgiven Volunteer moderator Volunteer tester Send message Joined: 23 Apr 09 Posts: 3968 Credit: 1,995,359,260 RAC: 0 Level Scientific publications | |
|
Communication is a conundrum. Some want it, some don't. In the Boinc Anouncements system (which isn't a per user system) you can opt out; Tools, Options, Notice Reminder Interval (Never). You can also opt out of project messages (again not per user, but the option would be good) or into PM's, so they go straight to email - which I like and would favor in the case of critical announcements (your card fails every WU because, it has memory issues/is too hot/the clocks have dropped/a fan has failed...). | |
| ID: 32979 | Rating: 0 | rate:
| |
|
Carlesa25 Send message Joined: 13 Nov 10 Posts: 328 Credit: 72,619,453 RAC: 0 Level Scientific publications | |
|
Hello: Task Beta MJHARVEY_CRASH2-110-18-25-RND5104_0 is running without problem on Linux (Ubuntu13.10) and the behavior is normal CPU load of 90>99% dedicated to the core. | |
| ID: 33000 | Rating: 0 | rate:
| |
|
ExtraTerrestrial Apes Volunteer moderator Volunteer tester Send message Joined: 17 Aug 08 Posts: 2705 Credit: 1,311,122,549 RAC: 0 Level Scientific publications | |
|
Thanks SK, that's certainly worth considering and could take care of all my concerns against automated messages. An implementation would require some serious work. I think it would be best done in the BOINC main code base, so that projects could benefit from it, but setting it up here could be seen as a demonstration / showcase, which could motivate the main BOINC developers to include it. | |
| ID: 33012 | Rating: 0 | rate:
| |
|
skgiven Volunteer moderator Volunteer tester Send message Joined: 23 Apr 09 Posts: 3968 Credit: 1,995,359,260 RAC: 0 Level Scientific publications | |
|
I would add that it would be nice to know if a WU is taking exceptionally long to complete - say 2 or 3 times what is normal for any given type of WU. | |
| ID: 33059 | Rating: 0 | rate:
| |
|
ExtraTerrestrial Apes Volunteer moderator Volunteer tester Send message Joined: 17 Aug 08 Posts: 2705 Credit: 1,311,122,549 RAC: 0 Level Scientific publications | |
|
We may already have a mechanism for that. I can't remember the exact wording.. time limit exceeded? It mostly triggers unintentionally and results in a straight error, though. | |
| ID: 33071 | Rating: 0 | rate:
| |
|
skgiven Volunteer moderator Volunteer tester Send message Joined: 23 Apr 09 Posts: 3968 Credit: 1,995,359,260 RAC: 0 Level Scientific publications | |
|
The "no heartbeat from client" problem is a bit of an anchor for Boinc; it trawls around the seabeds ripping up reefs - as old-school as my ideas on task timeouts. I presume I experienced the consequences of such murmurs today when my CPU apps failed, compliments of a N* WU. | |
| ID: 33082 | Rating: 0 | rate:
| |
|
MJH Project administrator Project developer Project scientist Send message Joined: 12 Nov 07 Posts: 696 Credit: 27,266,655 RAC: 0 Level Scientific publications | |
Unfortunately not. I agree, it would be really nice to be able to push a message to the BOINC Mangler from the client. I should make a request to DA. Matt | |
| ID: 33871 | Rating: 0 | rate:
| |
|
MJH Project administrator Project developer Project scientist Send message Joined: 12 Nov 07 Posts: 696 Credit: 27,266,655 RAC: 0 Level Scientific publications | |
|
New BETA coming later today. | |
| ID: 33872 | Rating: 0 | rate:
| |
|
Jacob Klein Send message Joined: 11 Oct 08 Posts: 1127 Credit: 1,901,927,545 RAC: 0 Level Scientific publications | |
|
Huzzah! [Thanks, looking forward to testing it!] | |
| ID: 33875 | Rating: 0 | rate:
| |
|
MJH Project administrator Project developer Project scientist Send message Joined: 12 Nov 07 Posts: 696 Credit: 27,266,655 RAC: 0 Level Scientific publications | |
|
815 is live now. | |
| ID: 33876 | Rating: 0 | rate:
| |
|
Richard Haselgrove Send message Joined: 11 Jul 09 Posts: 1626 Credit: 9,295,466,723 RAC: 18,414,230 Level Scientific publications | |
815 is live now. Got one. I think you might have sent out 10-minute jobs with a full-length runtime estimate again. | |
| ID: 33880 | Rating: 0 | rate:
| |
|
Richard Haselgrove Send message Joined: 11 Jul 09 Posts: 1626 Credit: 9,295,466,723 RAC: 18,414,230 Level Scientific publications | |
|
Just had a batch of 'KLAUDE' beta tasks all error with ERROR: file pme.cpp line 85: PME NX too small | |
| ID: 33927 | Rating: 0 | rate:
| |
|
skgiven Volunteer moderator Volunteer tester Send message Joined: 23 Apr 09 Posts: 3968 Credit: 1,995,359,260 RAC: 0 Level Scientific publications | |
|
ditto, all failed in 2 or 3 seconds: | |
| ID: 33928 | Rating: 0 | rate:
| |
|
(retired account) Send message Joined: 22 Dec 11 Posts: 38 Credit: 28,606,255 RAC: 0 Level Scientific publications | |
|
Yep, all thrashed within seconds, no matter if GTX Titan or GT 650M... Hope it helps as I'm only consuming up-/download here and it won't even heat my room. ;) | |
| ID: 33929 | Rating: 0 | rate:
| |
|
(retired account) Send message Joined: 22 Dec 11 Posts: 38 Credit: 28,606,255 RAC: 0 Level Scientific publications | |
Still running, but estimation of remaining time is way off: 18.730%, runtime 01:07:40, remaining time 00:10:18. | |
| ID: 33930 | Rating: 0 | rate:
| |
|
skgiven Volunteer moderator Volunteer tester Send message Joined: 23 Apr 09 Posts: 3968 Credit: 1,995,359,260 RAC: 0 Level Scientific publications | |
The Run Time and % Complete are accurate, so you can estimate the overall time from that; 18.73% in 67 2/3min suggests it will take a total of 6h and 2minutes (+/- a couple) to complete. I have two 8.15 Betas running on a GTX660Ti and a GTX770 (W7) that look like taking 9h 12min and 6h 32min respectively. ____________ FAQ's HOW TO: - Opt out of Beta Tests - Ask for Help | |
| ID: 33931 | Rating: 0 | rate:
| |
|
(retired account) Send message Joined: 22 Dec 11 Posts: 38 Credit: 28,606,255 RAC: 0 Level Scientific publications | |
|
Yes, it took 5 hrs. and 58 min., validated ok. | |
| ID: 33937 | Rating: 0 | rate:
| |
|
Damaraland Send message Joined: 7 Nov 09 Posts: 152 Credit: 16,181,924 RAC: 0 Level Scientific publications | |
|
Not very sure if you still want this info. Maybe you could be more precise. | |
| ID: 33945 | Rating: 0 | rate:
| |
|
Richard Haselgrove Send message Joined: 11 Jul 09 Posts: 1626 Credit: 9,295,466,723 RAC: 18,414,230 Level Scientific publications | |
|
I've finally had a crash while beta tasks were running ;) | |
| ID: 33949 | Rating: 0 | rate:
| |
|
Richard Haselgrove Send message Joined: 11 Jul 09 Posts: 1626 Credit: 9,295,466,723 RAC: 18,414,230 Level Scientific publications | |
|
OK, now I'm awake, I've checked the logs for those two tasks, and the sequence of events is as I surmised. 20-Nov-2013 16:50:15 [---] NOTICES::write: sending notice 6 That was the host crash interval 20-Nov-2013 16:43:15 [GPUGRID] Starting task 1-KLAUDE_6429-1-2-RND1937_0 using acemdbeta version 815 (cuda55) in slot 7 That task crashed, but in a 'benign' way (it didn't take the driver down with it) 20-Nov-2013 16:35:47 [GPUGRID] Starting task 95-KLAUDE_6429-0-2-RND2489_1 using acemdbeta version 815 (cuda55) in slot 3 And that task validated. | |
| ID: 33952 | Rating: 0 | rate:
| |
|
Damaraland Send message Joined: 7 Nov 09 Posts: 152 Credit: 16,181,924 RAC: 0 Level Scientific publications | |
|
This unit 3-KLAUDE_6429-0-2-RND6465 worked fine for me after it failed on 6 computers before | |
| ID: 33999 | Rating: 0 | rate:
| |
|
nanoprobe Send message Joined: 26 Feb 12 Posts: 184 Credit: 222,376,233 RAC: 0 Level Scientific publications | |
|
All KLAUDE failed here after 2 seconds. Found this in the BOINC event log. | |
| ID: 34005 | Rating: 0 | rate:
| |
|
Bedrich Hajek Send message Joined: 28 Mar 09 Posts: 486 Credit: 11,351,780,632 RAC: 9,362,860 Level Scientific publications | |
All KLAUDE failed here after 2 seconds. Found this in the BOINC event log. Same here! | |
| ID: 34006 | Rating: 0 | rate:
| |
|
Dagorath Send message Joined: 16 Mar 11 Posts: 509 Credit: 179,005,236 RAC: 0 Level Scientific publications | |
|
I had several KLAUDE tasks fail after I configured my system to crunch 2 GPUgrid tasks simultaneously on my single 660Ti. They failed ~2 secs after starting but were reported as "error while computing" and did not verify. | |
| ID: 34008 | Rating: 0 | rate:
| |
|
Richard Haselgrove Send message Joined: 11 Jul 09 Posts: 1626 Credit: 9,295,466,723 RAC: 18,414,230 Level Scientific publications | |
|
It looks as if there was a bad batch of KLAUDE workunits overnight, all of which failed with ERROR: file mdioload.cpp line 209: Error reading parmtop file That includes yours, Dagorath - I don't think you can draw a conclusion that running two at a time had anything to do with the failures. | |
| ID: 34009 | Rating: 0 | rate:
| |
|
(retired account) Send message Joined: 22 Dec 11 Posts: 38 Credit: 28,606,255 RAC: 0 Level Scientific publications | |
|
Yes, same here, lots of errors over night. Luckily enough, the Titan already hit a max.-per-day-limit of 15. | |
| ID: 34010 | Rating: 0 | rate:
| |
|
skgiven Volunteer moderator Volunteer tester Send message Joined: 23 Apr 09 Posts: 3968 Credit: 1,995,359,260 RAC: 0 Level Scientific publications | |
|
Yeah, bad batch. | |
| ID: 34011 | Rating: 0 | rate:
| |
|
Dagorath Send message Joined: 16 Mar 11 Posts: 509 Credit: 179,005,236 RAC: 0 Level Scientific publications | |
It looks as if there was a bad batch of KLAUDE workunits overnight, all of which failed with That's good to know, thanks. ____________ BOINC <<--- credit whores, pedants, alien hunters | |
| ID: 34012 | Rating: 0 | rate:
| |
|
MJH Project administrator Project developer Project scientist Send message Joined: 12 Nov 07 Posts: 696 Credit: 27,266,655 RAC: 0 Level Scientific publications | |
|
Yes, my fault. I put out some broken WUs on the beta channel. | |
| ID: 34014 | Rating: 0 | rate:
| |
|
And not only KLAUDE, a trypsin has result in yet another fatal cuda driver error and downclocked even to 1/3th of the normal clock speed. I know trypsin is nasty stuff as its purpose is to "break down" molecules, but that it can also "break down" a GPU-clock is new for me :) | |
| ID: 34015 | Rating: 0 | rate:
| |
|
skgiven Volunteer moderator Volunteer tester Send message Joined: 23 Apr 09 Posts: 3968 Credit: 1,995,359,260 RAC: 0 Level Scientific publications | |
|
The Trp tasks are not part of the bad KLAUDE batch: | |
| ID: 34016 | Rating: 0 | rate:
| |
|
Bedrich Hajek Send message Joined: 28 Mar 09 Posts: 486 Credit: 11,351,780,632 RAC: 9,362,860 Level Scientific publications | |
|
The latest NOELIA_RCDOSequ betas run fine, but they do down clock the video card speed to 914 Mhz, not the 1019 Mhz speed as recorded on the Stderr output below. Notice the temperature readings, they are in the 50's, not the 60's to low 70's when I run the long tasks. This is true for both windows xp and 7. Below is a typical output for all these betas. The cards do return to normal speed when they run the long runs. | |
| ID: 34036 | Rating: 0 | rate:
| |
|
Richard Haselgrove Send message Joined: 11 Jul 09 Posts: 1626 Credit: 9,295,466,723 RAC: 18,414,230 Level Scientific publications | |
|
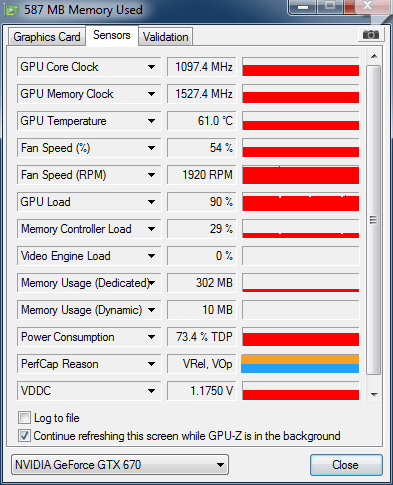
I see the latest GPU-Z gives a reason for performance capping: | |
| ID: 34037 | Rating: 0 | rate:
| |
|
Snow Crash Send message Joined: 4 Apr 09 Posts: 450 Credit: 539,316,349 RAC: 0 Level Scientific publications | |
I see the latest GPU-Z gives a reason for performance capping: <ot> I have GPUZ 0.7.4 (which says it is the latest version) and I do not see that entry (I have a 670 also), is that a beta version and can you provide a link to where you got it from? </ot> ____________ Thanks - Steve | |
| ID: 34046 | Rating: 0 | rate:
| |
|
skgiven Volunteer moderator Volunteer tester Send message Joined: 23 Apr 09 Posts: 3968 Credit: 1,995,359,260 RAC: 0 Level Scientific publications | |
|
GPU-Z has been showing this for months. I'm still using 0.7.3 and it shows it, as did the previous version, and probably the one before that. Thought I posted about this several months ago?!? Anyway, its a useful tool but only works on Windows. My GTX660Ti (which is hanging out of the case against a wall complements of a riser) is limited by V.Rel and V0p (Reliability Voltage and Operating Voltage, respectively). My GTX660 is limited by Power and Reliability Voltage. My GTX770 is limited by Reliability Voltage and Operating Voltage. All in the same system. Of note is that only the GTX660 is limited by Power! | |
| ID: 34047 | Rating: 0 | rate:
| |
|
Yes I have that seen already from GPU-Z in previous versions just as skgiven says. | |
| ID: 34048 | Rating: 0 | rate:
| |
|
ExtraTerrestrial Apes Volunteer moderator Volunteer tester Send message Joined: 17 Aug 08 Posts: 2705 Credit: 1,311,122,549 RAC: 0 Level Scientific publications | |
|
If GPU-Z reports "VRel., VOp" as throttling reason this actually means the card is running full throttle and has reached the highest boost bin. Since it would need higher voltage for the next bin, it's reported as being throttled by voltage. Unless the power limit is set tightly or cooling is poor, then this should be the default state a GPU-Grid-crunching Kepler is in. Bedrich wrote: but they do down clock the video card speed to 914 Mhz, not the 1019 Mhz speed as recorded on the Stderr output below. Notice the temperature readings, they are in the 50's, not the 60's to low 70's when I run the long tasks. This sounds like the GPU utilization was low, in which case the driver doesn't see it necessary to push to full boost. In this case GPU-Z reports "Util" as throttle reason, for "GPU utilization too low". This mostly happens with small / short WUs. Those are also the ones where running 2 concurrent WUs actually provides some throughput gains. MrS ____________ Scanning for our furry friends since Jan 2002 | |
| ID: 34123 | Rating: 0 | rate:
| |

Message boards : News : acemdbeta application - discussion